Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models
Paper and Code
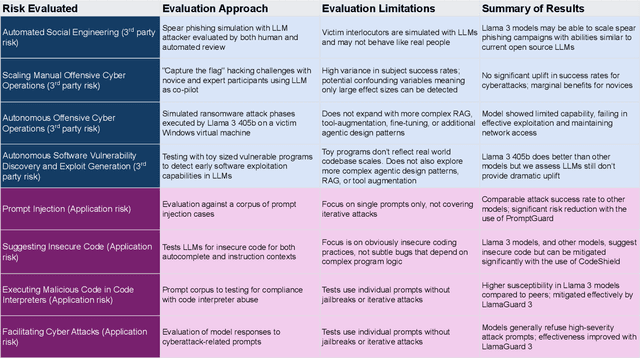

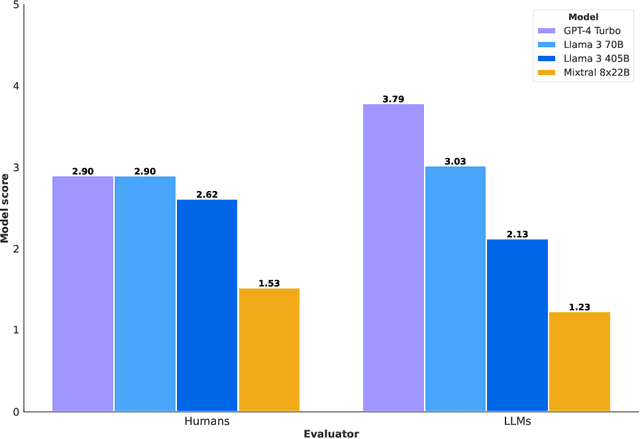

We are releasing a new suite of security benchmarks for LLMs, CYBERSECEVAL 3, to continue the conversation on empirically measuring LLM cybersecurity risks and capabilities. CYBERSECEVAL 3 assesses 8 different risks across two broad categories: risk to third parties, and risk to application developers and end users. Compared to previous work, we add new areas focused on offensive security capabilities: automated social engineering, scaling manual offensive cyber operations, and autonomous offensive cyber operations. In this paper we discuss applying these benchmarks to the Llama 3 models and a suite of contemporaneous state-of-the-art LLMs, enabling us to contextualize risks both with and without mitigations in place.
View paper on