 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregation Schemes for Single-Vector WSI Representation Learning in Digital Pathology
Jan 29, 2025



A crucial step to efficiently integrate Whole Slide Images (WSIs) in computational pathology is assigning a single high-quality feature vector, i.e., one embedding, to each WSI. With the existence of many pre-trained deep neural networks and the emergence of foundation models, extracting embeddings for sub-images (i.e., tiles or patches) is straightforward. However, for WSIs, given their high resolution and gigapixel nature, inputting them into existing GPUs as a single image is not feasible. As a result, WSIs are usually split into many patches. Feeding each patch to a pre-trained model, each WSI can then be represented by a set of patches, hence, a set of embeddings. Hence, in such a setup, WSI representation learning reduces to set representation learning where for each WSI we have access to a set of patch embeddings. To obtain a single embedding from a set of patch embeddings for each WSI, multiple set-based learning schemes have been proposed in the literature. In this paper, we evaluate the WSI search performance of multiple recently developed aggregation techniques (mainly set representation learning techniques) including simple average or max pooling operations, Deep Sets, Memory networks, Focal attention, Gaussian Mixture Model (GMM) Fisher Vector, and deep sparse and binary Fisher Vector on four different primary sites including bladder, breast, kidney, and Colon from TCGA. Further, we benchmark the search performance of these methods against the median of minimum distances of patch embeddings, a non-aggregating approach used for WSI retrieval.
Zero-Shot Whole Slide Image Retrieval in Histopathology Using Embeddings of Foundation Models
Sep 06, 2024We have tested recently published foundation models for histopathology for image retrieval. We report macro average of F1 score for top-1 retrieval, majority of top-3 retrievals, and majority of top-5 retrievals. We perform zero-shot retrievals, i.e., we do not alter embeddings and we do not train any classifier. As test data, we used diagnostic slides of TCGA, The Cancer Genome Atlas, consisting of 23 organs and 117 cancer subtypes. As a search platform we used Yottixel that enabled us to perform WSI search using patches. Achieved F1 scores show low performance, e.g., for top-5 retrievals, 27% +/- 13% (Yottixel-DenseNet), 42% +/- 14% (Yottixel-UNI), 40%+/-13% (Yottixel-Virchow), and 41%+/-13% (Yottixel-GigaPath). The results for GigaPath WSI will be delayed due to the significant computational resources required for processing
AlcLaM: Arabic Dialectal Language Model
Jul 18, 2024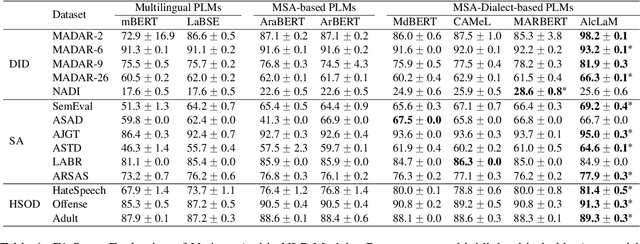
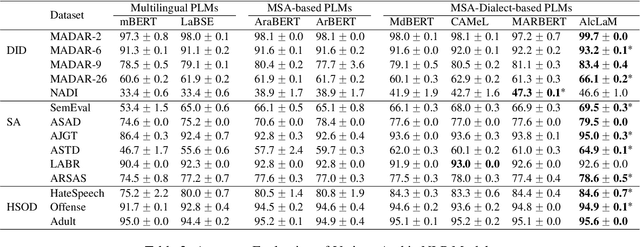
Pre-trained Language Models (PLMs) are integral to many modern natural language processing (NLP) systems. Although multilingual models cover a wide range of languages, they often grapple with challenges like high inference costs and a lack of diverse non-English training data. Arabic-specific PLMs are trained predominantly on modern standard Arabic, which compromises their performance on regional dialects. To tackle this, we construct an Arabic dialectal corpus comprising 3.4M sentences gathered from social media platforms. We utilize this corpus to expand the vocabulary and retrain a BERT-based model from scratch. Named AlcLaM, our model was trained using only 13 GB of text, which represents a fraction of the data used by existing models such as CAMeL, MARBERT, and ArBERT, compared to 7.8%, 10.2%, and 21.3%, respectively. Remarkably, AlcLaM demonstrates superior performance on a variety of Arabic NLP tasks despite the limited training data. AlcLaM is available at GitHub https://github.com/amurtadha/Alclam and HuggingFace https://huggingface.co/rahbi.
