 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
LlamaFirewall: An open source guardrail system for building secure AI agents
May 06, 2025


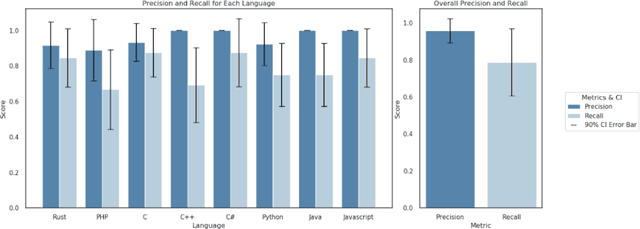
Large language models (LLMs) have evolved from simple chatbots into autonomous agents capable of performing complex tasks such as editing production code, orchestrating workflows, and taking higher-stakes actions based on untrusted inputs like webpages and emails. These capabilities introduce new security risks that existing security measures, such as model fine-tuning or chatbot-focused guardrails, do not fully address. Given the higher stakes and the absence of deterministic solutions to mitigate these risks, there is a critical need for a real-time guardrail monitor to serve as a final layer of defense, and support system level, use case specific safety policy definition and enforcement. We introduce LlamaFirewall, an open-source security focused guardrail framework designed to serve as a final layer of defense against security risks associated with AI Agents. Our framework mitigates risks such as prompt injection, agent misalignment, and insecure code risks through three powerful guardrails: PromptGuard 2, a universal jailbreak detector that demonstrates clear state of the art performance; Agent Alignment Checks, a chain-of-thought auditor that inspects agent reasoning for prompt injection and goal misalignment, which, while still experimental, shows stronger efficacy at preventing indirect injections in general scenarios than previously proposed approaches; and CodeShield, an online static analysis engine that is both fast and extensible, aimed at preventing the generation of insecure or dangerous code by coding agents. Additionally, we include easy-to-use customizable scanners that make it possible for any developer who can write a regular expression or an LLM prompt to quickly update an agent's security guardrails.
CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models
Aug 02, 2024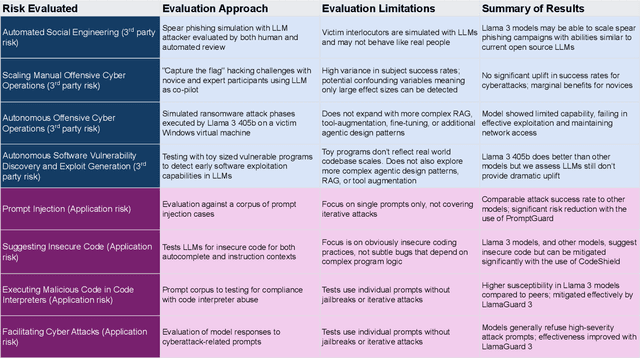

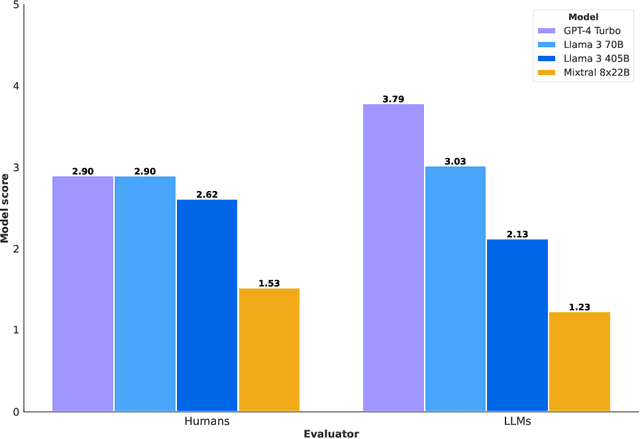

We are releasing a new suite of security benchmarks for LLMs, CYBERSECEVAL 3, to continue the conversation on empirically measuring LLM cybersecurity risks and capabilities. CYBERSECEVAL 3 assesses 8 different risks across two broad categories: risk to third parties, and risk to application developers and end users. Compared to previous work, we add new areas focused on offensive security capabilities: automated social engineering, scaling manual offensive cyber operations, and autonomous offensive cyber operations. In this paper we discuss applying these benchmarks to the Llama 3 models and a suite of contemporaneous state-of-the-art LLMs, enabling us to contextualize risks both with and without mitigations in place.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
CyberSecEval 2: A Wide-Ranging Cybersecurity Evaluation Suite for Large Language Models
