 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attack on Deep Learning-Based Splice Localization
Apr 17, 2020

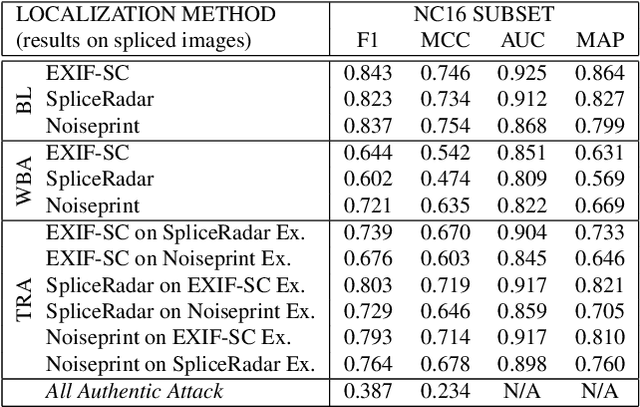
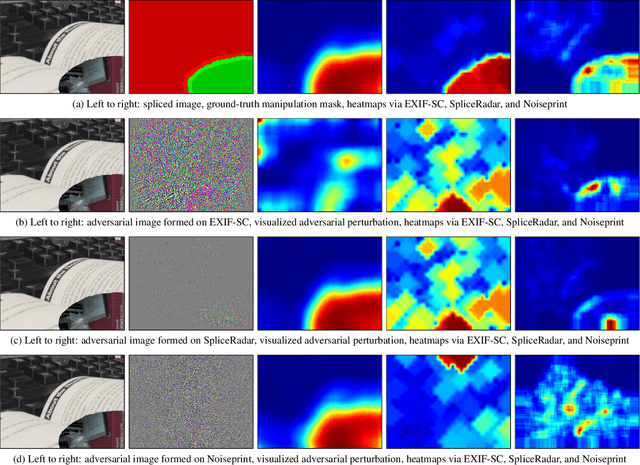
Regarding image forensics, researchers have proposed various approaches to detect and/or localize manipulations, such as splices. Recent best performing image-forensics algorithms greatly benefit from the application of deep learning, but such tools can be vulnerable to adversarial attacks. Due to the fact that most of the proposed adversarial example generation techniques can be used only on end-to-end classifiers, the adversarial robustness of image-forensics methods that utilize deep learning only for feature extraction has not been studied yet. Using a novel algorithm capable of directly adjusting the underlying representations of patches we demonstrate on three non end-to-end deep learning-based splice localization tools that hiding manipulations of images is feasible via adversarial attacks. While the tested image-forensics methods, EXIF-SC, SpliceRadar, and Noiseprint, rely on feature extractors that were trained on different surrogate tasks, we find that the formed adversarial perturbations can be transferable among them regarding the deterioration of their localization performance.
Improved Adversarial Robustness by Reducing Open Space Risk via Tent Activations