SPLICE -- Streamlining Digital Pathology Image Processing
Apr 26, 2024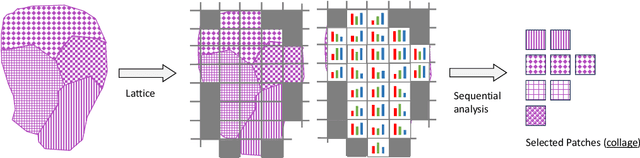
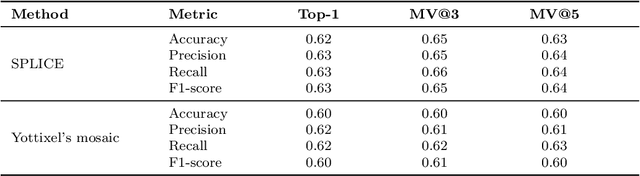
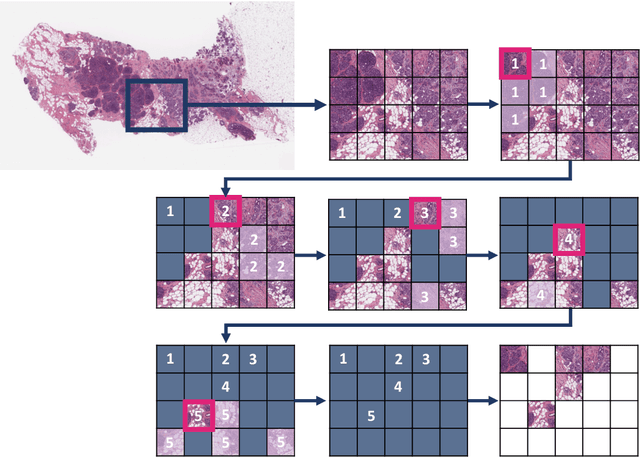
Digital pathology and the integration of artificial intelligence (AI) models have revolutionized histopathology, opening new opportunities. With the increasing availability of Whole Slide Images (WSIs), there's a growing demand for efficient retrieval, processing, and analysis of relevant images from vast biomedical archives. However, processing WSIs presents challenges due to their large size and content complexity. Full computer digestion of WSIs is impractical, and processing all patches individually is prohibitively expensive. In this paper, we propose an unsupervised patching algorithm, Sequential Patching Lattice for Image Classification and Enquiry (SPLICE). This novel approach condenses a histopathology WSI into a compact set of representative patches, forming a "collage" of WSI while minimizing redundancy. SPLICE prioritizes patch quality and uniqueness by sequentially analyzing a WSI and selecting non-redundant representative features. We evaluated SPLICE for search and match applications, demonstrating improved accuracy, reduced computation time, and storage requirements compared to existing state-of-the-art methods. As an unsupervised method, SPLICE effectively reduces storage requirements for representing tissue images by 50%. This reduction enables numerous algorithms in computational pathology to operate much more efficiently, paving the way for accelerated adoption of digital pathology.
