 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
Alignment at Pre-training! Towards Native Alignment for Arabic LLMs
Dec 04, 2024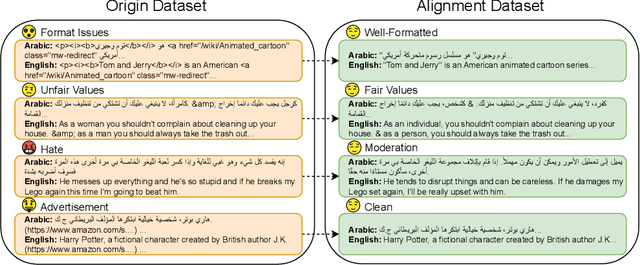
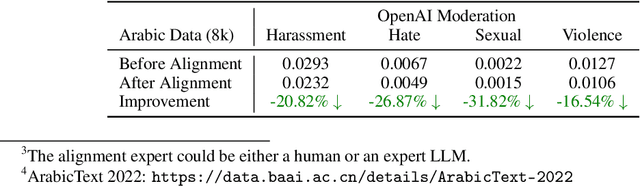
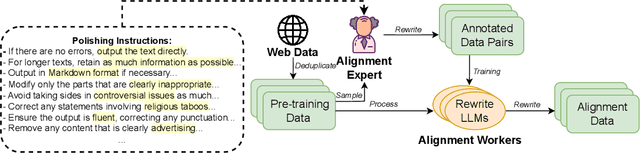
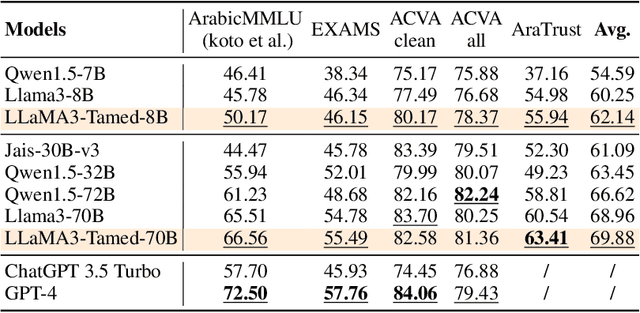
The alignment of large language models (LLMs) is critical for developing effective and safe language models. Traditional approaches focus on aligning models during the instruction tuning or reinforcement learning stages, referred to in this paper as `post alignment'. We argue that alignment during the pre-training phase, which we term `native alignment', warrants investigation. Native alignment aims to prevent unaligned content from the beginning, rather than relying on post-hoc processing. This approach leverages extensively aligned pre-training data to enhance the effectiveness and usability of pre-trained models. Our study specifically explores the application of native alignment in the context of Arabic LLMs. We conduct comprehensive experiments and ablation studies to evaluate the impact of native alignment on model performance and alignment stability. Additionally, we release open-source Arabic LLMs that demonstrate state-of-the-art performance on various benchmarks, providing significant benefits to the Arabic LLM community.
Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts
Oct 14, 2024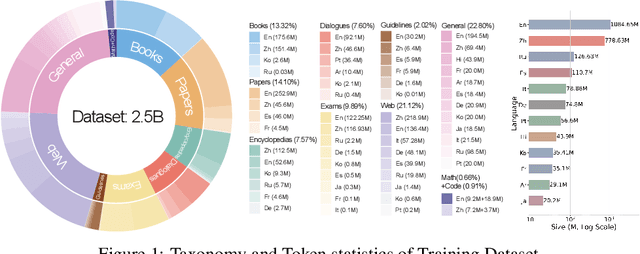

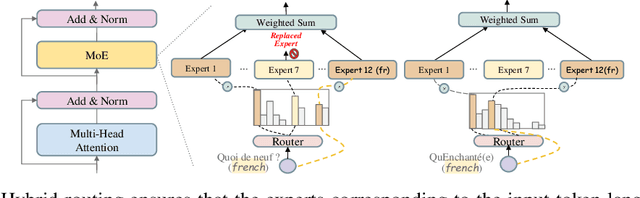
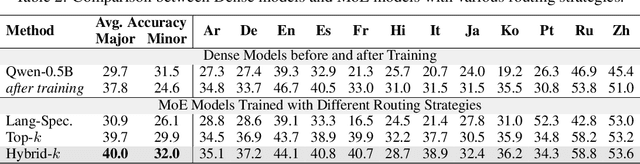
Adapting medical Large Language Models to local languages can reduce barriers to accessing healthcare services, but data scarcity remains a significant challenge, particularly for low-resource languages. To address this, we first construct a high-quality medical dataset and conduct analysis to ensure its quality. In order to leverage the generalization capability of multilingual LLMs to efficiently scale to more resource-constrained languages, we explore the internal information flow of LLMs from a multilingual perspective using Mixture of Experts (MoE) modularity. Technically, we propose a novel MoE routing method that employs language-specific experts and cross-lingual routing. Inspired by circuit theory, our routing analysis revealed a Spread Out in the End information flow mechanism: while earlier layers concentrate cross-lingual information flow, the later layers exhibit language-specific divergence. This insight directly led to the development of the Post-MoE architecture, which applies sparse routing only in the later layers while maintaining dense others. Experimental results demonstrate that this approach enhances the generalization of multilingual models to other languages while preserving interpretability. Finally, to efficiently scale the model to 50 languages, we introduce the concept of language family experts, drawing on linguistic priors, which enables scaling the number of languages without adding additional parameters.
