 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMSD-CDFSAR: Distillation from Mixed-Source Domain for Cross-Domain Few-shot Action Recognition
Jul 08, 2024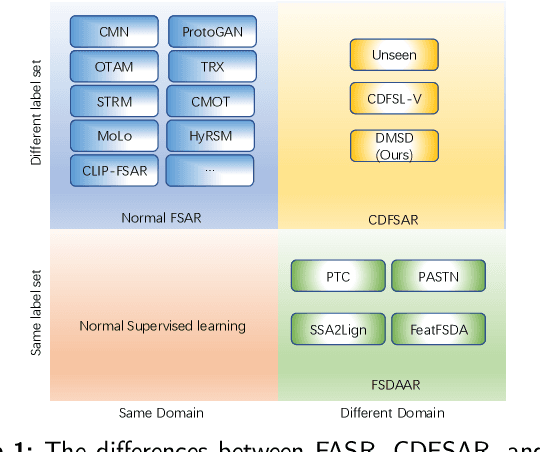
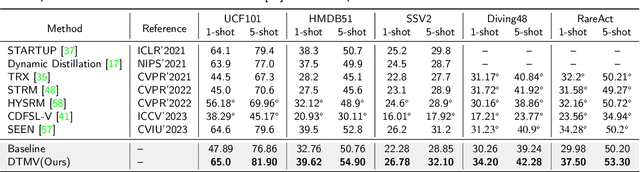
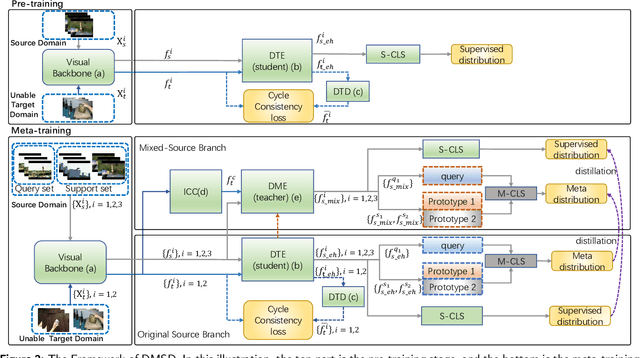

Few-shot action recognition is an emerging field in computer vision, primarily focused on meta-learning within the same domain. However, challenges arise in real-world scenario deployment, as gathering extensive labeled data within a specific domain is laborious and time-intensive. Thus, attention shifts towards cross-domain few-shot action recognition, requiring the model to generalize across domains with significant deviations. Therefore, we propose a novel approach, ``Distillation from Mixed-Source Domain", tailored to address this conundrum. Our method strategically integrates insights from both labeled data of the source domain and unlabeled data of the target domain during the training. The ResNet18 is used as the backbone to extract spatial features from the source and target domains. We design two branches for meta-training: the original-source and the mixed-source branches. In the first branch, a Domain Temporal Encoder is employed to capture temporal features for both the source and target domains. Additionally, a Domain Temporal Decoder is employed to reconstruct all extracted features. In the other branch, a Domain Mixed Encoder is used to handle labeled source domain data and unlabeled target domain data, generating mixed-source domain features. We incorporate a pre-training stage before meta-training, featuring a network architecture similar to that of the first branch. Lastly, we introduce a dual distillation mechanism to refine the classification probabilities of source domain features, aligning them with those of mixed-source domain features. This iterative process enriches the insights of the original-source branch with knowledge from the mixed-source branch, thereby enhancing the model's generalization capabilities. Our code is available at URL: \url{https://xxxx/xxxx/xxxx.git}
Multi-view Distillation based on Multi-modal Fusion for Few-shot Action Recognition
Jan 16, 2024In recent years, few-shot action recognition has attracted increasing attention. It generally adopts the paradigm of meta-learning. In this field, overcoming the overlapping distribution of classes and outliers is still a challenging problem based on limited samples. We believe the combination of Multi-modal and Multi-view can improve this issue depending on information complementarity. Therefore, we propose a method of Multi-view Distillation based on Multi-modal Fusion. Firstly, a Probability Prompt Selector for the query is constructed to generate probability prompt embedding based on the comparison score between the prompt embeddings of the support and the visual embedding of the query. Secondly, we establish a Multi-view. In each view, we fuse the prompt embedding as consistent information with visual and the global or local temporal context to overcome the overlapping distribution of classes and outliers. Thirdly, we perform the distance fusion for the Multi-view and the mutual distillation of matching ability from one to another, enabling the model to be more robust to the distribution bias. Our code is available at the URL: \url{https://github.com/cofly2014/MDMF}.
Consistency Prototype Module and Motion Compensation for Few-Shot Action Recognition (CLIP-CP$\mathbf{M^2}$C)
Dec 02, 2023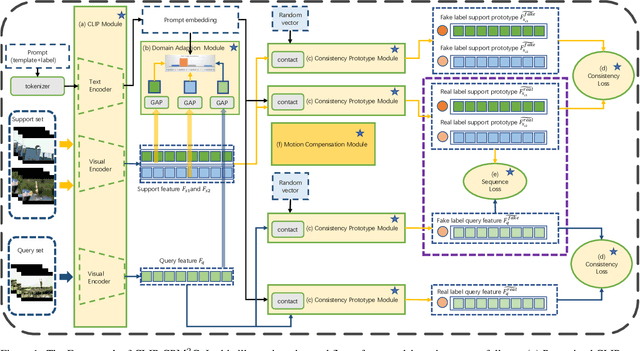



Recently, few-shot action recognition has significantly progressed by learning the feature discriminability and designing suitable comparison methods. Still, there are the following restrictions. (a) Previous works are mainly based on visual mono-modal. Although some multi-modal works use labels as supplementary to construct prototypes of support videos, they can not use this information for query videos. The labels are not used efficiently. (b) Most of the works ignore the motion feature of video, although the motion features are essential for distinguishing. We proposed a Consistency Prototype and Motion Compensation Network(CLIP-CP$M^2$C) to address these issues. Firstly, we use the CLIP for multi-modal few-shot action recognition with the text-image comparison for domain adaption. Secondly, in order to make the amount of information between the prototype and the query more similar, we propose a novel method to compensate for the text(prompt) information of query videos when text(prompt) does not exist, which depends on a Consistency Loss. Thirdly, we use the differential features of the adjacent frames in two directions as the motion features, which explicitly embeds the network with motion dynamics. We also apply the Consistency Loss to the motion features. Extensive experiments on standard benchmark datasets demonstrate that the proposed method can compete with state-of-the-art results. Our code is available at the URL: https://github.com/xxx/xxx.git.