Analysis and Validation of Image Search Engines in Histopathology
Jan 06, 2024
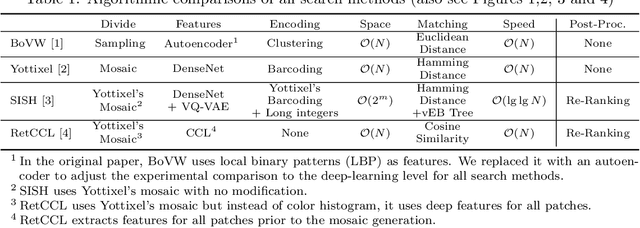

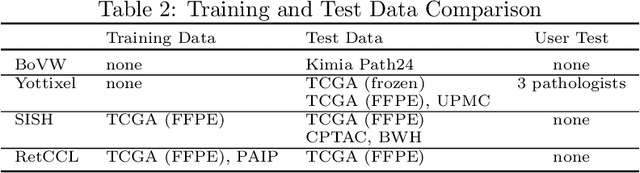
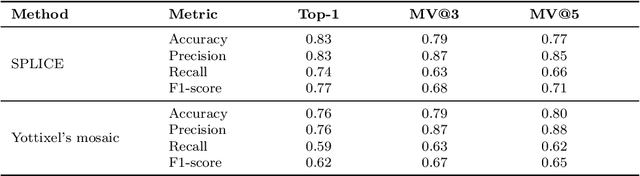
Searching for similar images in archives of histology and histopathology images is a crucial task that may aid in patient matching for various purposes, ranging from triaging and diagnosis to prognosis and prediction. Whole slide images (WSIs) are highly detailed digital representations of tissue specimens mounted on glass slides. Matching WSI to WSI can serve as the critical method for patient matching. In this paper, we report extensive analysis and validation of four search methods bag of visual words (BoVW), Yottixel, SISH, RetCCL, and some of their potential variants. We analyze their algorithms and structures and assess their performance. For this evaluation, we utilized four internal datasets ($1269$ patients) and three public datasets ($1207$ patients), totaling more than $200,000$ patches from $38$ different classes/subtypes across five primary sites. Certain search engines, for example, BoVW, exhibit notable efficiency and speed but suffer from low accuracy. Conversely, search engines like Yottixel demonstrate efficiency and speed, providing moderately accurate results. Recent proposals, including SISH, display inefficiency and yield inconsistent outcomes, while alternatives like RetCCL prove inadequate in both accuracy and efficiency. Further research is imperative to address the dual aspects of accuracy and minimal storage requirements in histopathological image search.
Selection of Distinct Morphologies to Divide & Conquer Gigapixel Pathology Images
Nov 16, 2023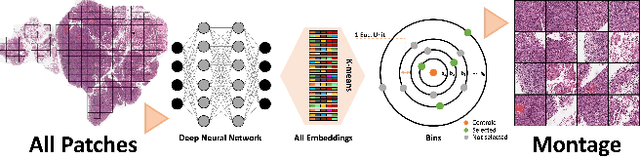

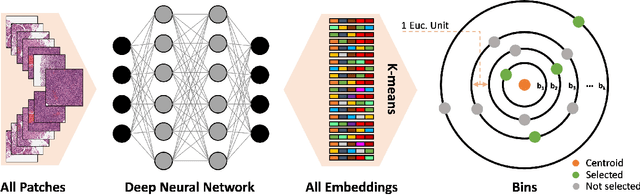
Whole slide images (WSIs) are massive digital pathology files illustrating intricate tissue structures. Selecting a small, representative subset of patches from each WSI is essential yet challenging. Therefore, following the "Divide & Conquer" approach becomes essential to facilitate WSI analysis including the classification and the WSI matching in computational pathology. To this end, we propose a novel method termed "Selection of Distinct Morphologies" (SDM) to choose a subset of WSI patches. The aim is to encompass all inherent morphological variations within a given WSI while simultaneously minimizing the number of selected patches to represent these variations, ensuring a compact yet comprehensive set of patches. This systematically curated patch set forms what we term a "montage". We assess the representativeness of the SDM montage across various public and private histopathology datasets. This is conducted by using the leave-one-out WSI search and matching evaluation method, comparing it with the state-of-the-art Yottixel's mosaic. SDM demonstrates remarkable efficacy across all datasets during its evaluation. Furthermore, SDM eliminates the necessity for empirical parameterization, a crucial aspect of Yottixel's mosaic, by inherently optimizing the selection process to capture the distinct morphological features within the WSI.
