 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlenderLLM: Training Large Language Models for Computer-Aided Design with Self-improvement
Dec 16, 2024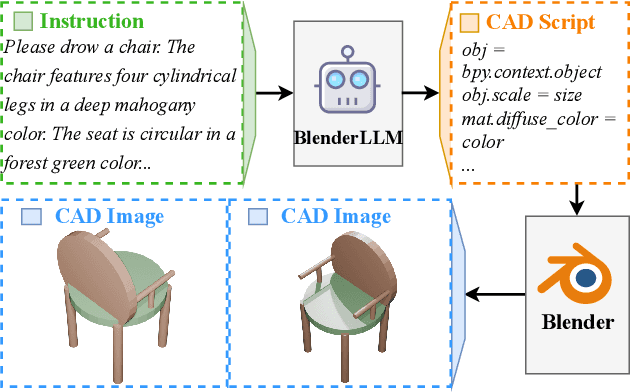
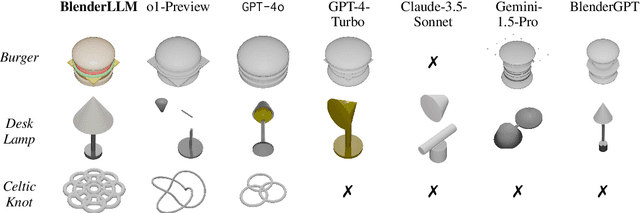
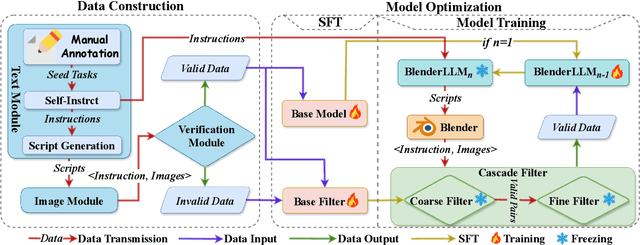
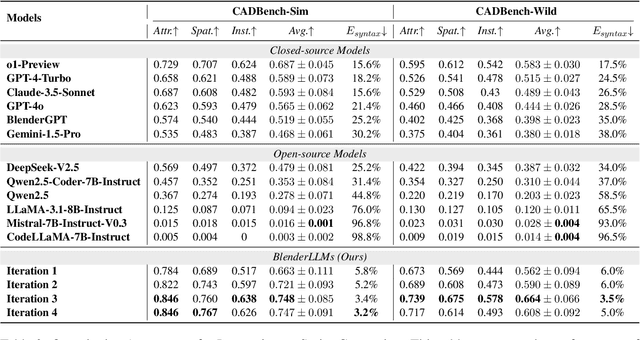
The application of Large Language Models (LLMs) in Computer-Aided Design (CAD) remains an underexplored area, despite their remarkable advancements in other domains. In this paper, we present BlenderLLM, a novel framework for training LLMs specifically for CAD tasks leveraging a self-improvement methodology. To support this, we developed a bespoke training dataset, BlendNet, and introduced a comprehensive evaluation suite, CADBench. Our results reveal that existing models demonstrate significant limitations in generating accurate CAD scripts. However, through minimal instruction-based fine-tuning and iterative self-improvement, BlenderLLM significantly surpasses these models in both functionality and accuracy of CAD script generation. This research establishes a strong foundation for the application of LLMs in CAD while demonstrating the transformative potential of self-improving models in advancing CAD automation. We encourage further exploration and adoption of these methodologies to drive innovation in the field. The dataset, model, benchmark, and source code are publicly available at https://github.com/FreedomIntelligence/BlenderLLM
Uncertainty Quantification for Clinical Outcome Predictions with (Large) Language Models
Nov 05, 2024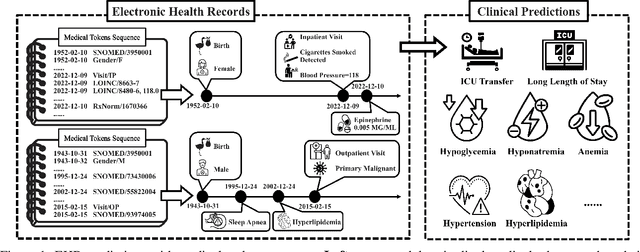



To facilitate healthcare delivery, language models (LMs) have significant potential for clinical prediction tasks using electronic health records (EHRs). However, in these high-stakes applications, unreliable decisions can result in high costs due to compromised patient safety and ethical concerns, thus increasing the need for good uncertainty modeling of automated clinical predictions. To address this, we consider the uncertainty quantification of LMs for EHR tasks in white- and black-box settings. We first quantify uncertainty in white-box models, where we can access model parameters and output logits. We show that an effective reduction of model uncertainty can be achieved by using the proposed multi-tasking and ensemble methods in EHRs. Continuing with this idea, we extend our approach to black-box settings, including popular proprietary LMs such as GPT-4. We validate our framework using longitudinal clinical data from more than 6,000 patients in ten clinical prediction tasks. Results show that ensembling methods and multi-task prediction prompts reduce uncertainty across different scenarios. These findings increase the transparency of the model in white-box and black-box settings, thus advancing reliable AI healthcare.
