 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETR: Multi-View Radar Detection Transformer for Indoor Perception
Nov 15, 2024



Indoor radar perception has seen rising interest due to affordable costs driven by emerging automotive imaging radar developments and the benefits of reduced privacy concerns and reliability under hazardous conditions (e.g., fire and smoke). However, existing radar perception pipelines fail to account for distinctive characteristics of the multi-view radar setting. In this paper, we propose Radar dEtection TRansformer (RETR), an extension of the popular DETR architecture, tailored for multi-view radar perception. RETR inherits the advantages of DETR, eliminating the need for hand-crafted components for object detection and segmentation in the image plane. More importantly, RETR incorporates carefully designed modifications such as 1) depth-prioritized feature similarity via a tunable positional encoding (TPE); 2) a tri-plane loss from both radar and camera coordinates; and 3) a learnable radar-to-camera transformation via reparameterization, to account for the unique multi-view radar setting. Evaluated on two indoor radar perception datasets, our approach outperforms existing state-of-the-art methods by a margin of 15.38+ AP for object detection and 11.77+ IoU for instance segmentation, respectively.
MMVR: Millimeter-wave Multi-View Radar Dataset and Benchmark for Indoor Perception
Jun 15, 2024



Compared with an extensive list of automotive radar datasets that support autonomous driving, indoor radar datasets are scarce at a smaller scale in the format of low-resolution radar point clouds and usually under an open-space single-room setting. In this paper, we scale up indoor radar data collection using multi-view high-resolution radar heatmap in a multi-day, multi-room, and multi-subject setting, with an emphasis on the diversity of environment and subjects. Referred to as the millimeter-wave multi-view radar (MMVR) dataset, it consists of $345$K multi-view radar frames collected from $25$ human subjects over $6$ different rooms, $446$K annotated bounding boxes/segmentation instances, and $7.59$ million annotated keypoints to support three major perception tasks of object detection, pose estimation, and instance segmentation, respectively. For each task, we report performance benchmarks under two protocols: a single subject in an open space and multiple subjects in several cluttered rooms with two data splits: random split and cross-environment split over $395$ 1-min data segments. We anticipate that MMVR facilitates indoor radar perception development for indoor vehicle (robot/humanoid) navigation, building energy management, and elderly care for better efficiency, user experience, and safety.
Deep Learning on 3D Neural Fields
Dec 20, 2023



In recent years, Neural Fields (NFs) have emerged as an effective tool for encoding diverse continuous signals such as images, videos, audio, and 3D shapes. When applied to 3D data, NFs offer a solution to the fragmentation and limitations associated with prevalent discrete representations. However, given that NFs are essentially neural networks, it remains unclear whether and how they can be seamlessly integrated into deep learning pipelines for solving downstream tasks. This paper addresses this research problem and introduces nf2vec, a framework capable of generating a compact latent representation for an input NF in a single inference pass. We demonstrate that nf2vec effectively embeds 3D objects represented by the input NFs and showcase how the resulting embeddings can be employed in deep learning pipelines to successfully address various tasks, all while processing exclusively NFs. We test this framework on several NFs used to represent 3D surfaces, such as unsigned/signed distance and occupancy fields. Moreover, we demonstrate the effectiveness of our approach with more complex NFs that encompass both geometry and appearance of 3D objects such as neural radiance fields.
Neural Processing of Tri-Plane Hybrid Neural Fields
Oct 02, 2023
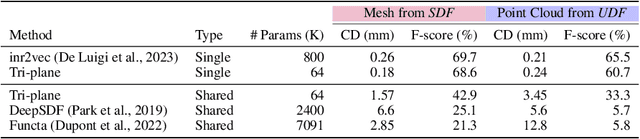
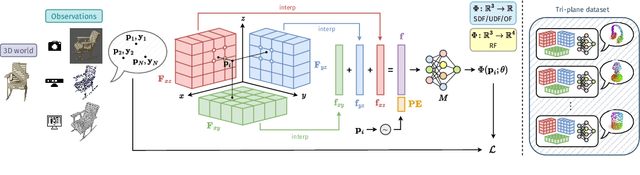

