 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatastrophic Forgetting in the Context of Model Updates
Jun 16, 2023A large obstacle to deploying deep learning models in practice is the process of updating models post-deployment (ideally, frequently). Deep neural networks can cost many thousands of dollars to train. When new data comes in the pipeline, you can train a new model from scratch (randomly initialized weights) on all existing data. Instead, you can take an existing model and fine-tune (continue to train) it on new data. The former is costly and slow. The latter is cheap and fast, but catastrophic forgetting generally causes the new model to 'forget' how to classify older data well. There are a plethora of complicated techniques to keep models from forgetting their past learnings. Arguably the most basic is to mix in a small amount of past data into the new data during fine-tuning: also known as 'data rehearsal'. In this paper, we compare various methods of limiting catastrophic forgetting and conclude that if you can maintain access to a portion of your past data (or tasks), data rehearsal is ideal in terms of overall accuracy across all time periods, and performs even better when combined with methods like Elastic Weight Consolidation (EWC). Especially when the amount of past data (past 'tasks') is large compared to new data, the cost of updating an existing model is far cheaper and faster than training a new model from scratch.
Magnificent Minified Models
Jun 16, 2023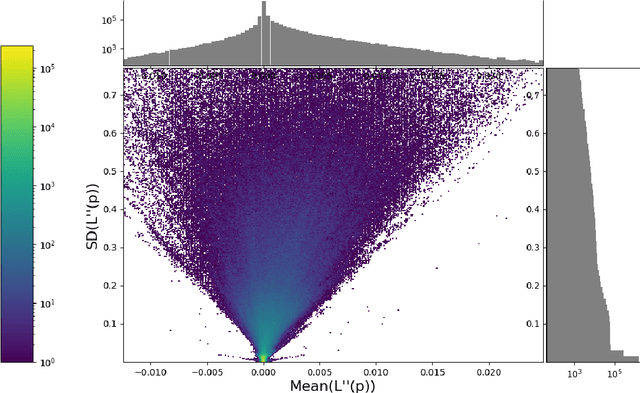
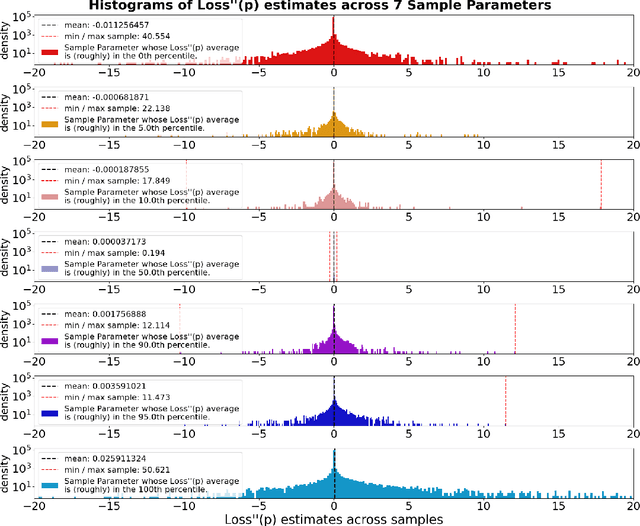
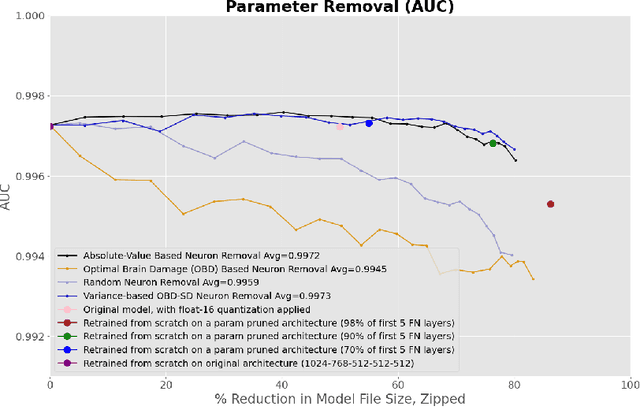
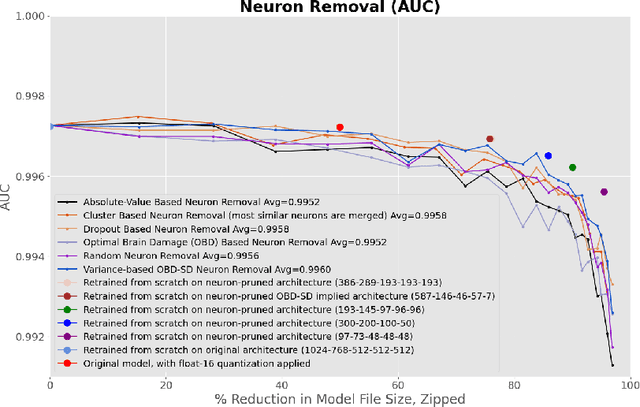
This paper concerns itself with the task of taking a large trained neural network and 'compressing' it to be smaller by deleting parameters or entire neurons, with minimal decreases in the resulting model accuracy. We compare various methods of parameter and neuron selection: dropout-based neuron damage estimation, neuron merging, absolute-value based selection, random selection, OBD (Optimal Brain Damage). We also compare a variation on the classic OBD method that slightly outperformed all other parameter and neuron selection methods in our tests with substantial pruning, which we call OBD-SD. We compare these methods against quantization of parameters. We also compare these techniques (all applied to a trained neural network), with neural networks trained from scratch (random weight initialization) on various pruned architectures. Our results are only barely consistent with the Lottery Ticket Hypothesis, in that fine-tuning a parameter-pruned model does slightly better than retraining a similarly pruned model from scratch with randomly initialized weights. For neuron-level pruning, retraining from scratch did much better in our experiments.
