 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts
Oct 14, 2024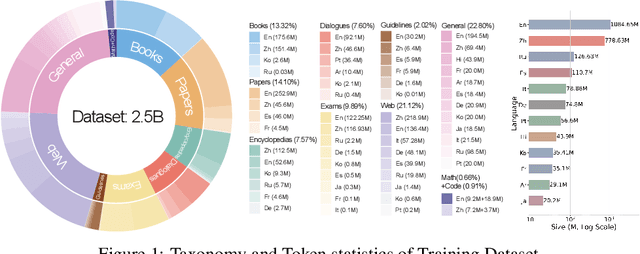

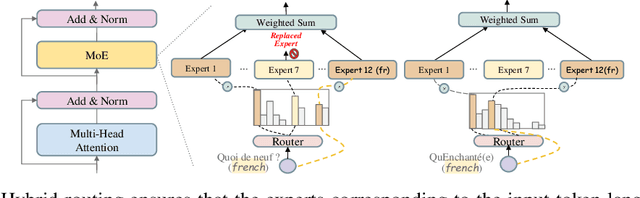
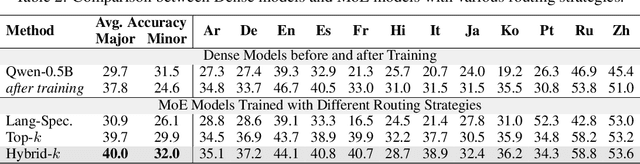
Adapting medical Large Language Models to local languages can reduce barriers to accessing healthcare services, but data scarcity remains a significant challenge, particularly for low-resource languages. To address this, we first construct a high-quality medical dataset and conduct analysis to ensure its quality. In order to leverage the generalization capability of multilingual LLMs to efficiently scale to more resource-constrained languages, we explore the internal information flow of LLMs from a multilingual perspective using Mixture of Experts (MoE) modularity. Technically, we propose a novel MoE routing method that employs language-specific experts and cross-lingual routing. Inspired by circuit theory, our routing analysis revealed a Spread Out in the End information flow mechanism: while earlier layers concentrate cross-lingual information flow, the later layers exhibit language-specific divergence. This insight directly led to the development of the Post-MoE architecture, which applies sparse routing only in the later layers while maintaining dense others. Experimental results demonstrate that this approach enhances the generalization of multilingual models to other languages while preserving interpretability. Finally, to efficiently scale the model to 50 languages, we introduce the concept of language family experts, drawing on linguistic priors, which enables scaling the number of languages without adding additional parameters.
From fat droplets to floating forests: cross-domain transfer learning using a PatchGAN-based segmentation model
Nov 08, 2022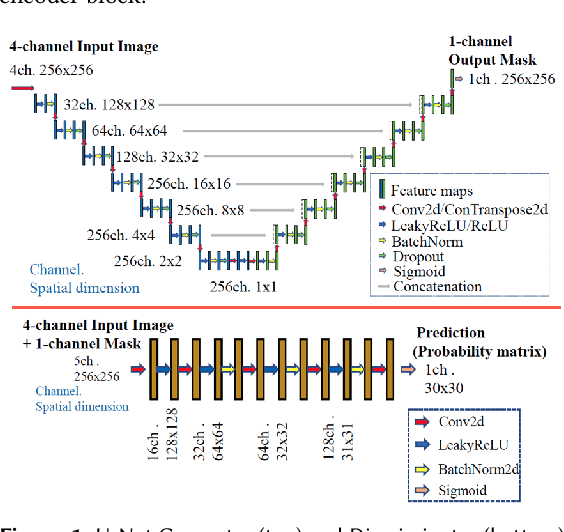

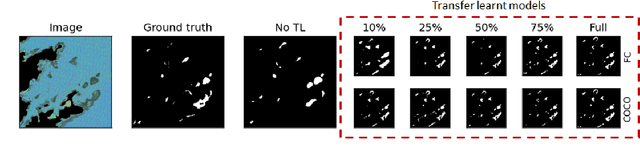
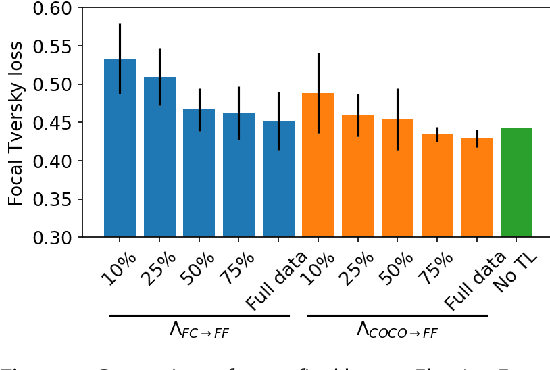
Many scientific domains gather sufficient labels to train machine algorithms through human-in-the-loop techniques provided by the Zooniverse.org citizen science platform. As the range of projects, task types and data rates increase, acceleration of model training is of paramount concern to focus volunteer effort where most needed. The application of Transfer Learning (TL) between Zooniverse projects holds promise as a solution. However, understanding the effectiveness of TL approaches that pretrain on large-scale generic image sets vs. images with similar characteristics possibly from similar tasks is an open challenge. We apply a generative segmentation model on two Zooniverse project-based data sets: (1) to identify fat droplets in liver cells (FatChecker; FC) and (2) the identification of kelp beds in satellite images (Floating Forests; FF) through transfer learning from the first project. We compare and contrast its performance with a TL model based on the COCO image set, and subsequently with baseline counterparts. We find that both the FC and COCO TL models perform better than the baseline cases when using >75% of the original training sample size. The COCO-based TL model generally performs better than the FC-based one, likely due to its generalized features. Our investigations provide important insights into usage of TL approaches on multi-domain data hosted across different Zooniverse projects, enabling future projects to accelerate task completion.
Constrained Langevin Algorithms with L-mixing External Random Variables
May 27, 2022
Langevin algorithms are gradient descent methods augmented with additive noise, and are widely used in Markov Chain Monte Carlo (MCMC) sampling, optimization, and learning. In recent years, the non-asymptotic analysis of Langevin algorithms for non-convex optimization learning has been extensively explored. For constrained problems with non-convex losses over compact convex domain in the case of IID data variables, Langevin algorithm achieves a deviation of $O(T^{-1/4} (\log T)^{1/2})$ from its target distribution [22]. In this paper, we obtain a deviation of $O(T^{-1/2} \log T)$ in $1$-Wasserstein distance for non-convex losses with $L$-mixing data variables and polyhedral constraints (which are not necessarily bounded). This deviation indicates that our convergence rate is faster than those in the previous works on constrained Langevin algorithms for non-convex optimization.