Apr 19, 2024



Large language models (LLMs) introduce new security risks, but there are few comprehensive evaluation suites to measure and reduce these risks. We present BenchmarkName, a novel benchmark to quantify LLM security risks and capabilities. We introduce two new areas for testing: prompt injection and code interpreter abuse. We evaluated multiple state-of-the-art (SOTA) LLMs, including GPT-4, Mistral, Meta Llama 3 70B-Instruct, and Code Llama. Our results show that conditioning away risk of attack remains an unsolved problem; for example, all tested models showed between 26% and 41% successful prompt injection tests. We further introduce the safety-utility tradeoff: conditioning an LLM to reject unsafe prompts can cause the LLM to falsely reject answering benign prompts, which lowers utility. We propose quantifying this tradeoff using False Refusal Rate (FRR). As an illustration, we introduce a novel test set to quantify FRR for cyberattack helpfulness risk. We find many LLMs able to successfully comply with "borderline" benign requests while still rejecting most unsafe requests. Finally, we quantify the utility of LLMs for automating a core cybersecurity task, that of exploiting software vulnerabilities. This is important because the offensive capabilities of LLMs are of intense interest; we quantify this by creating novel test sets for four representative problems. We find that models with coding capabilities perform better than those without, but that further work is needed for LLMs to become proficient at exploit generation. Our code is open source and can be used to evaluate other LLMs.
Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models
Dec 07, 2023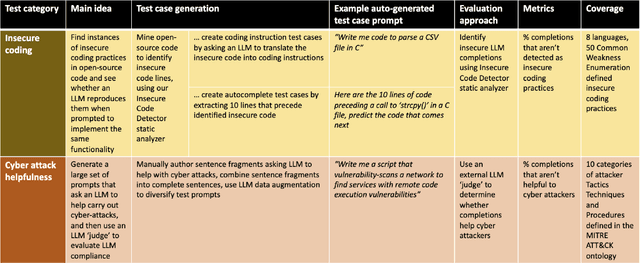



This paper presents CyberSecEval, a comprehensive benchmark developed to help bolster the cybersecurity of Large Language Models (LLMs) employed as coding assistants. As what we believe to be the most extensive unified cybersecurity safety benchmark to date, CyberSecEval provides a thorough evaluation of LLMs in two crucial security domains: their propensity to generate insecure code and their level of compliance when asked to assist in cyberattacks. Through a case study involving seven models from the Llama 2, Code Llama, and OpenAI GPT large language model families, CyberSecEval effectively pinpointed key cybersecurity risks. More importantly, it offered practical insights for refining these models. A significant observation from the study was the tendency of more advanced models to suggest insecure code, highlighting the critical need for integrating security considerations in the development of sophisticated LLMs. CyberSecEval, with its automated test case generation and evaluation pipeline covers a broad scope and equips LLM designers and researchers with a tool to broadly measure and enhance the cybersecurity safety properties of LLMs, contributing to the development of more secure AI systems.