Aug 07, 2019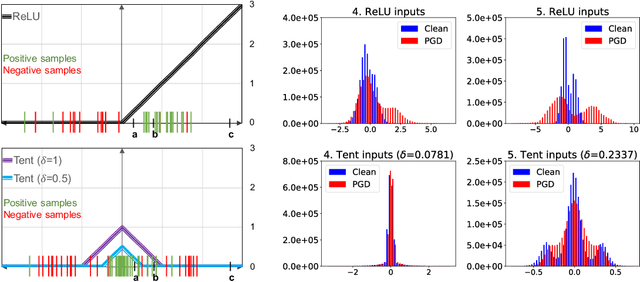
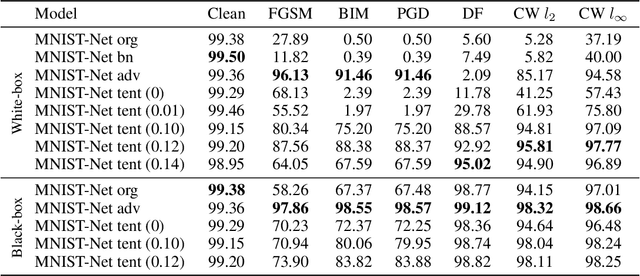
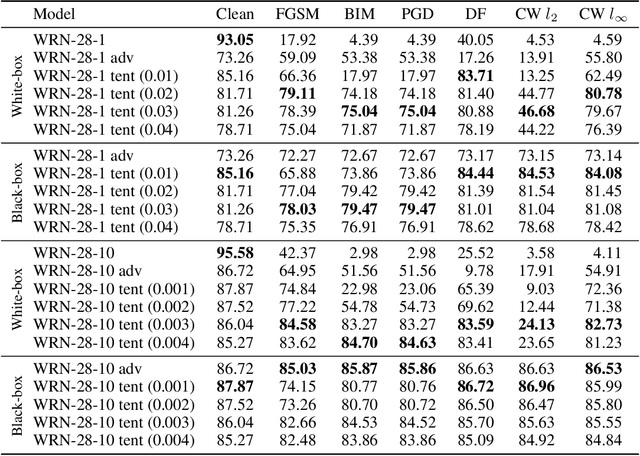
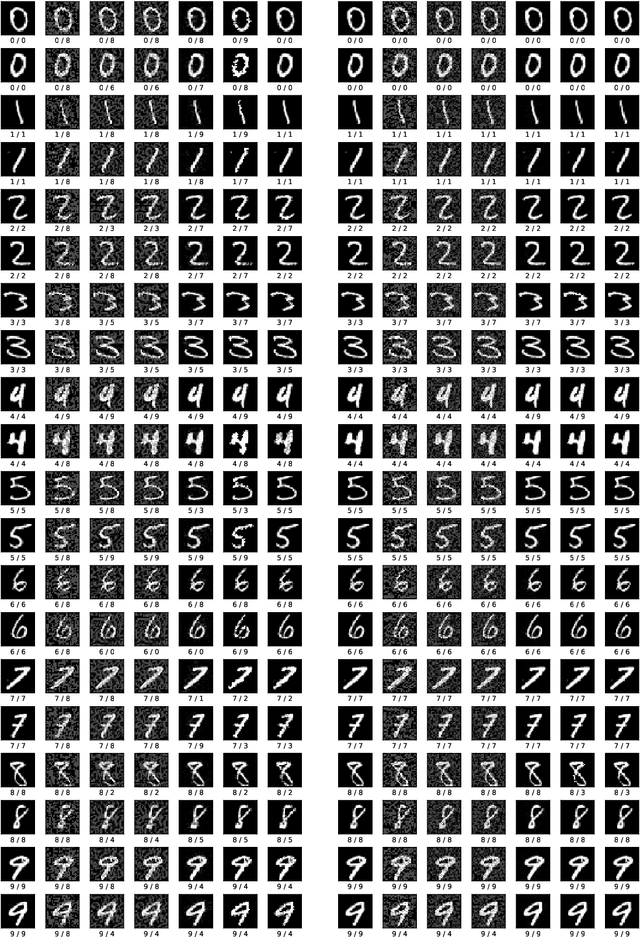
Adversarial examples contain small perturbations that can remain imperceptible to human observers but alter the behavior of even the best performing deep learning models and yield incorrect outputs. Since their discovery, adversarial examples have drawn significant attention in machine learning: researchers try to reveal the reasons for their existence and improve the robustness of machine learning models to adversarial perturbations. The state-of-the-art defense is the computationally expensive and very time consuming adversarial training via projected gradient descent (PGD). We hypothesize that adversarial attacks exploit the open space risk of classic monotonic activation functions. This paper introduces the tent activation function with bounded open space risk and shows that tents make deep learning models more robust to adversarial attacks. We demonstrate on the MNIST dataset that a classifier with tents yields an average accuracy of 91.8% against six white-box adversarial attacks, which is more than 15 percentage points above the state of the art. On the CIFAR-10 dataset, our approach improves the average accuracy against the six white-box adversarial attacks to 73.5% from 41.8% achieved by adversarial training via PGD.
