 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Adversarial Robustness by Reducing Open Space Risk via Tent Activations
Paper and Code
Aug 07, 2019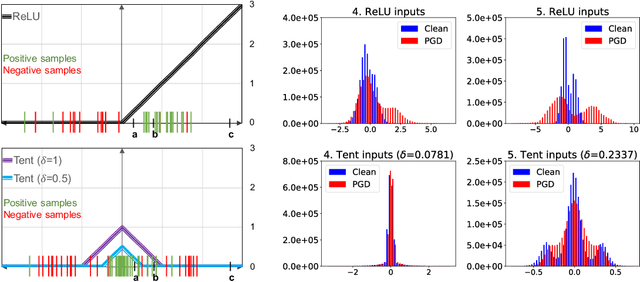
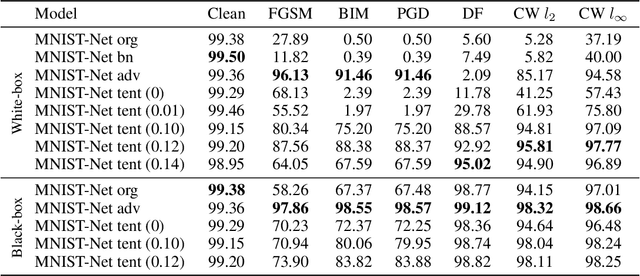
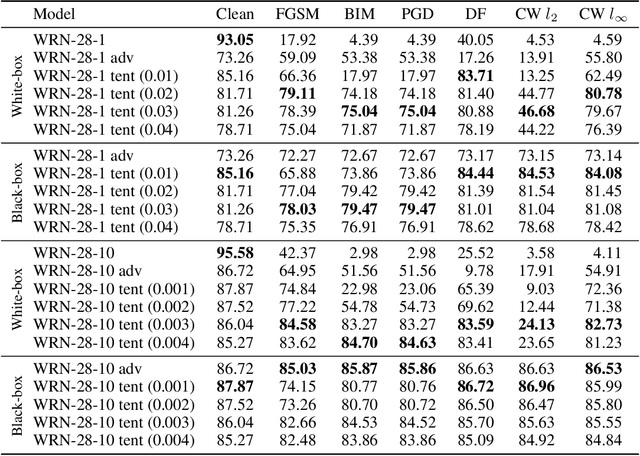
Adversarial examples contain small perturbations that can remain imperceptible to human observers but alter the behavior of even the best performing deep learning models and yield incorrect outputs. Since their discovery, adversarial examples have drawn significant attention in machine learning: researchers try to reveal the reasons for their existence and improve the robustness of machine learning models to adversarial perturbations. The state-of-the-art defense is the computationally expensive and very time consuming adversarial training via projected gradient descent (PGD). We hypothesize that adversarial attacks exploit the open space risk of classic monotonic activation functions. This paper introduces the tent activation function with bounded open space risk and shows that tents make deep learning models more robust to adversarial attacks. We demonstrate on the MNIST dataset that a classifier with tents yields an average accuracy of 91.8% against six white-box adversarial attacks, which is more than 15 percentage points above the state of the art. On the CIFAR-10 dataset, our approach improves the average accuracy against the six white-box adversarial attacks to 73.5% from 41.8% achieved by adversarial training via PGD.