Rotation-Agnostic Image Representation Learning for Digital Pathology
Nov 14, 2023

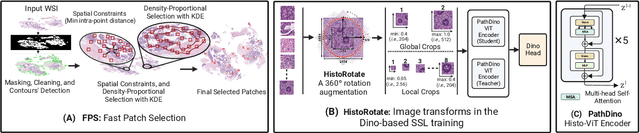
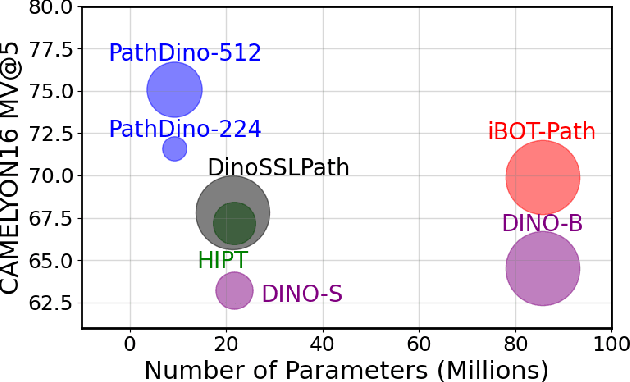
This paper addresses complex challenges in histopathological image analysis through three key contributions. Firstly, it introduces a fast patch selection method, FPS, for whole-slide image (WSI) analysis, significantly reducing computational cost while maintaining accuracy. Secondly, it presents PathDino, a lightweight histopathology feature extractor with a minimal configuration of five Transformer blocks and only 9 million parameters, markedly fewer than alternatives. Thirdly, it introduces a rotation-agnostic representation learning paradigm using self-supervised learning, effectively mitigating overfitting. We also show that our compact model outperforms existing state-of-the-art histopathology-specific vision transformers on 12 diverse datasets, including both internal datasets spanning four sites (breast, liver, skin, and colorectal) and seven public datasets (PANDA, CAMELYON16, BRACS, DigestPath, Kather, PanNuke, and WSSS4LUAD). Notably, even with a training dataset of 6 million histopathology patches from The Cancer Genome Atlas (TCGA), our approach demonstrates an average 8.5% improvement in patch-level majority vote performance. These contributions provide a robust framework for enhancing image analysis in digital pathology, rigorously validated through extensive evaluation. Project Page: https://rhazeslab.github.io/PathDino-Page/
When is a Foundation Model a Foundation Model
Sep 14, 2023

Recently, several studies have reported on the fine-tuning of foundation models for image-text modeling in the field of medicine, utilizing images from online data sources such as Twitter and PubMed. Foundation models are large, deep artificial neural networks capable of learning the context of a specific domain through training on exceptionally extensive datasets. Through validation, we have observed that the representations generated by such models exhibit inferior performance in retrieval tasks within digital pathology when compared to those generated by significantly smaller, conventional deep networks.
OSRE: Object-to-Spot Rotation Estimation for Bike Parking Assessment
Mar 01, 2023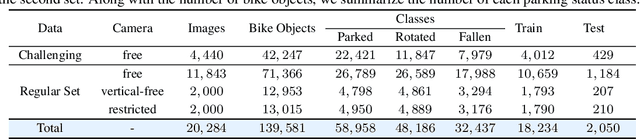

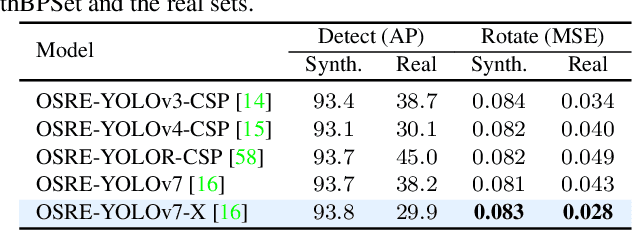
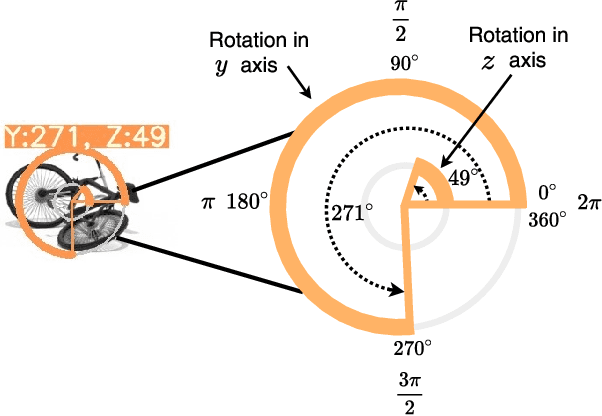
Current deep models provide remarkable object detection in terms of object classification and localization. However, estimating object rotation with respect to other visual objects in the visual context of an input image still lacks deep studies due to the unavailability of object datasets with rotation annotations. This paper tackles these two challenges to solve the rotation estimation of a parked bike with respect to its parking area. First, we leverage the power of 3D graphics to build a camera-agnostic well-annotated Synthetic Bike Rotation Dataset (SynthBRSet). Then, we propose an object-to-spot rotation estimator (OSRE) by extending the object detection task to further regress the bike rotations in two axes. Since our model is purely trained on synthetic data, we adopt image smoothing techniques when deploying it on real-world images. The proposed OSRE is evaluated on synthetic and real-world data providing promising results. Our data and code are available at \href{https://github.com/saghiralfasly/OSRE-Project}{https://github.com/saghiralfasly/OSRE-Project}.