MMVR: Millimeter-wave Multi-View Radar Dataset and Benchmark for Indoor Perception
Jun 15, 2024



Compared with an extensive list of automotive radar datasets that support autonomous driving, indoor radar datasets are scarce at a smaller scale in the format of low-resolution radar point clouds and usually under an open-space single-room setting. In this paper, we scale up indoor radar data collection using multi-view high-resolution radar heatmap in a multi-day, multi-room, and multi-subject setting, with an emphasis on the diversity of environment and subjects. Referred to as the millimeter-wave multi-view radar (MMVR) dataset, it consists of $345$K multi-view radar frames collected from $25$ human subjects over $6$ different rooms, $446$K annotated bounding boxes/segmentation instances, and $7.59$ million annotated keypoints to support three major perception tasks of object detection, pose estimation, and instance segmentation, respectively. For each task, we report performance benchmarks under two protocols: a single subject in an open space and multiple subjects in several cluttered rooms with two data splits: random split and cross-environment split over $395$ 1-min data segments. We anticipate that MMVR facilitates indoor radar perception development for indoor vehicle (robot/humanoid) navigation, building energy management, and elderly care for better efficiency, user experience, and safety.
Rich Human Feedback for Text-to-Image Generation
Dec 15, 2023
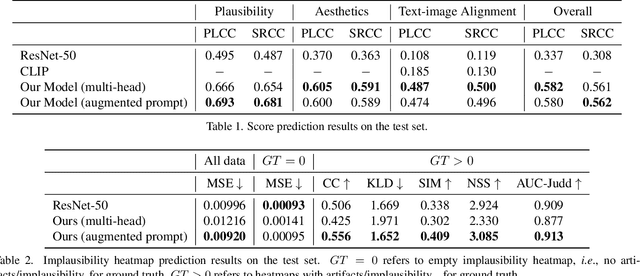
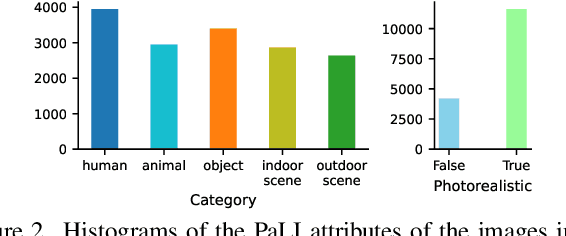
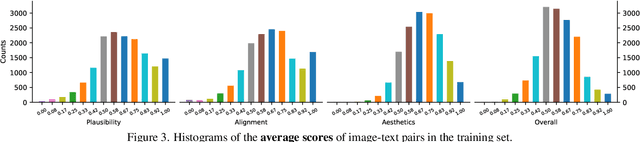
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).
