 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Medical Imaging Generation with Generative Adversarial Networks For Plain Radiographs
Mar 28, 2024



In medical imaging, access to data is commonly limited due to patient privacy restrictions and the issue that it can be difficult to acquire enough data in the case of rare diseases.[1] The purpose of this investigation was to develop a reusable open-source synthetic image generation pipeline, the GAN Image Synthesis Tool (GIST), that is easy to use as well as easy to deploy. The pipeline helps to improve and standardize AI algorithms in the digital health space by generating high quality synthetic image data that is not linked to specific patients. Its image generation capabilities include the ability to generate imaging of pathologies or injuries with low incidence rates. This improvement of digital health AI algorithms could improve diagnostic accuracy, aid in patient care, decrease medicolegal claims, and ultimately decrease the overall cost of healthcare. The pipeline builds on existing Generative Adversarial Networks (GANs) algorithms, and preprocessing and evaluation steps were included for completeness. For this work, we focused on ensuring the pipeline supports radiography, with a focus on synthetic knee and elbow x-ray images. In designing the pipeline, we evaluated the performance of current GAN architectures, studying the performance on available x-ray data. We show that the pipeline is capable of generating high quality and clinically relevant images based on a lay person's evaluation and the Fr\'echet Inception Distance (FID) metric.
Backpropagation Clipping for Deep Learning with Differential Privacy
Feb 17, 2022We present backpropagation clipping, a novel variant of differentially private stochastic gradient descent (DP-SGD) for privacy-preserving deep learning. Our approach clips each trainable layer's inputs (during the forward pass) and its upstream gradients (during the backward pass) to ensure bounded global sensitivity for the layer's gradient; this combination replaces the gradient clipping step in existing DP-SGD variants. Our approach is simple to implement in existing deep learning frameworks. The results of our empirical evaluation demonstrate that backpropagation clipping provides higher accuracy at lower values for the privacy parameter $\epsilon$ compared to previous work. We achieve 98.7% accuracy for MNIST with $\epsilon = 0.07$ and 74% accuracy for CIFAR-10 with $\epsilon = 3.64$.
Logical Segmentation of Source Code
Jul 18, 2019
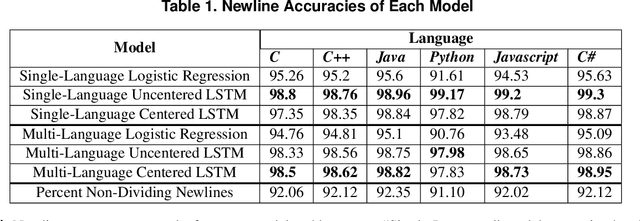
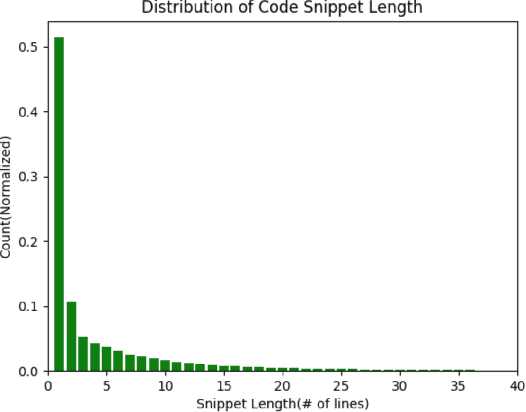

Many software analysis methods have come to rely on machine learning approaches. Code segmentation - the process of decomposing source code into meaningful blocks - can augment these methods by featurizing code, reducing noise, and limiting the problem space. Traditionally, code segmentation has been done using syntactic cues; current approaches do not intentionally capture logical content. We develop a novel deep learning approach to generate logical code segments regardless of the language or syntactic correctness of the code. Due to the lack of logically segmented source code, we introduce a unique data set construction technique to approximate ground truth for logically segmented code. Logical code segmentation can improve tasks such as automatically commenting code, detecting software vulnerabilities, repairing bugs, labeling code functionality, and synthesizing new code.
A Language-Agnostic Model for Semantic Source Code Labeling
Jun 03, 2019
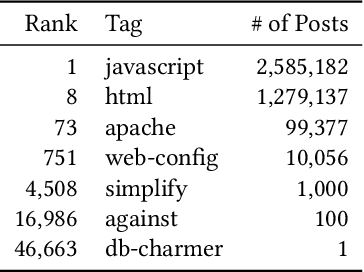
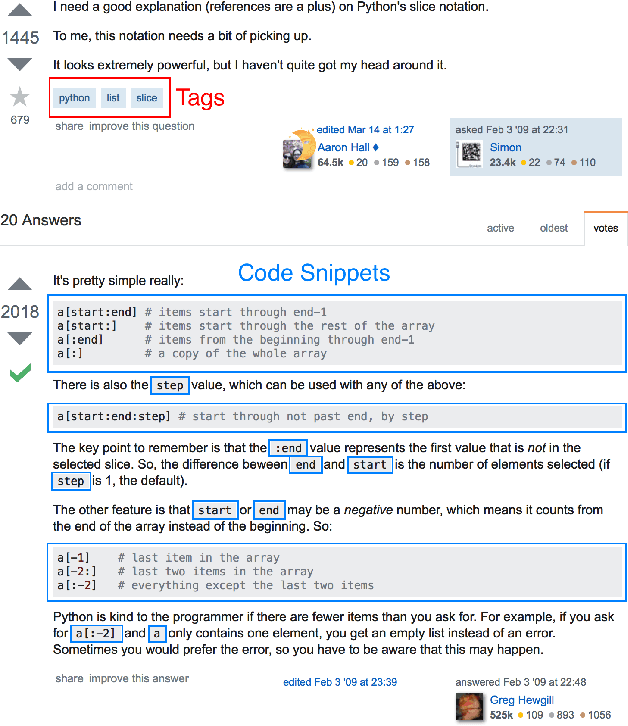
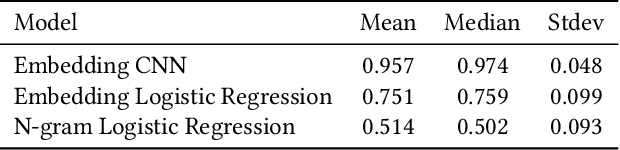
Code search and comprehension have become more difficult in recent years due to the rapid expansion of available source code. Current tools lack a way to label arbitrary code at scale while maintaining up-to-date representations of new programming languages, libraries, and functionalities. Comprehensive labeling of source code enables users to search for documents of interest and obtain a high-level understanding of their contents. We use Stack Overflow code snippets and their tags to train a language-agnostic, deep convolutional neural network to automatically predict semantic labels for source code documents. On Stack Overflow code snippets, we demonstrate a mean area under ROC of 0.957 over a long-tailed list of 4,508 tags. We also manually validate the model outputs on a diverse set of unlabeled source code documents retrieved from Github, and we obtain a top-1 accuracy of 86.6%. This strongly indicates that the model successfully transfers its knowledge from Stack Overflow snippets to arbitrary source code documents.