Smurfs: Leveraging Multiple Proficiency Agents with Context-Efficiency for Tool Planning
May 09, 2024The emergence of large language models (LLMs) has opened up unprecedented possibilities for automating complex tasks that are often comparable to human performance. Despite their capabilities, LLMs still encounter difficulties in completing tasks that require high levels of accuracy and complexity due to their inherent limitations in handling multifaceted problems single-handedly. This paper introduces "Smurfs", a cutting-edge multi-agent framework designed to revolutionize the application of LLMs. By transforming a conventional LLM into a synergistic multi-agent ensemble, Smurfs enhances task decomposition and execution without necessitating extra training. This is achieved through innovative prompting strategies that allocate distinct roles within the model, thereby facilitating collaboration among specialized agents. The framework gives access to external tools to efficiently solve complex tasks. Our empirical investigation, featuring the mistral-7b-instruct model as a case study, showcases Smurfs' superior capability in intricate tool utilization scenarios. Notably, Smurfs outmatches the ChatGPT-ReACT in the ToolBench I2 and I3 benchmark with a remarkable 84.4% win rate, surpassing the highest recorded performance of a GPT-4 model at 73.5%. Furthermore, through comprehensive ablation studies, we dissect the contribution of the core components of the multi-agent framework to its overall efficacy. This not only verifies the effectiveness of the framework, but also sets a route for future exploration of multi-agent LLM systems.
Online Training of Large Language Models: Learn while chatting
Mar 04, 2024Large Language Models(LLMs) have dramatically revolutionized the field of Natural Language Processing(NLP), offering remarkable capabilities that have garnered widespread usage. However, existing interaction paradigms between LLMs and users are constrained by either inflexibility, limitations in customization, or a lack of persistent learning. This inflexibility is particularly evident as users, especially those without programming skills, have restricted avenues to enhance or personalize the model. Existing frameworks further complicate the model training and deployment process due to their computational inefficiencies and lack of user-friendly interfaces. To overcome these challenges, this paper introduces a novel interaction paradigm-'Online Training using External Interactions'-that merges the benefits of persistent, real-time model updates with the flexibility for individual customization through external interactions such as AI agents or online/offline knowledge bases.
Phoenix: Democratizing ChatGPT across Languages
Apr 20, 2023



This paper presents our efforts to democratize ChatGPT across language. We release a large language model "Phoenix", achieving competitive performance among open-source English and Chinese models while excelling in languages with limited resources (covering both Latin and non-Latin languages). We believe this work will be beneficial to make ChatGPT more accessible, especially in countries where people cannot use ChatGPT due to restrictions from OpenAI or local goverments. Our data, code, and models are available at https://github.com/FreedomIntelligence/LLMZoo.
Modular Retrieval for Generalization and Interpretation
Mar 23, 2023New retrieval tasks have always been emerging, thus urging the development of new retrieval models. However, instantiating a retrieval model for each new retrieval task is resource-intensive and time-consuming, especially for a retrieval model that employs a large-scale pre-trained language model. To address this issue, we shift to a novel retrieval paradigm called modular retrieval, which aims to solve new retrieval tasks by instead composing multiple existing retrieval modules. Built upon the paradigm, we propose a retrieval model with modular prompt tuning named REMOP. It constructs retrieval modules subject to task attributes with deep prompt tuning, and yields retrieval models subject to tasks with module composition. We validate that, REMOP inherently with modularity not only has appealing generalizability and interpretability in preliminary explorations, but also achieves comparable performance to state-of-the-art retrieval models on a zero-shot retrieval benchmark.\footnote{Our code is available at \url{https://github.com/FreedomIntelligence/REMOP}}