 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGit Blame Who?: Stylistic Authorship Attribution of Small, Incomplete Source Code Fragments
Paper and Code
Mar 16, 2017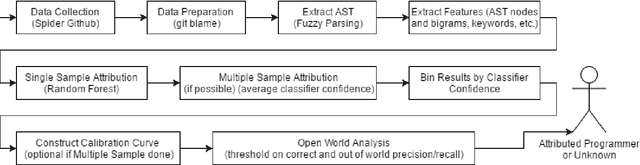
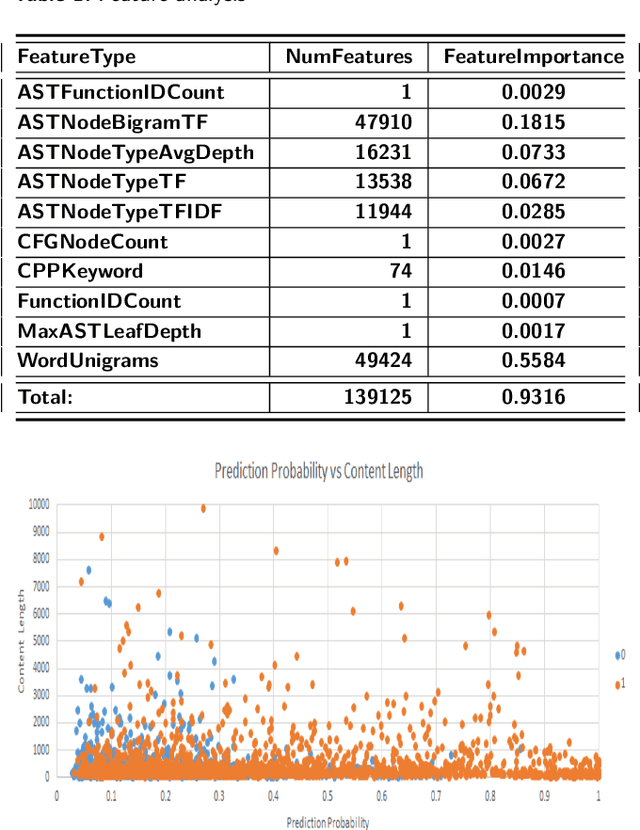
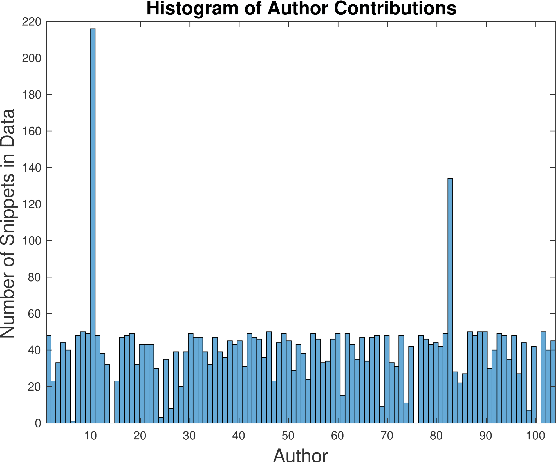
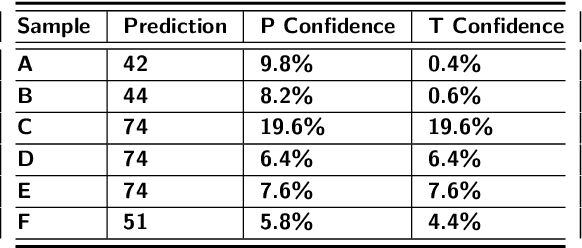
Program authorship attribution has implications for the privacy of programmers who wish to contribute code anonymously. While previous work has shown that complete files that are individually authored can be attributed, we show here for the first time that accounts belonging to open source contributors containing short, incomplete, and typically uncompilable fragments can also be effectively attributed. We propose a technique for authorship attribution of contributor accounts containing small source code samples, such as those that can be obtained from version control systems or other direct comparison of sequential versions. We show that while application of previous methods to individual small source code samples yields an accuracy of about 73% for 106 programmers as a baseline, by ensembling and averaging the classification probabilities of a sufficiently large set of samples belonging to the same author we achieve 99% accuracy for assigning the set of samples to the correct author. Through these results, we demonstrate that attribution is an important threat to privacy for programmers even in real-world collaborative environments such as GitHub. Additionally, we propose the use of calibration curves to identify samples by unknown and previously unencountered authors in the open world setting. We show that we can also use these calibration curves in the case that we do not have linking information and thus are forced to classify individual samples directly. This is because the calibration curves allow us to identify which samples are more likely to have been correctly attributed. Using such a curve can help an analyst choose a cut-off point which will prevent most misclassifications, at the cost of causing the rejection of some of the more dubious correct attributions.