UniAR: Unifying Human Attention and Response Prediction on Visual Content
Dec 15, 2023Progress in human behavior modeling involves understanding both implicit, early-stage perceptual behavior such as human attention and explicit, later-stage behavior such as subjective ratings/preferences. Yet, most prior research has focused on modeling implicit and explicit human behavior in isolation. Can we build a unified model of human attention and preference behavior that reliably works across diverse types of visual content? Such a model would enable predicting subjective feedback such as overall satisfaction or aesthetic quality ratings, along with the underlying human attention or interaction heatmaps and viewing order, enabling designers and content-creation models to optimize their creation for human-centric improvements. In this paper, we propose UniAR -- a unified model that predicts both implicit and explicit human behavior across different types of visual content. UniAR leverages a multimodal transformer, featuring distinct prediction heads for each facet, and predicts attention heatmap, scanpath or viewing order, and subjective rating/preference. We train UniAR on diverse public datasets spanning natural images, web pages and graphic designs, and achieve leading performance on multiple benchmarks across different image domains and various behavior modeling tasks. Potential applications include providing instant feedback on the effectiveness of UIs/digital designs/images, and serving as a reward model to further optimize design/image creation.
Dual Node and Edge Fairness-Aware Graph Partition
Jun 16, 2023



Fair graph partition of social networks is a crucial step toward ensuring fair and non-discriminatory treatments in unsupervised user analysis. Current fair partition methods typically consider node balance, a notion pursuing a proportionally balanced number of nodes from all demographic groups, but ignore the bias induced by imbalanced edges in each cluster. To address this gap, we propose a notion edge balance to measure the proportion of edges connecting different demographic groups in clusters. We analyze the relations between node balance and edge balance, then with line graph transformations, we propose a co-embedding framework to learn dual node and edge fairness-aware representations for graph partition. We validate our framework through several social network datasets and observe balanced partition in terms of both nodes and edges along with good utility. Moreover, we demonstrate our fair partition can be used as pseudo labels to facilitate graph neural networks to behave fairly in node classification and link prediction tasks.
Learning Antidote Data to Individual Unfairness
Nov 29, 2022Fairness is an essential factor for machine learning systems deployed in high-stake applications. Among all fairness notions, individual fairness, following a consensus that `similar individuals should be treated similarly,' is a vital notion to guarantee fair treatment for individual cases. Previous methods typically characterize individual fairness as a prediction-invariant problem when perturbing sensitive attributes, and solve it by adopting the Distributionally Robust Optimization (DRO) paradigm. However, adversarial perturbations along a direction covering sensitive information do not consider the inherent feature correlations or innate data constraints, and thus mislead the model to optimize at off-manifold and unrealistic samples. In light of this, we propose a method to learn and generate antidote data that approximately follows the data distribution to remedy individual unfairness. These on-manifold antidote data can be used through a generic optimization procedure with original training data, resulting in a pure pre-processing approach to individual unfairness, or can also fit well with the in-processing DRO paradigm. Through extensive experiments, we demonstrate our antidote data resists individual unfairness at a minimal or zero cost to the model's predictive utility.
