 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Irrelevant Modality Dropout for Multimodal Action Recognition on Modality-Specific Annotated Videos
Mar 27, 2022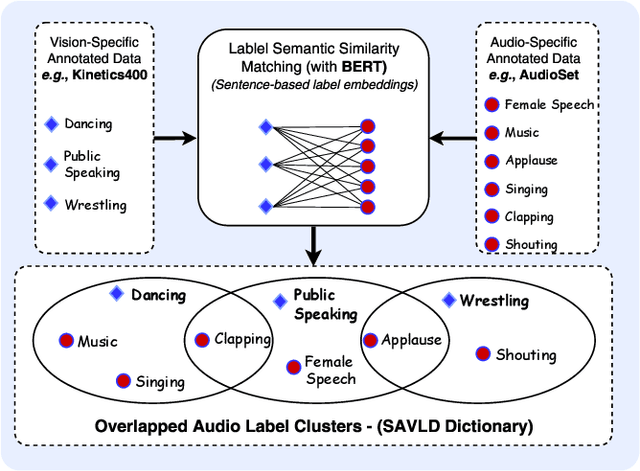

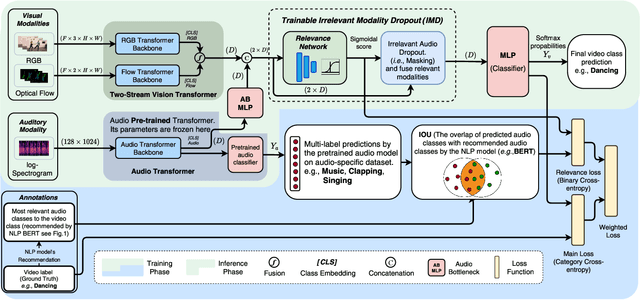
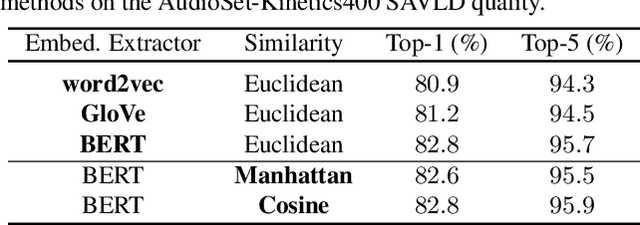
With the assumption that a video dataset is multimodality annotated in which auditory and visual modalities both are labeled or class-relevant, current multimodal methods apply modality fusion or cross-modality attention. However, effectively leveraging the audio modality in vision-specific annotated videos for action recognition is of particular challenge. To tackle this challenge, we propose a novel audio-visual framework that effectively leverages the audio modality in any solely vision-specific annotated dataset. We adopt the language models (e.g., BERT) to build a semantic audio-video label dictionary (SAVLD) that maps each video label to its most K-relevant audio labels in which SAVLD serves as a bridge between audio and video datasets. Then, SAVLD along with a pretrained audio multi-label model are used to estimate the audio-visual modality relevance during the training phase. Accordingly, a novel learnable irrelevant modality dropout (IMD) is proposed to completely drop out the irrelevant audio modality and fuse only the relevant modalities. Moreover, we present a new two-stream video Transformer for efficiently modeling the visual modalities. Results on several vision-specific annotated datasets including Kinetics400 and UCF-101 validated our framework as it outperforms most relevant action recognition methods.
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network
May 30, 2021Recently, it has been demonstrated that the performance of a deep convolutional neural network can be effectively improved by embedding an attention module into it. In this work, a novel lightweight and effective attention method named Pyramid Split Attention (PSA) module is proposed. By replacing the 3x3 convolution with the PSA module in the bottleneck blocks of the ResNet, a novel representational block named Efficient Pyramid Split Attention (EPSA) is obtained. The EPSA block can be easily added as a plug-and-play component into a well-established backbone network, and significant improvements on model performance can be achieved. Hence, a simple and efficient backbone architecture named EPSANet is developed in this work by stacking these ResNet-style EPSA blocks. Correspondingly, a stronger multi-scale representation ability can be offered by the proposed EPSANet for various computer vision tasks including but not limited to, image classification, object detection, instance segmentation, etc. Without bells and whistles, the performance of the proposed EPSANet outperforms most of the state-of-the-art channel attention methods. As compared to the SENet-50, the Top-1 accuracy is improved by 1.93 % on ImageNet dataset, a larger margin of +2.7 box AP for object detection and an improvement of +1.7 mask AP for instance segmentation by using the Mask-RCNN on MS-COCO dataset are obtained. Our source code is available at:https://github.com/murufeng/EPSANet.