 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuatuo-26M, a Large-scale Chinese Medical QA Dataset
Paper and Code

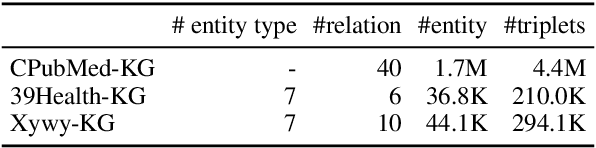

In this paper, we release a largest ever medical Question Answering (QA) dataset with 26 million QA pairs. We benchmark many existing approaches in our dataset in terms of both retrieval and generation. Experimental results show that the existing models perform far lower than expected and the released dataset is still challenging in the pre-trained language model era. Moreover, we also experimentally show the benefit of the proposed dataset in many aspects: (i) trained models for other QA datasets in a zero-shot fashion; and (ii) as external knowledge for retrieval-augmented generation (RAG); and (iii) improving existing pre-trained language models by using the QA pairs as a pre-training corpus in continued training manner. We believe that this dataset will not only contribute to medical research but also facilitate both the patients and clinical doctors. See \url{https://github.com/FreedomIntelligence/Huatuo-26M}.