Characterizing the Influence of Graph Elements
Oct 14, 2022

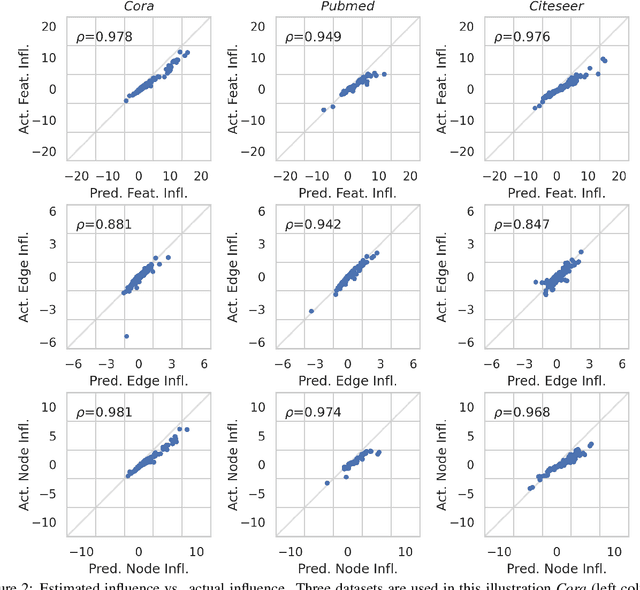
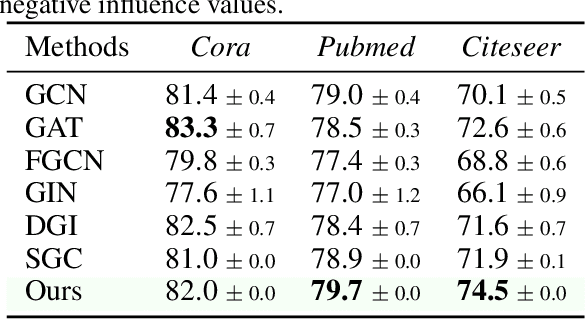
Influence function, a method from robust statistics, measures the changes of model parameters or some functions about model parameters concerning the removal or modification of training instances. It is an efficient and useful post-hoc method for studying the interpretability of machine learning models without the need for expensive model re-training. Recently, graph convolution networks (GCNs), which operate on graph data, have attracted a great deal of attention. However, there is no preceding research on the influence functions of GCNs to shed light on the effects of removing training nodes/edges from an input graph. Since the nodes/edges in a graph are interdependent in GCNs, it is challenging to derive influence functions for GCNs. To fill this gap, we started with the simple graph convolution (SGC) model that operates on an attributed graph and formulated an influence function to approximate the changes in model parameters when a node or an edge is removed from an attributed graph. Moreover, we theoretically analyzed the error bound of the estimated influence of removing an edge. We experimentally validated the accuracy and effectiveness of our influence estimation function. In addition, we showed that the influence function of an SGC model could be used to estimate the impact of removing training nodes/edges on the test performance of the SGC without re-training the model. Finally, we demonstrated how to use influence functions to guide the adversarial attacks on GCNs effectively.
Robust Fair Clustering: A Novel Fairness Attack and Defense Framework
Oct 04, 2022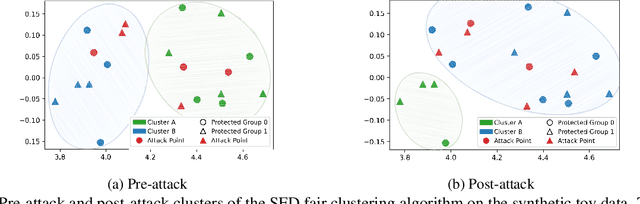
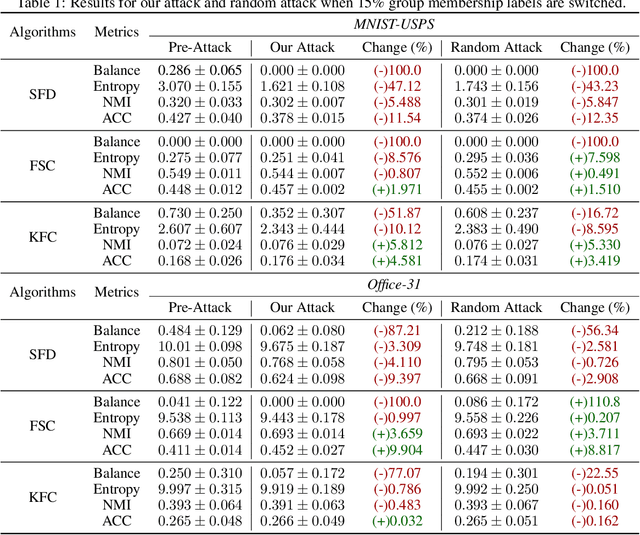

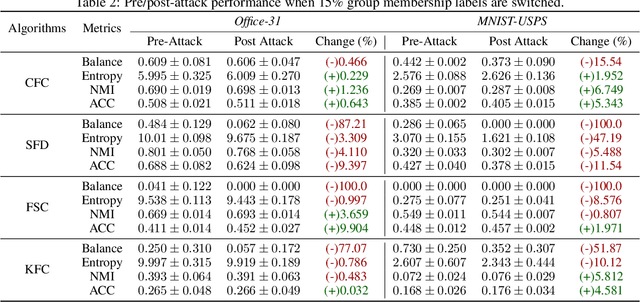