A Convolutional Neural Network for Language-Agnostic Source Code Summarization
Mar 29, 2019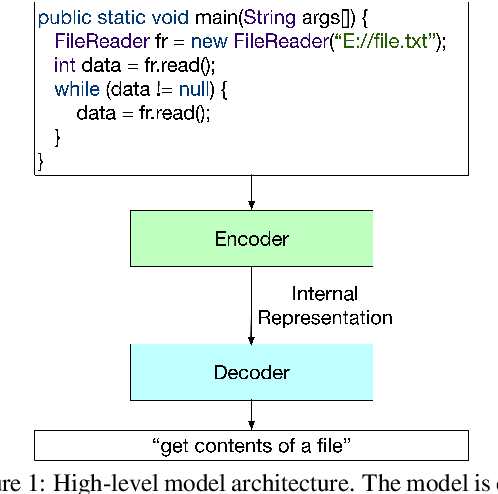
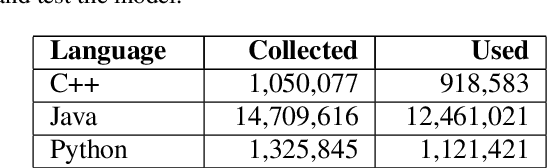
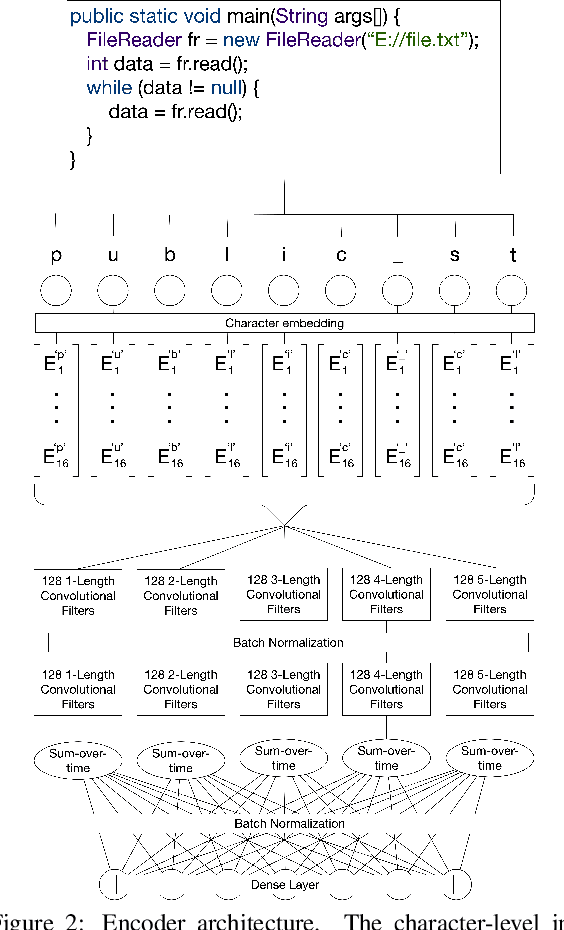
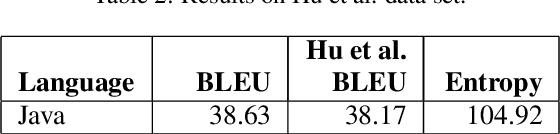
Descriptive comments play a crucial role in the software engineering process. They decrease development time, enable better bug detection, and facilitate the reuse of previously written code. However, comments are commonly the last of a software developer's priorities and are thus either insufficient or missing entirely. Automatic source code summarization may therefore have the ability to significantly improve the software development process. We introduce a novel encoder-decoder model that summarizes source code, effectively writing a comment to describe the code's functionality. We make two primary innovations beyond current source code summarization models. First, our encoder is fully language-agnostic and requires no complex input preprocessing. Second, our decoder has an open vocabulary, enabling it to predict any word, even ones not seen in training. We demonstrate results comparable to state-of-the-art methods on a single-language data set and provide the first results on a data set consisting of multiple programming languages.