Driven by the appealing properties of neural fields for storing and communicating 3D data, the problem of directly processing them to address tasks such as classification and part segmentation has emerged and has been investigated in recent works. Early approaches employ neural fields parameterized by shared networks trained on the whole dataset, achieving good task performance but sacrificing reconstruction quality. To improve the latter, later methods focus on individual neural fields parameterized as large Multi-Layer Perceptrons (MLPs), which are, however, challenging to process due to the high dimensionality of the weight space, intrinsic weight space symmetries, and sensitivity to random initialization. Hence, results turn out significantly inferior to those achieved by processing explicit representations, e.g., point clouds or meshes. In the meantime, hybrid representations, in particular based on tri-planes, have emerged as a more effective and efficient alternative to realize neural fields, but their direct processing has not been investigated yet. In this paper, we show that the tri-plane discrete data structure encodes rich information, which can be effectively processed by standard deep-learning machinery. We define an extensive benchmark covering a diverse set of fields such as occupancy, signed/unsigned distance, and, for the first time, radiance fields. While processing a field with the same reconstruction quality, we achieve task performance far superior to frameworks that process large MLPs and, for the first time, almost on par with architectures handling explicit representations.
Exploiting the Complementarity of 2D and 3D Networks to Address Domain-Shift in 3D Semantic Segmentation
Apr 06, 2023
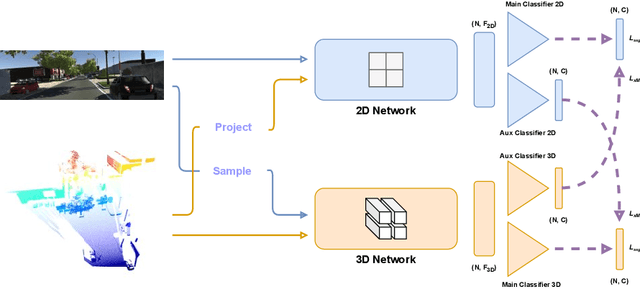

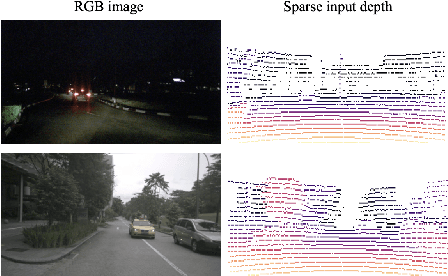
3D semantic segmentation is a critical task in many real-world applications, such as autonomous driving, robotics, and mixed reality. However, the task is extremely challenging due to ambiguities coming from the unstructured, sparse, and uncolored nature of the 3D point clouds. A possible solution is to combine the 3D information with others coming from sensors featuring a different modality, such as RGB cameras. Recent multi-modal 3D semantic segmentation networks exploit these modalities relying on two branches that process the 2D and 3D information independently, striving to maintain the strength of each modality. In this work, we first explain why this design choice is effective and then show how it can be improved to make the multi-modal semantic segmentation more robust to domain shift. Our surprisingly simple contribution achieves state-of-the-art performances on four popular multi-modal unsupervised domain adaptation benchmarks, as well as better results in a domain generalization scenario.
Deep Learning on Implicit Neural Representations of Shapes
Feb 10, 2023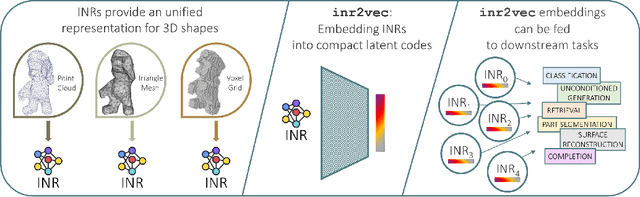