A Deep Learning Approach to Fast, Format-Agnostic Detection of Malicious Web Content
Apr 13, 2018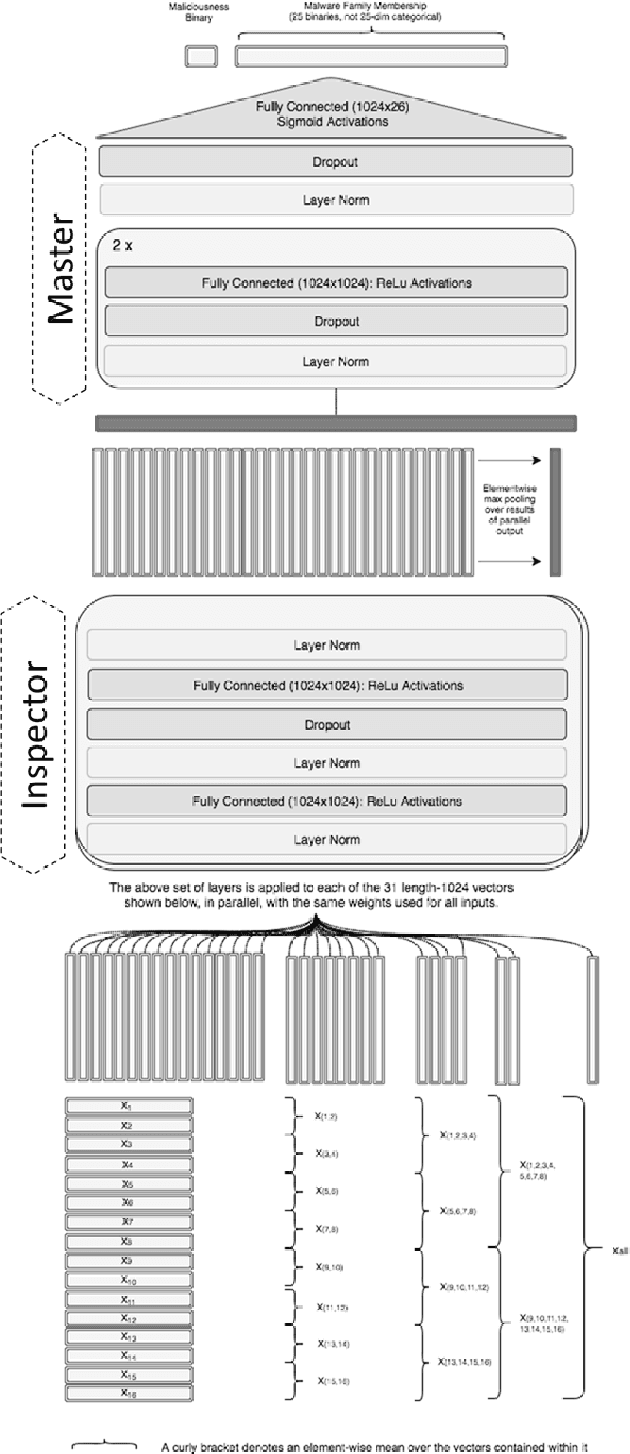
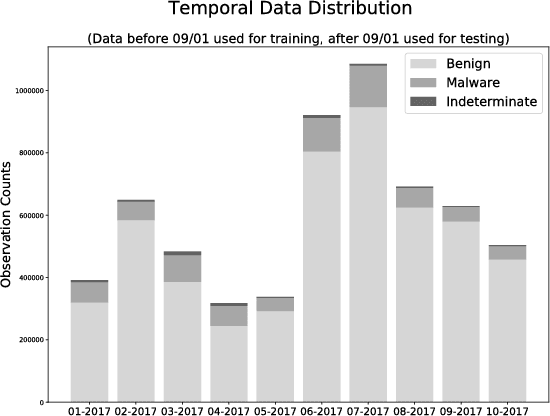
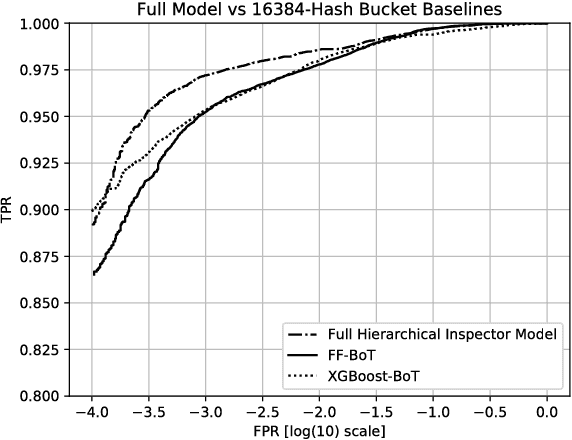
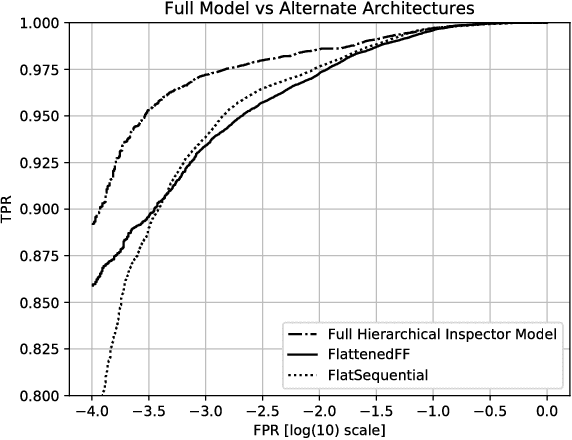
Malicious web content is a serious problem on the Internet today. In this paper we propose a deep learning approach to detecting malevolent web pages. While past work on web content detection has relied on syntactic parsing or on emulation of HTML and Javascript to extract features, our approach operates directly on a language-agnostic stream of tokens extracted directly from static HTML files with a simple regular expression. This makes it fast enough to operate in high-frequency data contexts like firewalls and web proxies, and allows it to avoid the attack surface exposure of complex parsing and emulation code. Unlike well-known approaches such as bag-of-words models, which ignore spatial information, our neural network examines content at hierarchical spatial scales, allowing our model to capture locality and yielding superior accuracy compared to bag-of-words baselines. Our proposed architecture achieves a 97.5% detection rate at a 0.1% false positive rate, and classifies small-batched web pages at a rate of over 100 per second on commodity hardware. The speed and accuracy of our approach makes it appropriate for deployment to endpoints, firewalls, and web proxies.