 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Advanced Multimodal Learning for Seizure Detection and Prediction: Concept, Challenges, and Future Directions
Jan 08, 2026Epilepsy is a chronic neurological disorder characterized by recurrent unprovoked seizures, affects over 50 million people worldwide, and poses significant risks, including sudden unexpected death in epilepsy (SUDEP). Conventional unimodal approaches, primarily reliant on electroencephalography (EEG), face several key challenges, including low SNR, nonstationarity, inter- and intrapatient heterogeneity, portability, and real-time applicability in clinical settings. To address these issues, a comprehensive survey highlights the concept of advanced multimodal learning for epileptic seizure detection and prediction (AMLSDP). The survey presents the evolution of epileptic seizure detection (ESD) and prediction (ESP) technologies across different eras. The survey also explores the core challenges of multimodal and non-EEG-based ESD and ESP. To overcome the key challenges of the multimodal system, the survey introduces the advanced processing strategies for efficient AMLSDP. Furthermore, this survey highlights future directions for researchers and practitioners. We believe this work will advance neurotechnology toward wearable and imaging-based solutions for epilepsy monitoring, serving as a valuable resource for future innovations in this domain.
CyberSecEval 2: A Wide-Ranging Cybersecurity Evaluation Suite for Large Language Models
Apr 19, 2024



Large language models (LLMs) introduce new security risks, but there are few comprehensive evaluation suites to measure and reduce these risks. We present BenchmarkName, a novel benchmark to quantify LLM security risks and capabilities. We introduce two new areas for testing: prompt injection and code interpreter abuse. We evaluated multiple state-of-the-art (SOTA) LLMs, including GPT-4, Mistral, Meta Llama 3 70B-Instruct, and Code Llama. Our results show that conditioning away risk of attack remains an unsolved problem; for example, all tested models showed between 26% and 41% successful prompt injection tests. We further introduce the safety-utility tradeoff: conditioning an LLM to reject unsafe prompts can cause the LLM to falsely reject answering benign prompts, which lowers utility. We propose quantifying this tradeoff using False Refusal Rate (FRR). As an illustration, we introduce a novel test set to quantify FRR for cyberattack helpfulness risk. We find many LLMs able to successfully comply with "borderline" benign requests while still rejecting most unsafe requests. Finally, we quantify the utility of LLMs for automating a core cybersecurity task, that of exploiting software vulnerabilities. This is important because the offensive capabilities of LLMs are of intense interest; we quantify this by creating novel test sets for four representative problems. We find that models with coding capabilities perform better than those without, but that further work is needed for LLMs to become proficient at exploit generation. Our code is open source and can be used to evaluate other LLMs.
Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models
Dec 07, 2023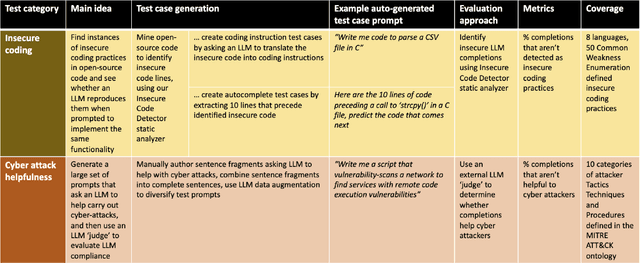



This paper presents CyberSecEval, a comprehensive benchmark developed to help bolster the cybersecurity of Large Language Models (LLMs) employed as coding assistants. As what we believe to be the most extensive unified cybersecurity safety benchmark to date, CyberSecEval provides a thorough evaluation of LLMs in two crucial security domains: their propensity to generate insecure code and their level of compliance when asked to assist in cyberattacks. Through a case study involving seven models from the Llama 2, Code Llama, and OpenAI GPT large language model families, CyberSecEval effectively pinpointed key cybersecurity risks. More importantly, it offered practical insights for refining these models. A significant observation from the study was the tendency of more advanced models to suggest insecure code, highlighting the critical need for integrating security considerations in the development of sophisticated LLMs. CyberSecEval, with its automated test case generation and evaluation pipeline covers a broad scope and equips LLM designers and researchers with a tool to broadly measure and enhance the cybersecurity safety properties of LLMs, contributing to the development of more secure AI systems.
Image-based Face Detection and Recognition: "State of the Art"
Feb 26, 2013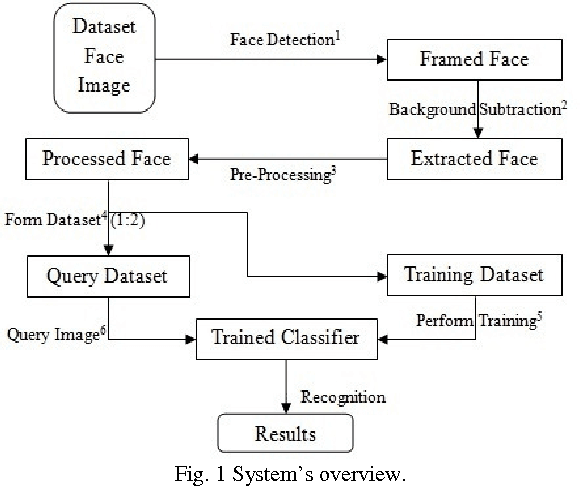



Face recognition from image or video is a popular topic in biometrics research. Many public places usually have surveillance cameras for video capture and these cameras have their significant value for security purpose. It is widely acknowledged that the face recognition have played an important role in surveillance system as it doesn't need the object's cooperation. The actual advantages of face based identification over other biometrics are uniqueness and acceptance. As human face is a dynamic object having high degree of variability in its appearance, that makes face detection a difficult problem in computer vision. In this field, accuracy and speed of identification is a main issue. The goal of this paper is to evaluate various face detection and recognition methods, provide complete solution for image based face detection and recognition with higher accuracy, better response rate as an initial step for video surveillance. Solution is proposed based on performed tests on various face rich databases in terms of subjects, pose, emotions, race and light.
* 4 pages, 3 table, 4 figure