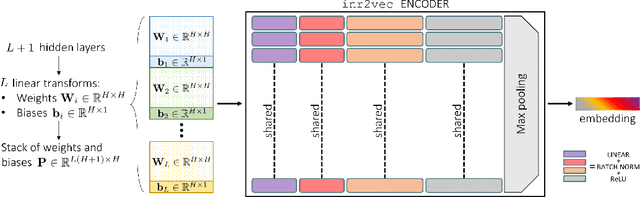

Implicit Neural Representations (INRs) have emerged in the last few years as a powerful tool to encode continuously a variety of different signals like images, videos, audio and 3D shapes. When applied to 3D shapes, INRs allow to overcome the fragmentation and shortcomings of the popular discrete representations used so far. Yet, considering that INRs consist in neural networks, it is not clear whether and how it may be possible to feed them into deep learning pipelines aimed at solving a downstream task. In this paper, we put forward this research problem and propose inr2vec, a framework that can compute a compact latent representation for an input INR in a single inference pass. We verify that inr2vec can embed effectively the 3D shapes represented by the input INRs and show how the produced embeddings can be fed into deep learning pipelines to solve several tasks by processing exclusively INRs.
Learning Good Features to Transfer Across Tasks and Domains
Jan 26, 2023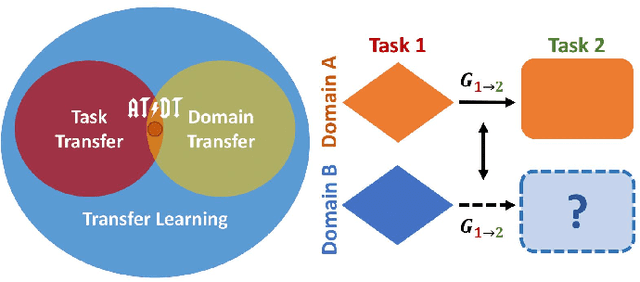