LOTS about Attacking Deep Features
May 31, 2018
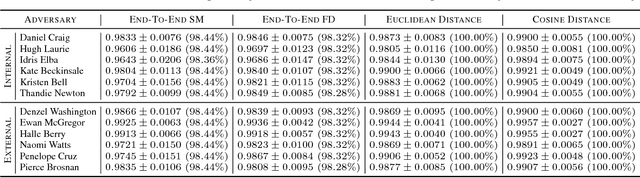
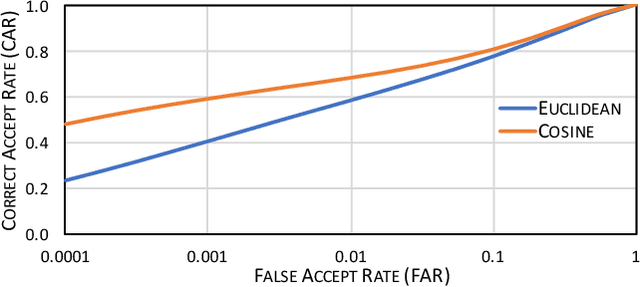

Deep neural networks provide state-of-the-art performance on various tasks and are, therefore, widely used in real world applications. DNNs are becoming frequently utilized in biometrics for extracting deep features, which can be used in recognition systems for enrolling and recognizing new individuals. It was revealed that deep neural networks suffer from a fundamental problem, namely, they can unexpectedly misclassify examples formed by slightly perturbing correctly recognized inputs. Various approaches have been developed for generating these so-called adversarial examples, but they aim at attacking end-to-end networks. For biometrics, it is natural to ask whether systems using deep features are immune to or, at least, more resilient to attacks than end-to-end networks. In this paper, we introduce a general technique called the layerwise origin-target synthesis (LOTS) that can be efficiently used to form adversarial examples that mimic the deep features of the target. We analyze and compare the adversarial robustness of the end-to-end VGG Face network with systems that use Euclidean or cosine distance between gallery templates and extracted deep features. We demonstrate that iterative LOTS is very effective and show that systems utilizing deep features are easier to attack than the end-to-end network.
Facial Attributes: Accuracy and Adversarial Robustness
Apr 20, 2018



Facial attributes, emerging soft biometrics, must be automatically and reliably extracted from images in order to be usable in stand-alone systems. While recent methods extract facial attributes using deep neural networks (DNNs) trained on labeled facial attribute data, the robustness of deep attribute representations has not been evaluated. In this paper, we examine the representational stability of several approaches that recently advanced the state of the art on the CelebA benchmark by generating adversarial examples formed by adding small, non-random perturbations to inputs yielding altered classifications. We show that our fast flipping attribute (FFA) technique generates more adversarial examples than traditional algorithms, and that the adversarial robustness of DNNs varies highly between facial attributes. We also test the correlation of facial attributes and find that only for related attributes do the formed adversarial perturbations change the classification of others. Finally, we introduce the concept of natural adversarial samples, i.e., misclassified images where predictions can be corrected via small perturbations. We demonstrate that natural adversarial samples commonly occur and show that many of these images remain misclassified even with additional training epochs, even though their correct classification may require only a small adjustment to network parameters.
* arXiv admin note: text overlap with arXiv:1605.05411
Towards Robust Deep Neural Networks with BANG
Jan 30, 2018


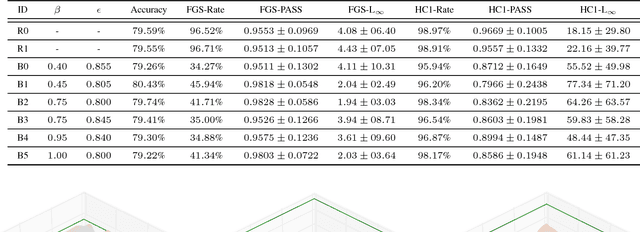
Machine learning models, including state-of-the-art deep neural networks, are vulnerable to small perturbations that cause unexpected classification errors. This unexpected lack of robustness raises fundamental questions about their generalization properties and poses a serious concern for practical deployments. As such perturbations can remain imperceptible - the formed adversarial examples demonstrate an inherent inconsistency between vulnerable machine learning models and human perception - some prior work casts this problem as a security issue. Despite the significance of the discovered instabilities and ensuing research, their cause is not well understood and no effective method has been developed to address the problem. In this paper, we present a novel theory to explain why this unpleasant phenomenon exists in deep neural networks. Based on that theory, we introduce a simple, efficient, and effective training approach, Batch Adjusted Network Gradients (BANG), which significantly improves the robustness of machine learning models. While the BANG technique does not rely on any form of data augmentation or the utilization of adversarial images for training, the resultant classifiers are more resistant to adversarial perturbations while maintaining or even enhancing the overall classification performance.
