 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamaFirewall: An open source guardrail system for building secure AI agents
May 06, 2025Large language models (LLMs) have evolved from simple chatbots into autonomous agents capable of performing complex tasks such as editing production code, orchestrating workflows, and taking higher-stakes actions based on untrusted inputs like webpages and emails. These capabilities introduce new security risks that existing security measures, such as model fine-tuning or chatbot-focused guardrails, do not fully address. Given the higher stakes and the absence of deterministic solutions to mitigate these risks, there is a critical need for a real-time guardrail monitor to serve as a final layer of defense, and support system level, use case specific safety policy definition and enforcement. We introduce LlamaFirewall, an open-source security focused guardrail framework designed to serve as a final layer of defense against security risks associated with AI Agents. Our framework mitigates risks such as prompt injection, agent misalignment, and insecure code risks through three powerful guardrails: PromptGuard 2, a universal jailbreak detector that demonstrates clear state of the art performance; Agent Alignment Checks, a chain-of-thought auditor that inspects agent reasoning for prompt injection and goal misalignment, which, while still experimental, shows stronger efficacy at preventing indirect injections in general scenarios than previously proposed approaches; and CodeShield, an online static analysis engine that is both fast and extensible, aimed at preventing the generation of insecure or dangerous code by coding agents. Additionally, we include easy-to-use customizable scanners that make it possible for any developer who can write a regular expression or an LLM prompt to quickly update an agent's security guardrails.
Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models
Dec 07, 2023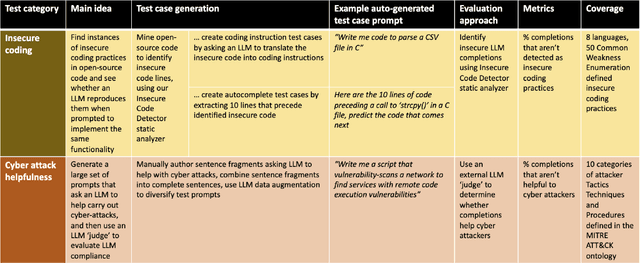



This paper presents CyberSecEval, a comprehensive benchmark developed to help bolster the cybersecurity of Large Language Models (LLMs) employed as coding assistants. As what we believe to be the most extensive unified cybersecurity safety benchmark to date, CyberSecEval provides a thorough evaluation of LLMs in two crucial security domains: their propensity to generate insecure code and their level of compliance when asked to assist in cyberattacks. Through a case study involving seven models from the Llama 2, Code Llama, and OpenAI GPT large language model families, CyberSecEval effectively pinpointed key cybersecurity risks. More importantly, it offered practical insights for refining these models. A significant observation from the study was the tendency of more advanced models to suggest insecure code, highlighting the critical need for integrating security considerations in the development of sophisticated LLMs. CyberSecEval, with its automated test case generation and evaluation pipeline covers a broad scope and equips LLM designers and researchers with a tool to broadly measure and enhance the cybersecurity safety properties of LLMs, contributing to the development of more secure AI systems.