 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagnificent Minified Models
Paper and Code
Jun 16, 2023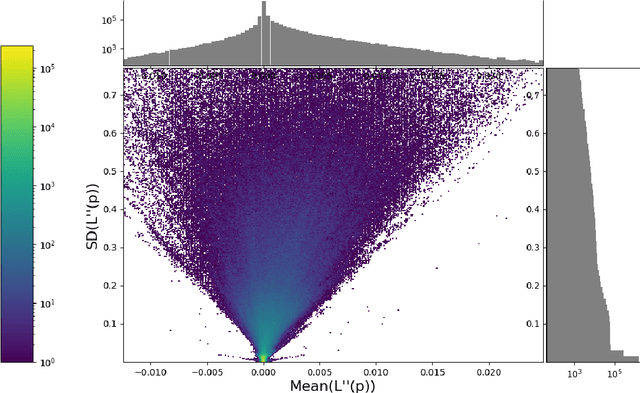
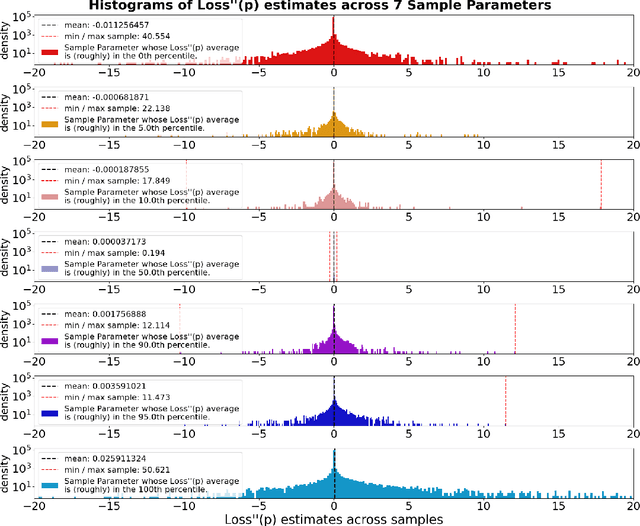
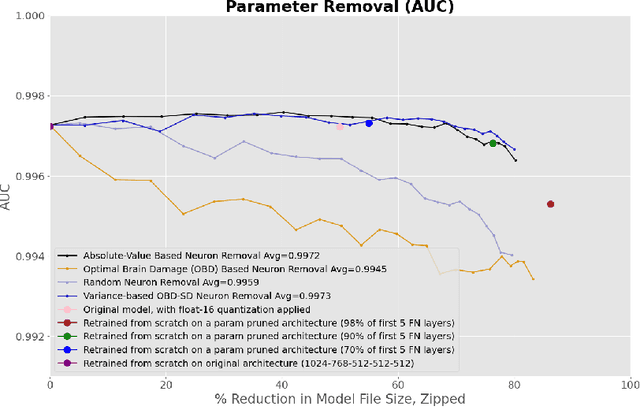
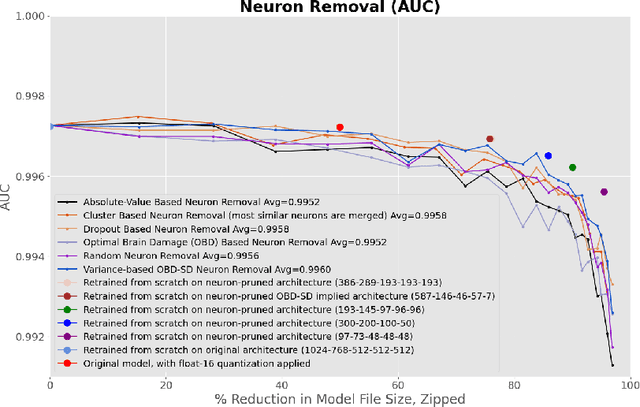
This paper concerns itself with the task of taking a large trained neural network and 'compressing' it to be smaller by deleting parameters or entire neurons, with minimal decreases in the resulting model accuracy. We compare various methods of parameter and neuron selection: dropout-based neuron damage estimation, neuron merging, absolute-value based selection, random selection, OBD (Optimal Brain Damage). We also compare a variation on the classic OBD method that slightly outperformed all other parameter and neuron selection methods in our tests with substantial pruning, which we call OBD-SD. We compare these methods against quantization of parameters. We also compare these techniques (all applied to a trained neural network), with neural networks trained from scratch (random weight initialization) on various pruned architectures. Our results are only barely consistent with the Lottery Ticket Hypothesis, in that fine-tuning a parameter-pruned model does slightly better than retraining a similarly pruned model from scratch with randomly initialized weights. For neuron-level pruning, retraining from scratch did much better in our experiments.