 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Catastrophic Forgetting in the Context of Model Updates
Jun 16, 2023A large obstacle to deploying deep learning models in practice is the process of updating models post-deployment (ideally, frequently). Deep neural networks can cost many thousands of dollars to train. When new data comes in the pipeline, you can train a new model from scratch (randomly initialized weights) on all existing data. Instead, you can take an existing model and fine-tune (continue to train) it on new data. The former is costly and slow. The latter is cheap and fast, but catastrophic forgetting generally causes the new model to 'forget' how to classify older data well. There are a plethora of complicated techniques to keep models from forgetting their past learnings. Arguably the most basic is to mix in a small amount of past data into the new data during fine-tuning: also known as 'data rehearsal'. In this paper, we compare various methods of limiting catastrophic forgetting and conclude that if you can maintain access to a portion of your past data (or tasks), data rehearsal is ideal in terms of overall accuracy across all time periods, and performs even better when combined with methods like Elastic Weight Consolidation (EWC). Especially when the amount of past data (past 'tasks') is large compared to new data, the cost of updating an existing model is far cheaper and faster than training a new model from scratch.
Magnificent Minified Models
Jun 16, 2023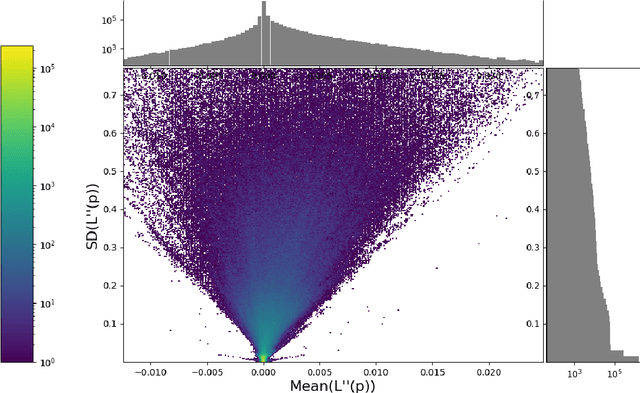
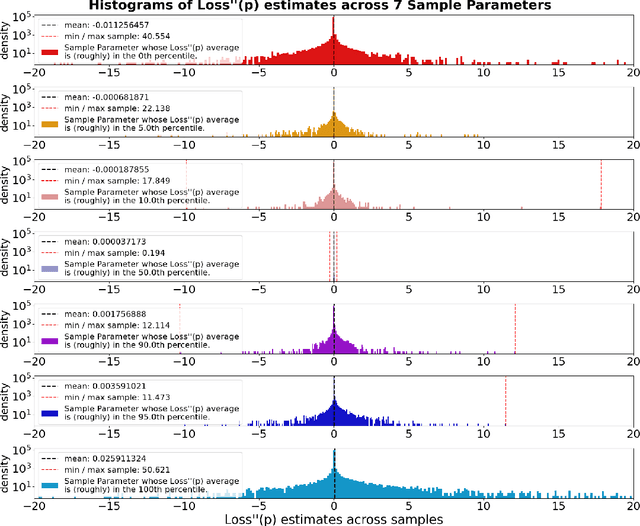
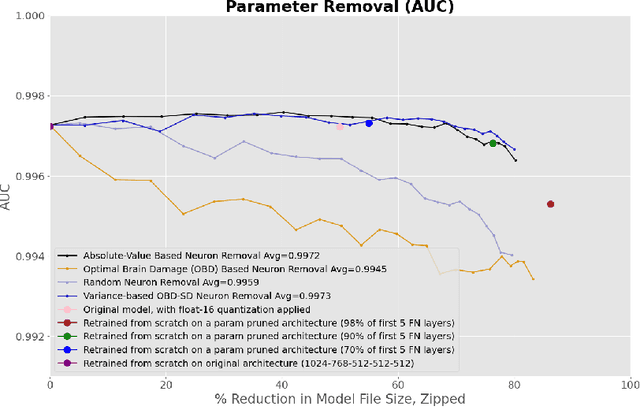
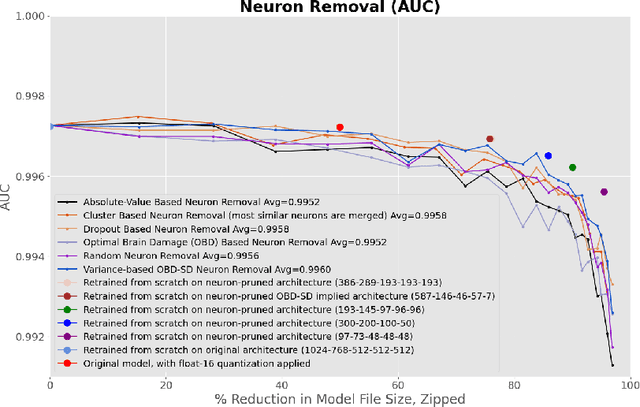
This paper concerns itself with the task of taking a large trained neural network and 'compressing' it to be smaller by deleting parameters or entire neurons, with minimal decreases in the resulting model accuracy. We compare various methods of parameter and neuron selection: dropout-based neuron damage estimation, neuron merging, absolute-value based selection, random selection, OBD (Optimal Brain Damage). We also compare a variation on the classic OBD method that slightly outperformed all other parameter and neuron selection methods in our tests with substantial pruning, which we call OBD-SD. We compare these methods against quantization of parameters. We also compare these techniques (all applied to a trained neural network), with neural networks trained from scratch (random weight initialization) on various pruned architectures. Our results are only barely consistent with the Lottery Ticket Hypothesis, in that fine-tuning a parameter-pruned model does slightly better than retraining a similarly pruned model from scratch with randomly initialized weights. For neuron-level pruning, retraining from scratch did much better in our experiments.