 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convolutional Neural Network for Language-Agnostic Source Code Summarization
Paper and Code
Mar 29, 2019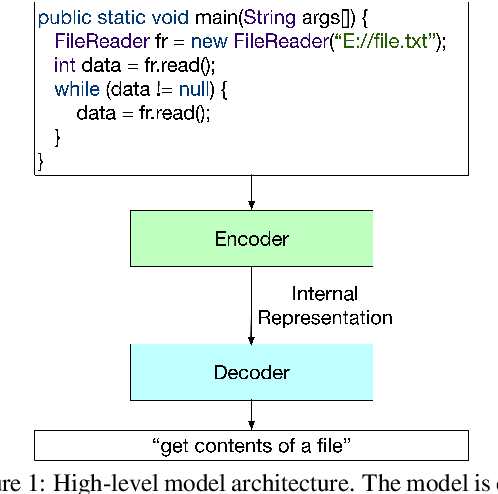
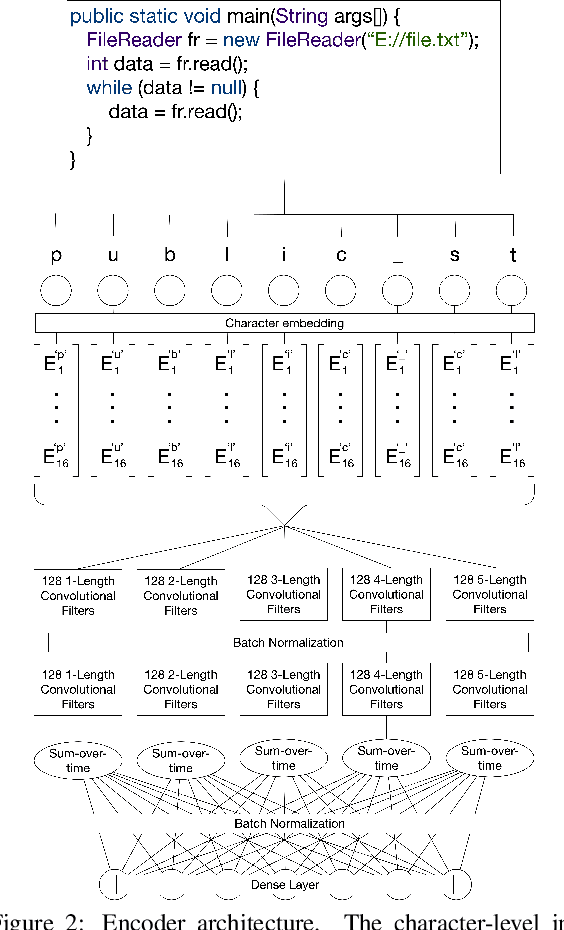
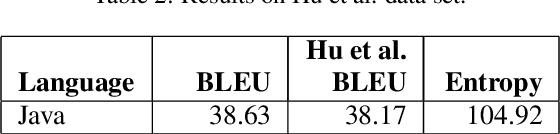
Descriptive comments play a crucial role in the software engineering process. They decrease development time, enable better bug detection, and facilitate the reuse of previously written code. However, comments are commonly the last of a software developer's priorities and are thus either insufficient or missing entirely. Automatic source code summarization may therefore have the ability to significantly improve the software development process. We introduce a novel encoder-decoder model that summarizes source code, effectively writing a comment to describe the code's functionality. We make two primary innovations beyond current source code summarization models. First, our encoder is fully language-agnostic and requires no complex input preprocessing. Second, our decoder has an open vocabulary, enabling it to predict any word, even ones not seen in training. We demonstrate results comparable to state-of-the-art methods on a single-language data set and provide the first results on a data set consisting of multiple programming languages.