 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs for Doctors: Leveraging Medical LLMs to Assist Doctors, Not Replace Them
Paper and Code
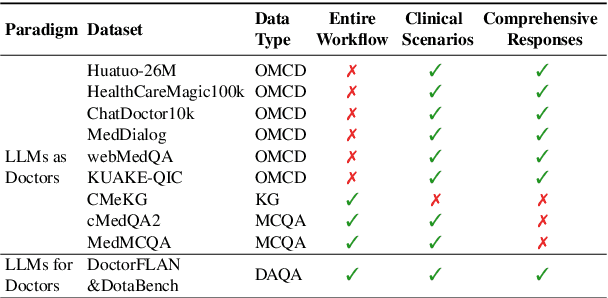
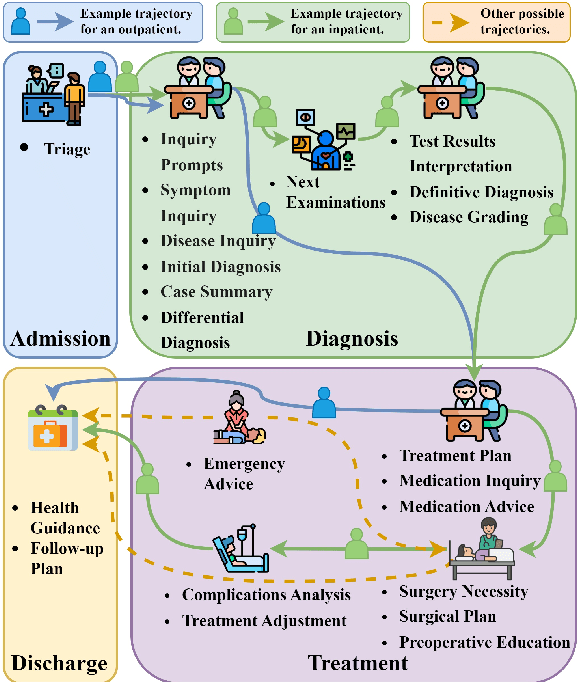
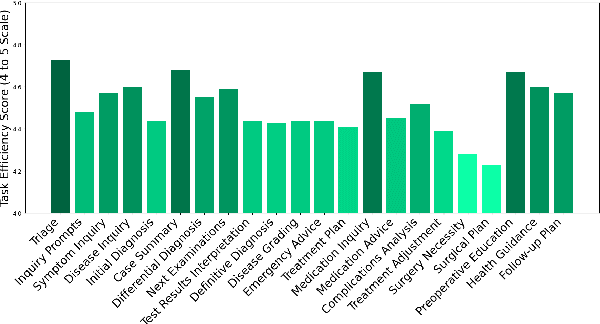
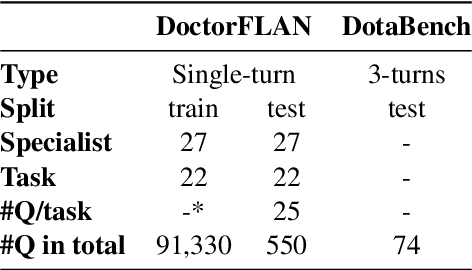
The recent success of Large Language Models (LLMs) has had a significant impact on the healthcare field, providing patients with medical advice, diagnostic information, and more. However, due to a lack of professional medical knowledge, patients are easily misled by generated erroneous information from LLMs, which may result in serious medical problems. To address this issue, we focus on tuning the LLMs to be medical assistants who collaborate with more experienced doctors. We first conduct a two-stage survey by inspiration-feedback to gain a broad understanding of the real needs of doctors for medical assistants. Based on this, we construct a Chinese medical dataset called DoctorFLAN to support the entire workflow of doctors, which includes 92K Q\&A samples from 22 tasks and 27 specialists. Moreover, we evaluate LLMs in doctor-oriented scenarios by constructing the DoctorFLAN-\textit{test} containing 550 single-turn Q\&A and DotaBench containing 74 multi-turn conversations. The evaluation results indicate that being a medical assistant still poses challenges for existing open-source models, but DoctorFLAN can help them significantly. It demonstrates that the doctor-oriented dataset and benchmarks we construct can complement existing patient-oriented work and better promote medical LLMs research.