Learnable Irrelevant Modality Dropout for Multimodal Action Recognition on Modality-Specific Annotated Videos
Mar 27, 2022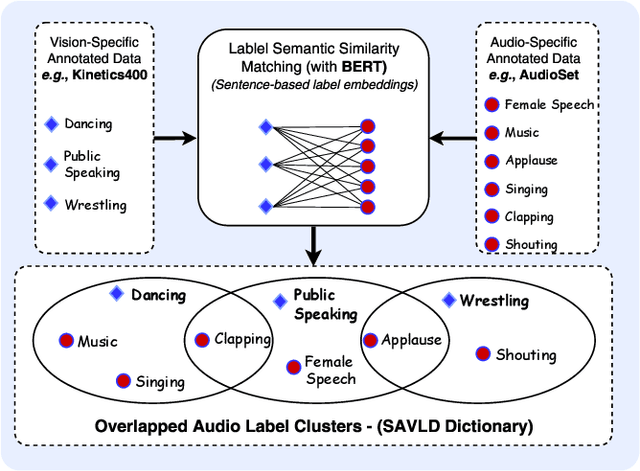

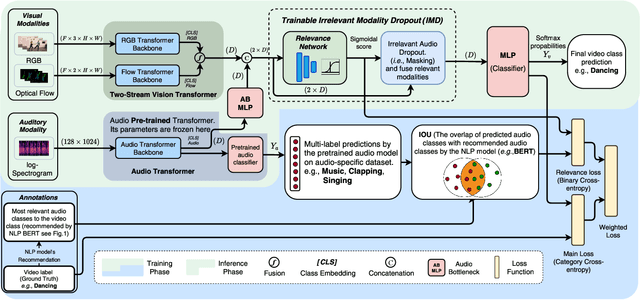
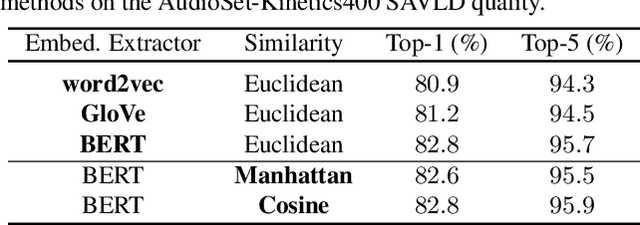
With the assumption that a video dataset is multimodality annotated in which auditory and visual modalities both are labeled or class-relevant, current multimodal methods apply modality fusion or cross-modality attention. However, effectively leveraging the audio modality in vision-specific annotated videos for action recognition is of particular challenge. To tackle this challenge, we propose a novel audio-visual framework that effectively leverages the audio modality in any solely vision-specific annotated dataset. We adopt the language models (e.g., BERT) to build a semantic audio-video label dictionary (SAVLD) that maps each video label to its most K-relevant audio labels in which SAVLD serves as a bridge between audio and video datasets. Then, SAVLD along with a pretrained audio multi-label model are used to estimate the audio-visual modality relevance during the training phase. Accordingly, a novel learnable irrelevant modality dropout (IMD) is proposed to completely drop out the irrelevant audio modality and fuse only the relevant modalities. Moreover, we present a new two-stream video Transformer for efficiently modeling the visual modalities. Results on several vision-specific annotated datasets including Kinetics400 and UCF-101 validated our framework as it outperforms most relevant action recognition methods.