Adversarial Robustness: Softmax versus Openmax
Aug 05, 2017
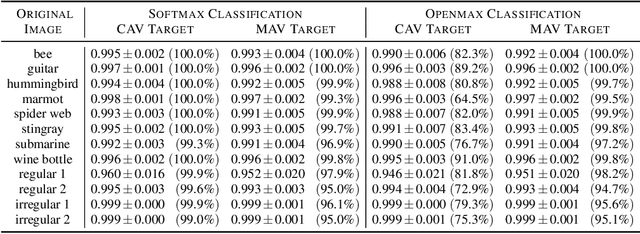

Deep neural networks (DNNs) provide state-of-the-art results on various tasks and are widely used in real world applications. However, it was discovered that machine learning models, including the best performing DNNs, suffer from a fundamental problem: they can unexpectedly and confidently misclassify examples formed by slightly perturbing otherwise correctly recognized inputs. Various approaches have been developed for efficiently generating these so-called adversarial examples, but those mostly rely on ascending the gradient of loss. In this paper, we introduce the novel logits optimized targeting system (LOTS) to directly manipulate deep features captured at the penultimate layer. Using LOTS, we analyze and compare the adversarial robustness of DNNs using the traditional Softmax layer with Openmax, which was designed to provide open set recognition by defining classes derived from deep representations, and is claimed to be more robust to adversarial perturbations. We demonstrate that Openmax provides less vulnerable systems than Softmax to traditional attacks, however, we show that it can be equally susceptible to more sophisticated adversarial generation techniques that directly work on deep representations.
AFFACT - Alignment-Free Facial Attribute Classification Technique
Aug 04, 2017



Facial attributes are soft-biometrics that allow limiting the search space, e.g., by rejecting identities with non-matching facial characteristics such as nose sizes or eyebrow shapes. In this paper, we investigate how the latest versions of deep convolutional neural networks, ResNets, perform on the facial attribute classification task. We test two loss functions: the sigmoid cross-entropy loss and the Euclidean loss, and find that for classification performance there is little difference between these two. Using an ensemble of three ResNets, we obtain the new state-of-the-art facial attribute classification error of 8.00% on the aligned images of the CelebA dataset. More significantly, we introduce the Alignment-Free Facial Attribute Classification Technique (AFFACT), a data augmentation technique that allows a network to classify facial attributes without requiring alignment beyond detected face bounding boxes. To our best knowledge, we are the first to report similar accuracy when using only the detected bounding boxes -- rather than requiring alignment based on automatically detected facial landmarks -- and who can improve classification accuracy with rotating and scaling test images. We show that this approach outperforms the CelebA baseline on unaligned images with a relative improvement of 36.8%.
