 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical Segmentation of Source Code
Jul 18, 2019
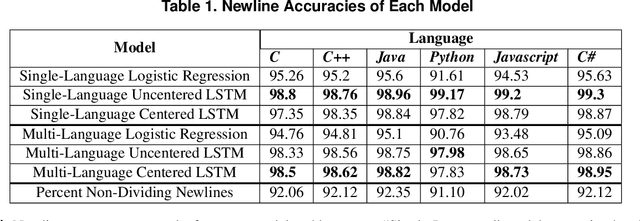
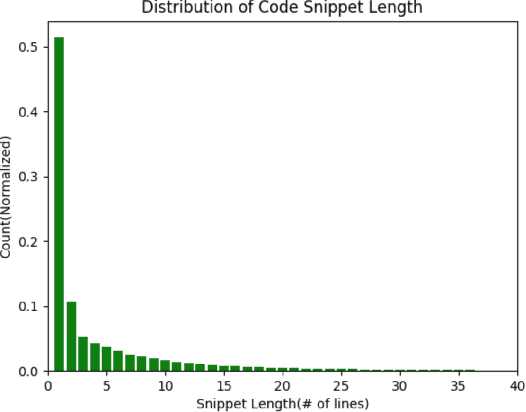

Many software analysis methods have come to rely on machine learning approaches. Code segmentation - the process of decomposing source code into meaningful blocks - can augment these methods by featurizing code, reducing noise, and limiting the problem space. Traditionally, code segmentation has been done using syntactic cues; current approaches do not intentionally capture logical content. We develop a novel deep learning approach to generate logical code segments regardless of the language or syntactic correctness of the code. Due to the lack of logically segmented source code, we introduce a unique data set construction technique to approximate ground truth for logically segmented code. Logical code segmentation can improve tasks such as automatically commenting code, detecting software vulnerabilities, repairing bugs, labeling code functionality, and synthesizing new code.
A Language-Agnostic Model for Semantic Source Code Labeling
Jun 03, 2019
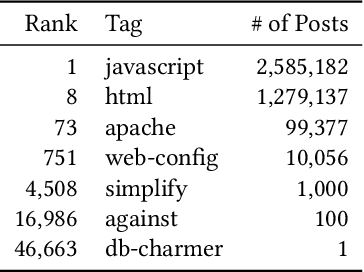
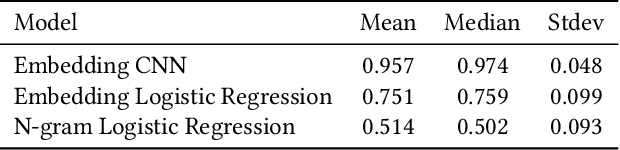
Code search and comprehension have become more difficult in recent years due to the rapid expansion of available source code. Current tools lack a way to label arbitrary code at scale while maintaining up-to-date representations of new programming languages, libraries, and functionalities. Comprehensive labeling of source code enables users to search for documents of interest and obtain a high-level understanding of their contents. We use Stack Overflow code snippets and their tags to train a language-agnostic, deep convolutional neural network to automatically predict semantic labels for source code documents. On Stack Overflow code snippets, we demonstrate a mean area under ROC of 0.957 over a long-tailed list of 4,508 tags. We also manually validate the model outputs on a diverse set of unlabeled source code documents retrieved from Github, and we obtain a top-1 accuracy of 86.6%. This strongly indicates that the model successfully transfers its knowledge from Stack Overflow snippets to arbitrary source code documents.
A Convolutional Neural Network for Language-Agnostic Source Code Summarization
Mar 29, 2019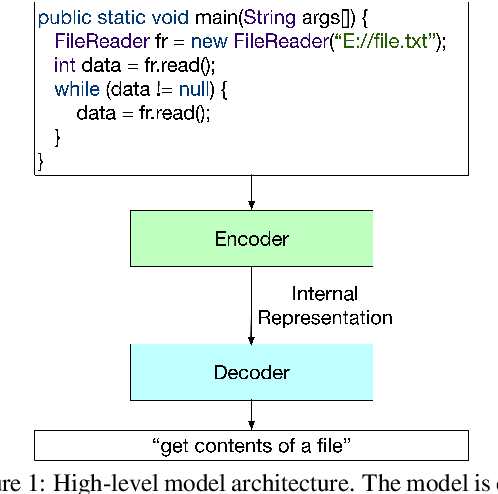
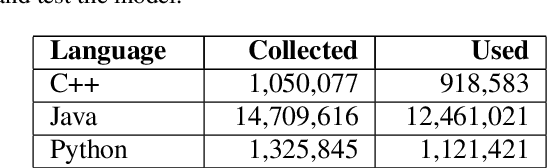
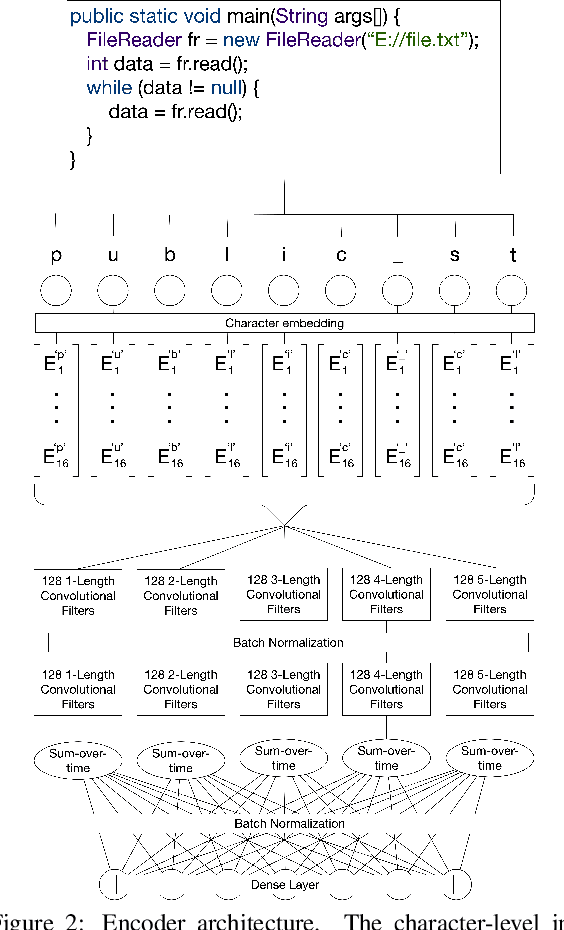
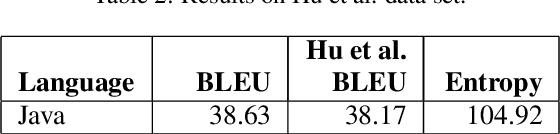
Descriptive comments play a crucial role in the software engineering process. They decrease development time, enable better bug detection, and facilitate the reuse of previously written code. However, comments are commonly the last of a software developer's priorities and are thus either insufficient or missing entirely. Automatic source code summarization may therefore have the ability to significantly improve the software development process. We introduce a novel encoder-decoder model that summarizes source code, effectively writing a comment to describe the code's functionality. We make two primary innovations beyond current source code summarization models. First, our encoder is fully language-agnostic and requires no complex input preprocessing. Second, our decoder has an open vocabulary, enabling it to predict any word, even ones not seen in training. We demonstrate results comparable to state-of-the-art methods on a single-language data set and provide the first results on a data set consisting of multiple programming languages.