 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Uncertainty Quantification for Clinical Outcome Predictions with (Large) Language Models
Nov 05, 2024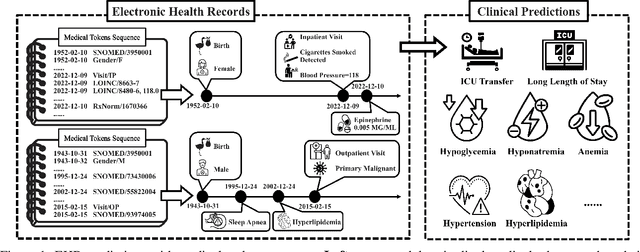



To facilitate healthcare delivery, language models (LMs) have significant potential for clinical prediction tasks using electronic health records (EHRs). However, in these high-stakes applications, unreliable decisions can result in high costs due to compromised patient safety and ethical concerns, thus increasing the need for good uncertainty modeling of automated clinical predictions. To address this, we consider the uncertainty quantification of LMs for EHR tasks in white- and black-box settings. We first quantify uncertainty in white-box models, where we can access model parameters and output logits. We show that an effective reduction of model uncertainty can be achieved by using the proposed multi-tasking and ensemble methods in EHRs. Continuing with this idea, we extend our approach to black-box settings, including popular proprietary LMs such as GPT-4. We validate our framework using longitudinal clinical data from more than 6,000 patients in ten clinical prediction tasks. Results show that ensembling methods and multi-task prediction prompts reduce uncertainty across different scenarios. These findings increase the transparency of the model in white-box and black-box settings, thus advancing reliable AI healthcare.
Question Rephrasing for Quantifying Uncertainty in Large Language Models: Applications in Molecular Chemistry Tasks
Aug 07, 2024Uncertainty quantification enables users to assess the reliability of responses generated by large language models (LLMs). We present a novel Question Rephrasing technique to evaluate the input uncertainty of LLMs, which refers to the uncertainty arising from equivalent variations of the inputs provided to LLMs. This technique is integrated with sampling methods that measure the output uncertainty of LLMs, thereby offering a more comprehensive uncertainty assessment. We validated our approach on property prediction and reaction prediction for molecular chemistry tasks.
GlycoNMR: Dataset and benchmarks for NMR chemical shift prediction of carbohydrates with graph neural networks
Nov 30, 2023



Molecular representation learning (MRL) is a powerful tool for bridging the gap between machine learning and chemical sciences, as it converts molecules into numerical representations while preserving their chemical features. These encoded representations serve as a foundation for various downstream biochemical studies, including property prediction and drug design. MRL has had great success with proteins and general biomolecule datasets. Yet, in the growing sub-field of glycoscience (the study of carbohydrates, where longer carbohydrates are also called glycans), MRL methods have been barely explored. This under-exploration can be primarily attributed to the limited availability of comprehensive and well-curated carbohydrate-specific datasets and a lack of Machine learning (ML) pipelines specifically tailored to meet the unique problems presented by carbohydrate data. Since interpreting and annotating carbohydrate-specific data is generally more complicated than protein data, domain experts are usually required to get involved. The existing MRL methods, predominately optimized for proteins and small biomolecules, also cannot be directly used in carbohydrate applications without special modifications. To address this challenge, accelerate progress in glycoscience, and enrich the data resources of the MRL community, we introduce GlycoNMR. GlycoNMR contains two laboriously curated datasets with 2,609 carbohydrate structures and 211,543 annotated nuclear magnetic resonance (NMR) chemical shifts for precise atomic-level prediction. We tailored carbohydrate-specific features and adapted existing MRL models to tackle this problem effectively. For illustration, we benchmark four modified MRL models on our new datasets.
Characterizing the Influence of Graph Elements
Oct 14, 2022

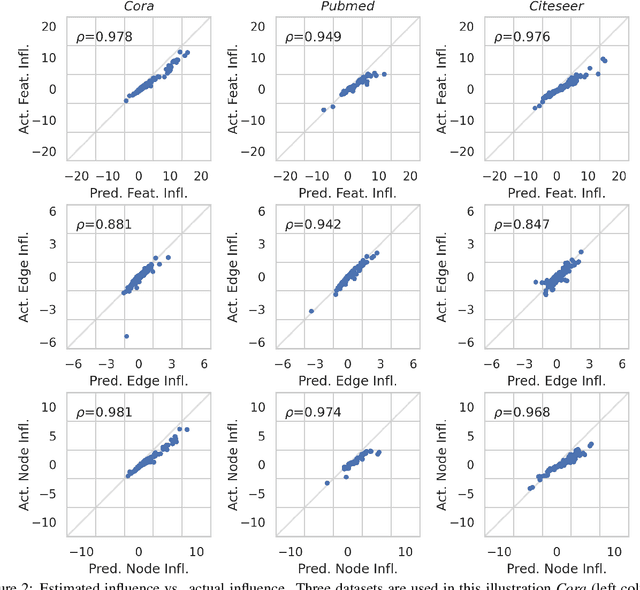
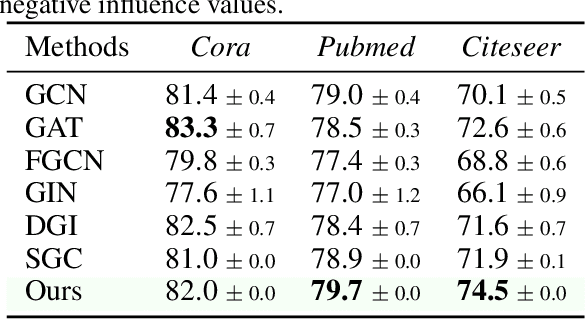
Influence function, a method from robust statistics, measures the changes of model parameters or some functions about model parameters concerning the removal or modification of training instances. It is an efficient and useful post-hoc method for studying the interpretability of machine learning models without the need for expensive model re-training. Recently, graph convolution networks (GCNs), which operate on graph data, have attracted a great deal of attention. However, there is no preceding research on the influence functions of GCNs to shed light on the effects of removing training nodes/edges from an input graph. Since the nodes/edges in a graph are interdependent in GCNs, it is challenging to derive influence functions for GCNs. To fill this gap, we started with the simple graph convolution (SGC) model that operates on an attributed graph and formulated an influence function to approximate the changes in model parameters when a node or an edge is removed from an attributed graph. Moreover, we theoretically analyzed the error bound of the estimated influence of removing an edge. We experimentally validated the accuracy and effectiveness of our influence estimation function. In addition, we showed that the influence function of an SGC model could be used to estimate the impact of removing training nodes/edges on the test performance of the SGC without re-training the model. Finally, we demonstrated how to use influence functions to guide the adversarial attacks on GCNs effectively.