A Survey of Stealth Malware: Attacks, Mitigation Measures, and Steps Toward Autonomous Open World Solutions
Dec 02, 2016



As our professional, social, and financial existences become increasingly digitized and as our government, healthcare, and military infrastructures rely more on computer technologies, they present larger and more lucrative targets for malware. Stealth malware in particular poses an increased threat because it is specifically designed to evade detection mechanisms, spreading dormant, in the wild for extended periods of time, gathering sensitive information or positioning itself for a high-impact zero-day attack. Policing the growing attack surface requires the development of efficient anti-malware solutions with improved generalization to detect novel types of malware and resolve these occurrences with as little burden on human experts as possible. In this paper, we survey malicious stealth technologies as well as existing solutions for detecting and categorizing these countermeasures autonomously. While machine learning offers promising potential for increasingly autonomous solutions with improved generalization to new malware types, both at the network level and at the host level, our findings suggest that several flawed assumptions inherent to most recognition algorithms prevent a direct mapping between the stealth malware recognition problem and a machine learning solution. The most notable of these flawed assumptions is the closed world assumption: that no sample belonging to a class outside of a static training set will appear at query time. We present a formalized adaptive open world framework for stealth malware recognition and relate it mathematically to research from other machine learning domains.
Are Accuracy and Robustness Correlated?
Dec 01, 2016
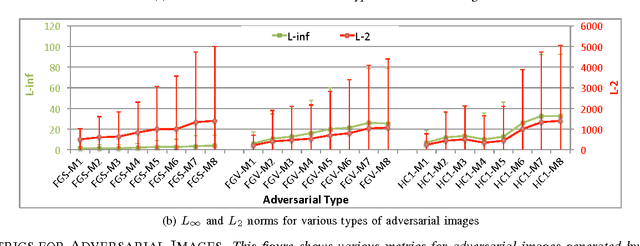
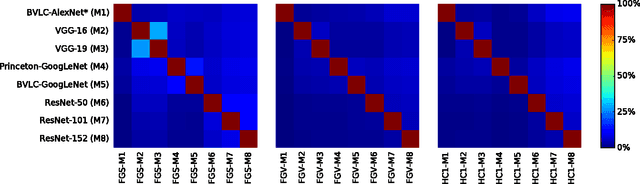
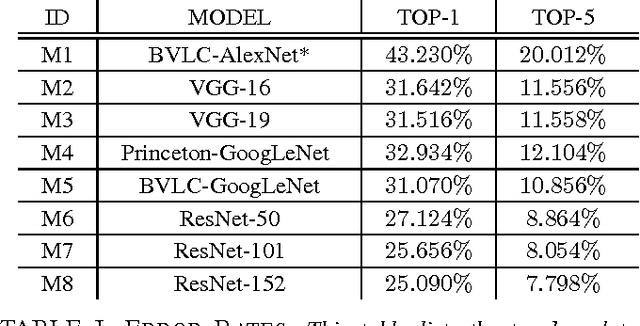
Machine learning models are vulnerable to adversarial examples formed by applying small carefully chosen perturbations to inputs that cause unexpected classification errors. In this paper, we perform experiments on various adversarial example generation approaches with multiple deep convolutional neural networks including Residual Networks, the best performing models on ImageNet Large-Scale Visual Recognition Challenge 2015. We compare the adversarial example generation techniques with respect to the quality of the produced images, and measure the robustness of the tested machine learning models to adversarial examples. Finally, we conduct large-scale experiments on cross-model adversarial portability. We find that adversarial examples are mostly transferable across similar network topologies, and we demonstrate that better machine learning models are less vulnerable to adversarial examples.
Assessing Threat of Adversarial Examples on Deep Neural Networks
Oct 13, 2016



Deep neural networks are facing a potential security threat from adversarial examples, inputs that look normal but cause an incorrect classification by the deep neural network. For example, the proposed threat could result in hand-written digits on a scanned check being incorrectly classified but looking normal when humans see them. This research assesses the extent to which adversarial examples pose a security threat, when one considers the normal image acquisition process. This process is mimicked by simulating the transformations that normally occur in acquiring the image in a real world application, such as using a scanner to acquire digits for a check amount or using a camera in an autonomous car. These small transformations negate the effect of the carefully crafted perturbations of adversarial examples, resulting in a correct classification by the deep neural network. Thus just acquiring the image decreases the potential impact of the proposed security threat. We also show that the already widely used process of averaging over multiple crops neutralizes most adversarial examples. Normal preprocessing, such as text binarization, almost completely neutralizes adversarial examples. This is the first paper to show that for text driven classification, adversarial examples are an academic curiosity, not a security threat.