 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for Clinical Outcome Predictions with (Large) Language Models
Paper and Code
Nov 05, 2024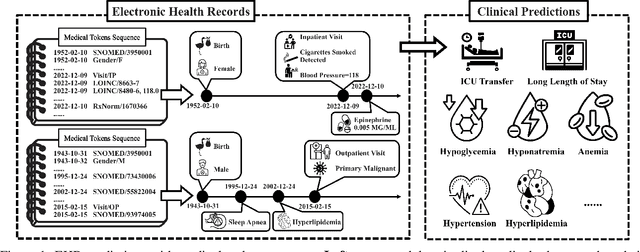



To facilitate healthcare delivery, language models (LMs) have significant potential for clinical prediction tasks using electronic health records (EHRs). However, in these high-stakes applications, unreliable decisions can result in high costs due to compromised patient safety and ethical concerns, thus increasing the need for good uncertainty modeling of automated clinical predictions. To address this, we consider the uncertainty quantification of LMs for EHR tasks in white- and black-box settings. We first quantify uncertainty in white-box models, where we can access model parameters and output logits. We show that an effective reduction of model uncertainty can be achieved by using the proposed multi-tasking and ensemble methods in EHRs. Continuing with this idea, we extend our approach to black-box settings, including popular proprietary LMs such as GPT-4. We validate our framework using longitudinal clinical data from more than 6,000 patients in ten clinical prediction tasks. Results show that ensembling methods and multi-task prediction prompts reduce uncertainty across different scenarios. These findings increase the transparency of the model in white-box and black-box settings, thus advancing reliable AI healthcare.