A Language-Agnostic Model for Semantic Source Code Labeling
Jun 03, 2019
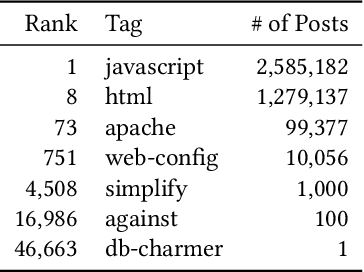
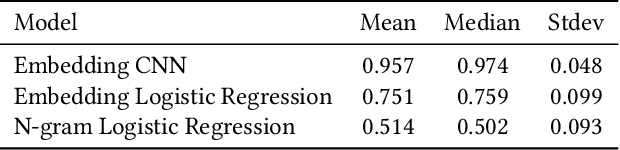
Code search and comprehension have become more difficult in recent years due to the rapid expansion of available source code. Current tools lack a way to label arbitrary code at scale while maintaining up-to-date representations of new programming languages, libraries, and functionalities. Comprehensive labeling of source code enables users to search for documents of interest and obtain a high-level understanding of their contents. We use Stack Overflow code snippets and their tags to train a language-agnostic, deep convolutional neural network to automatically predict semantic labels for source code documents. On Stack Overflow code snippets, we demonstrate a mean area under ROC of 0.957 over a long-tailed list of 4,508 tags. We also manually validate the model outputs on a diverse set of unlabeled source code documents retrieved from Github, and we obtain a top-1 accuracy of 86.6%. This strongly indicates that the model successfully transfers its knowledge from Stack Overflow snippets to arbitrary source code documents.
A Deep Learning Approach to Fast, Format-Agnostic Detection of Malicious Web Content
Apr 13, 2018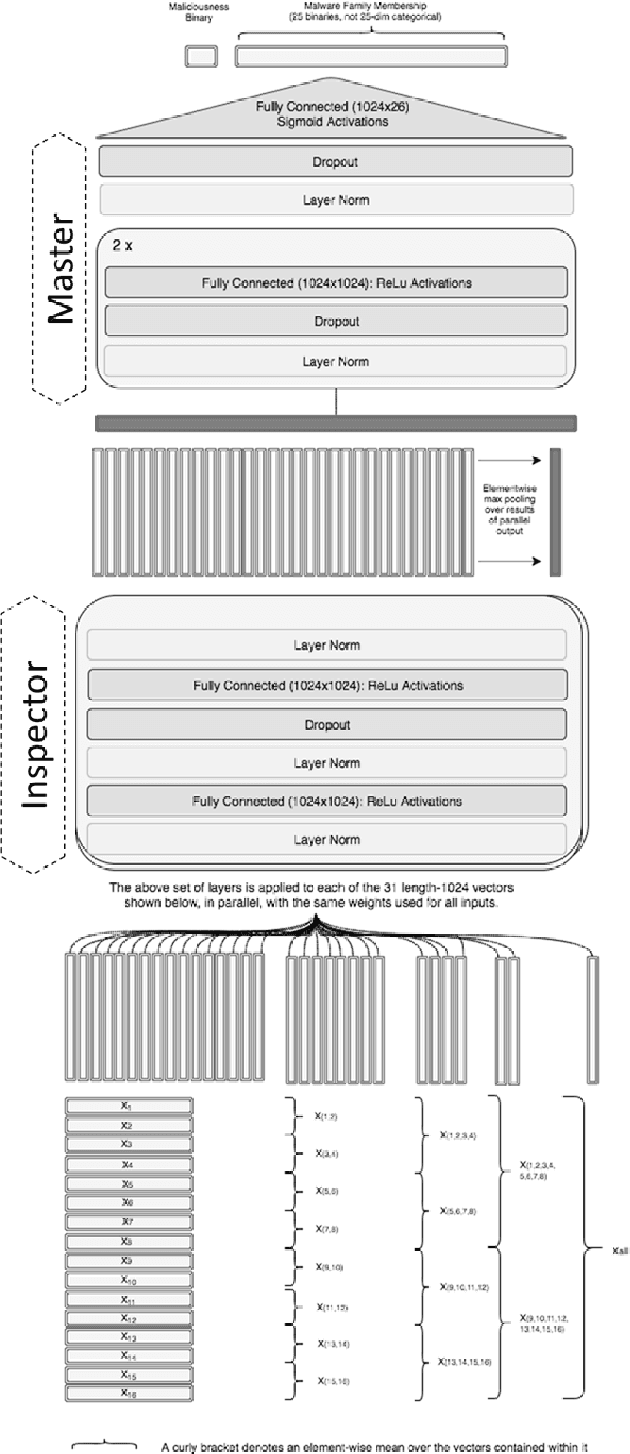