Clustering algorithms are widely used in many societal resource allocation applications, such as loan approvals and candidate recruitment, among others, and hence, biased or unfair model outputs can adversely impact individuals that rely on these applications. To this end, many fair clustering approaches have been recently proposed to counteract this issue. Due to the potential for significant harm, it is essential to ensure that fair clustering algorithms provide consistently fair outputs even under adversarial influence. However, fair clustering algorithms have not been studied from an adversarial attack perspective. In contrast to previous research, we seek to bridge this gap and conduct a robustness analysis against fair clustering by proposing a novel black-box fairness attack. Through comprehensive experiments, we find that state-of-the-art models are highly susceptible to our attack as it can reduce their fairness performance significantly. Finally, we propose Consensus Fair Clustering (CFC), the first robust fair clustering approach that transforms consensus clustering into a fair graph partitioning problem, and iteratively learns to generate fair cluster outputs. Experimentally, we observe that CFC is highly robust to the proposed attack and is thus a truly robust fair clustering alternative.
Exploiting Temporal Relations on Radar Perception for Autonomous Driving
Apr 03, 2022
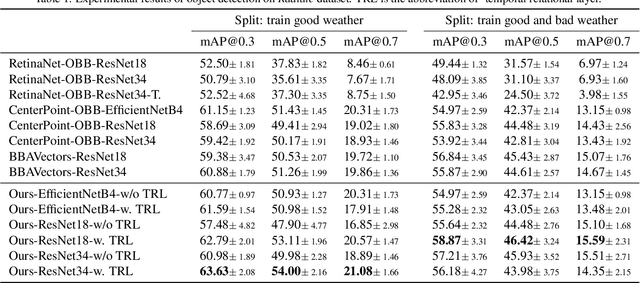
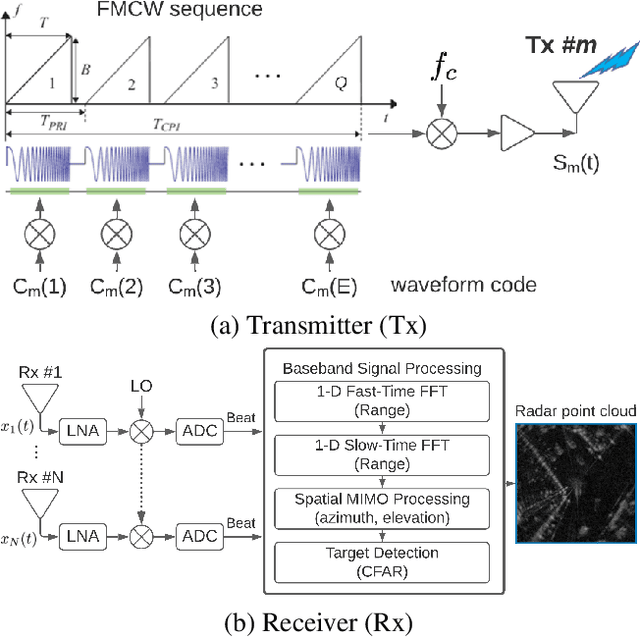

We consider the object recognition problem in autonomous driving using automotive radar sensors. Comparing to Lidar sensors, radar is cost-effective and robust in all-weather conditions for perception in autonomous driving. However, radar signals suffer from low angular resolution and precision in recognizing surrounding objects. To enhance the capacity of automotive radar, in this work, we exploit the temporal information from successive ego-centric bird-eye-view radar image frames for radar object recognition. We leverage the consistency of an object's existence and attributes (size, orientation, etc.), and propose a temporal relational layer to explicitly model the relations between objects within successive radar images. In both object detection and multiple object tracking, we show the superiority of our method compared to several baseline approaches.