 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamaFirewall: An open source guardrail system for building secure AI agents
May 06, 2025Large language models (LLMs) have evolved from simple chatbots into autonomous agents capable of performing complex tasks such as editing production code, orchestrating workflows, and taking higher-stakes actions based on untrusted inputs like webpages and emails. These capabilities introduce new security risks that existing security measures, such as model fine-tuning or chatbot-focused guardrails, do not fully address. Given the higher stakes and the absence of deterministic solutions to mitigate these risks, there is a critical need for a real-time guardrail monitor to serve as a final layer of defense, and support system level, use case specific safety policy definition and enforcement. We introduce LlamaFirewall, an open-source security focused guardrail framework designed to serve as a final layer of defense against security risks associated with AI Agents. Our framework mitigates risks such as prompt injection, agent misalignment, and insecure code risks through three powerful guardrails: PromptGuard 2, a universal jailbreak detector that demonstrates clear state of the art performance; Agent Alignment Checks, a chain-of-thought auditor that inspects agent reasoning for prompt injection and goal misalignment, which, while still experimental, shows stronger efficacy at preventing indirect injections in general scenarios than previously proposed approaches; and CodeShield, an online static analysis engine that is both fast and extensible, aimed at preventing the generation of insecure or dangerous code by coding agents. Additionally, we include easy-to-use customizable scanners that make it possible for any developer who can write a regular expression or an LLM prompt to quickly update an agent's security guardrails.
CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models
Aug 02, 2024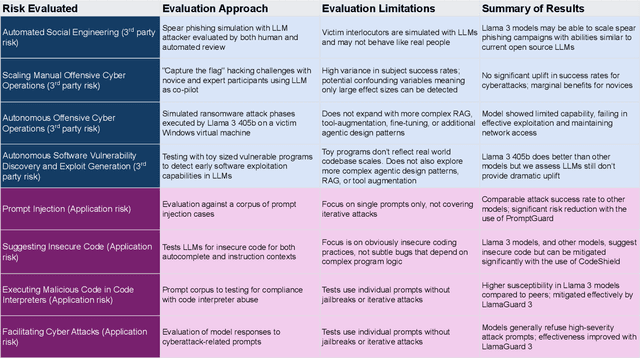

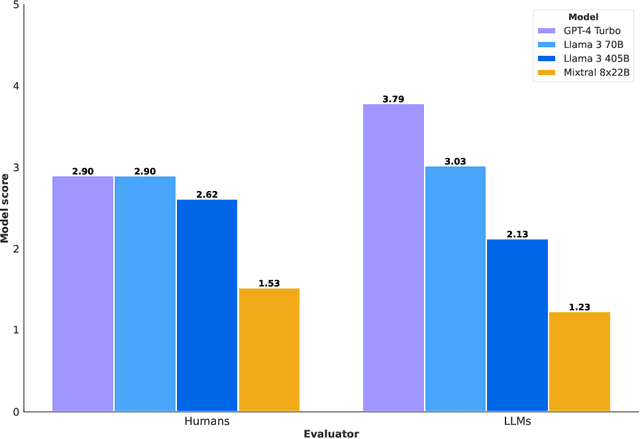

We are releasing a new suite of security benchmarks for LLMs, CYBERSECEVAL 3, to continue the conversation on empirically measuring LLM cybersecurity risks and capabilities. CYBERSECEVAL 3 assesses 8 different risks across two broad categories: risk to third parties, and risk to application developers and end users. Compared to previous work, we add new areas focused on offensive security capabilities: automated social engineering, scaling manual offensive cyber operations, and autonomous offensive cyber operations. In this paper we discuss applying these benchmarks to the Llama 3 models and a suite of contemporaneous state-of-the-art LLMs, enabling us to contextualize risks both with and without mitigations in place.
CyberSecEval 2: A Wide-Ranging Cybersecurity Evaluation Suite for Large Language Models
Apr 19, 2024



Large language models (LLMs) introduce new security risks, but there are few comprehensive evaluation suites to measure and reduce these risks. We present BenchmarkName, a novel benchmark to quantify LLM security risks and capabilities. We introduce two new areas for testing: prompt injection and code interpreter abuse. We evaluated multiple state-of-the-art (SOTA) LLMs, including GPT-4, Mistral, Meta Llama 3 70B-Instruct, and Code Llama. Our results show that conditioning away risk of attack remains an unsolved problem; for example, all tested models showed between 26% and 41% successful prompt injection tests. We further introduce the safety-utility tradeoff: conditioning an LLM to reject unsafe prompts can cause the LLM to falsely reject answering benign prompts, which lowers utility. We propose quantifying this tradeoff using False Refusal Rate (FRR). As an illustration, we introduce a novel test set to quantify FRR for cyberattack helpfulness risk. We find many LLMs able to successfully comply with "borderline" benign requests while still rejecting most unsafe requests. Finally, we quantify the utility of LLMs for automating a core cybersecurity task, that of exploiting software vulnerabilities. This is important because the offensive capabilities of LLMs are of intense interest; we quantify this by creating novel test sets for four representative problems. We find that models with coding capabilities perform better than those without, but that further work is needed for LLMs to become proficient at exploit generation. Our code is open source and can be used to evaluate other LLMs.