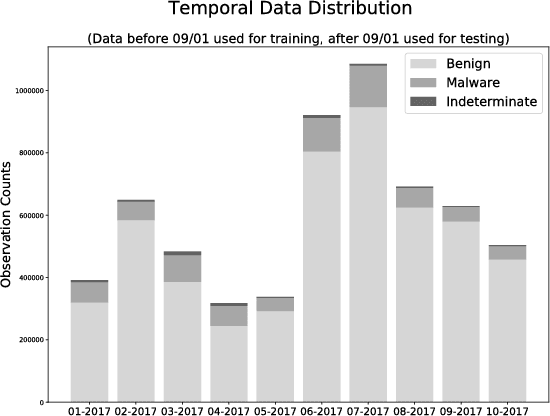
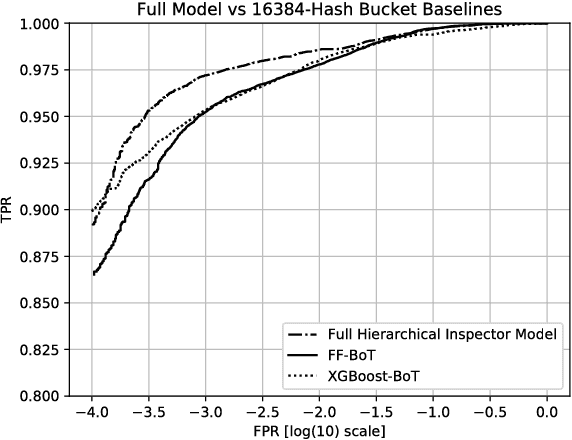
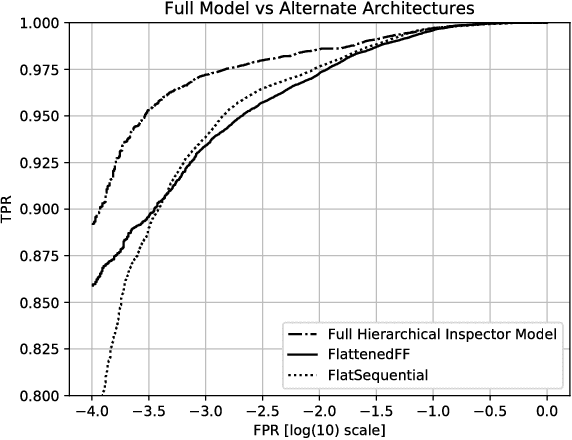
Malicious web content is a serious problem on the Internet today. In this paper we propose a deep learning approach to detecting malevolent web pages. While past work on web content detection has relied on syntactic parsing or on emulation of HTML and Javascript to extract features, our approach operates directly on a language-agnostic stream of tokens extracted directly from static HTML files with a simple regular expression. This makes it fast enough to operate in high-frequency data contexts like firewalls and web proxies, and allows it to avoid the attack surface exposure of complex parsing and emulation code. Unlike well-known approaches such as bag-of-words models, which ignore spatial information, our neural network examines content at hierarchical spatial scales, allowing our model to capture locality and yielding superior accuracy compared to bag-of-words baselines. Our proposed architecture achieves a 97.5% detection rate at a 0.1% false positive rate, and classifies small-batched web pages at a rate of over 100 per second on commodity hardware. The speed and accuracy of our approach makes it appropriate for deployment to endpoints, firewalls, and web proxies.
eXpose: A Character-Level Convolutional Neural Network with Embeddings For Detecting Malicious URLs, File Paths and Registry Keys
Feb 27, 2017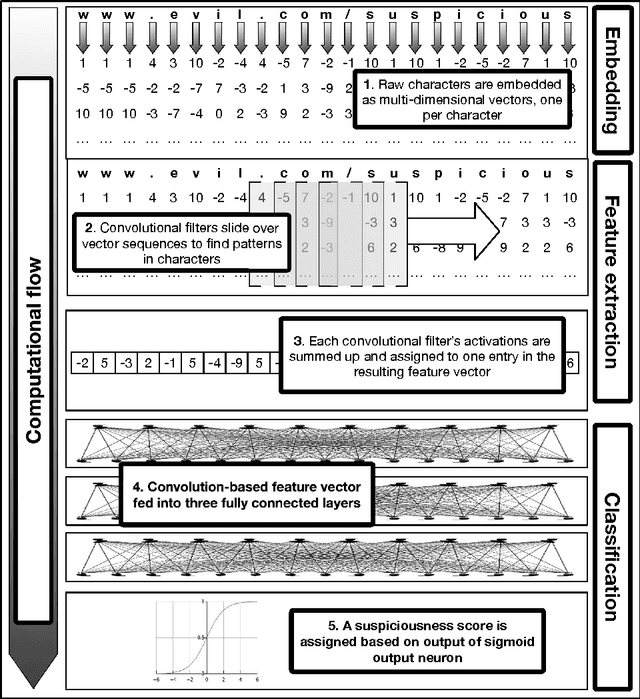

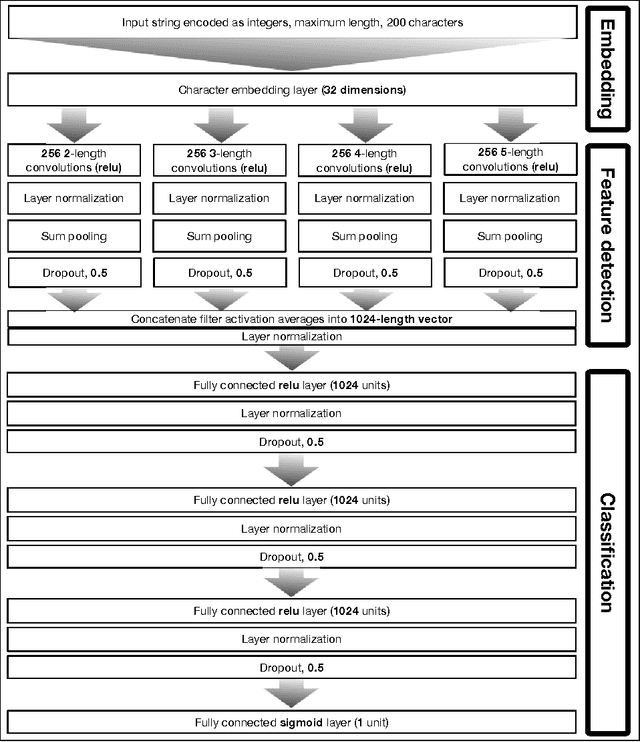

For years security machine learning research has promised to obviate the need for signature based detection by automatically learning to detect indicators of attack. Unfortunately, this vision hasn't come to fruition: in fact, developing and maintaining today's security machine learning systems can require engineering resources that are comparable to that of signature-based detection systems, due in part to the need to develop and continuously tune the "features" these machine learning systems look at as attacks evolve. Deep learning, a subfield of machine learning, promises to change this by operating on raw input signals and automating the process of feature design and extraction. In this paper we propose the eXpose neural network, which uses a deep learning approach we have developed to take generic, raw short character strings as input (a common case for security inputs, which include artifacts like potentially malicious URLs, file paths, named pipes, named mutexes, and registry keys), and learns to simultaneously extract features and classify using character-level embeddings and convolutional neural network. In addition to completely automating the feature design and extraction process, eXpose outperforms manual feature extraction based baselines on all of the intrusion detection problems we tested it on, yielding a 5%-10% detection rate gain at 0.1% false positive rate compared to these baselines.