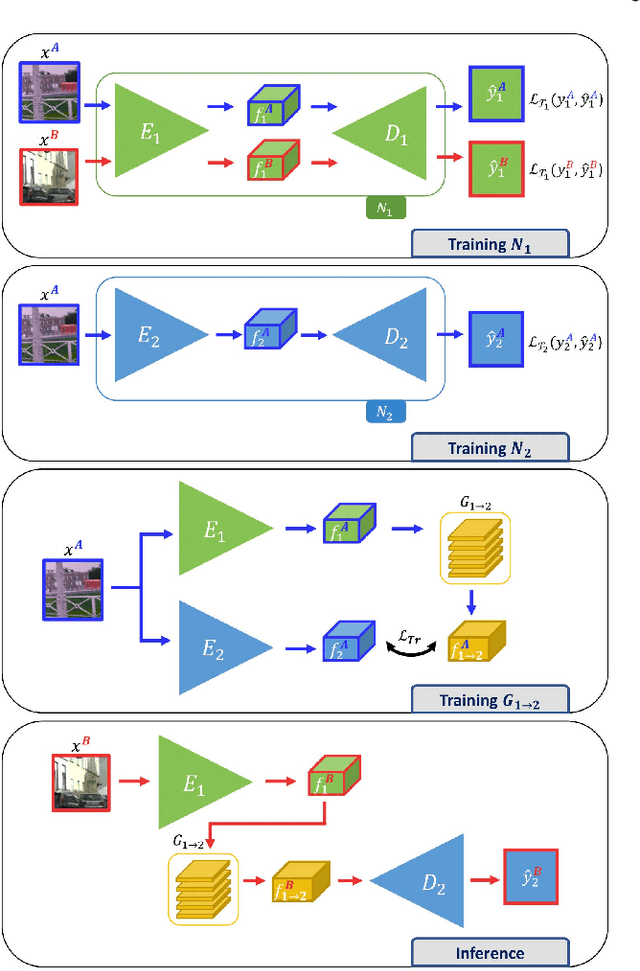
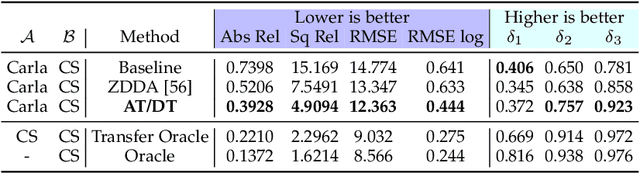
Availability of labelled data is the major obstacle to the deployment of deep learning algorithms for computer vision tasks in new domains. The fact that many frameworks adopted to solve different tasks share the same architecture suggests that there should be a way of reusing the knowledge learned in a specific setting to solve novel tasks with limited or no additional supervision. In this work, we first show that such knowledge can be shared across tasks by learning a mapping between task-specific deep features in a given domain. Then, we show that this mapping function, implemented by a neural network, is able to generalize to novel unseen domains. Besides, we propose a set of strategies to constrain the learned feature spaces, to ease learning and increase the generalization capability of the mapping network, thereby considerably improving the final performance of our framework. Our proposal obtains compelling results in challenging synthetic-to-real adaptation scenarios by transferring knowledge between monocular depth estimation and semantic segmentation tasks.
Self-Distillation for Unsupervised 3D Domain Adaptation
Oct 15, 2022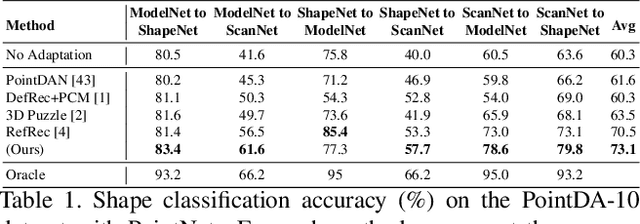
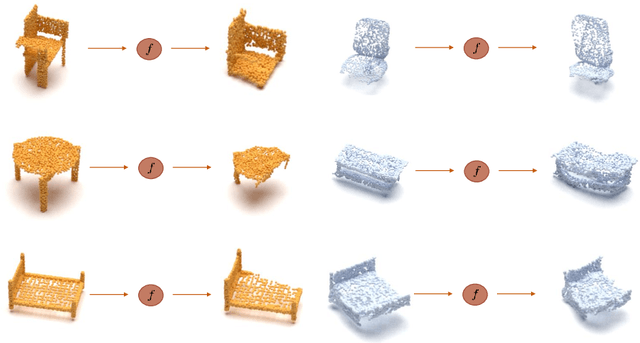

Point cloud classification is a popular task in 3D vision. However, previous works, usually assume that point clouds at test time are obtained with the same procedure or sensor as those at training time. Unsupervised Domain Adaptation (UDA) instead, breaks this assumption and tries to solve the task on an unlabeled target domain, leveraging only on a supervised source domain. For point cloud classification, recent UDA methods try to align features across domains via auxiliary tasks such as point cloud reconstruction, which however do not optimize the discriminative power in the target domain in feature space. In contrast, in this work, we focus on obtaining a discriminative feature space for the target domain enforcing consistency between a point cloud and its augmented version. We then propose a novel iterative self-training methodology that exploits Graph Neural Networks in the UDA context to refine pseudo-labels. We perform extensive experiments and set the new state-of-the-art in standard UDA benchmarks for point cloud classification. Finally, we show how our approach can be extended to more complex tasks such as part segmentation.
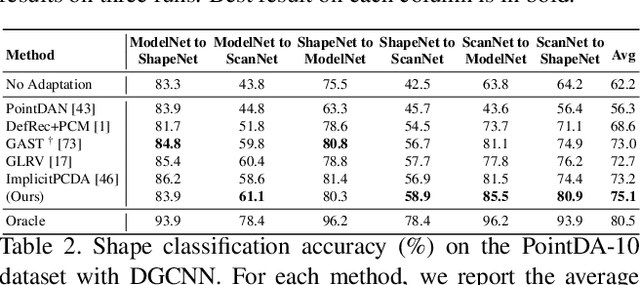
RefRec: Pseudo-labels Refinement via Shape Reconstruction for Unsupervised 3D Domain Adaptation
Oct 21, 2021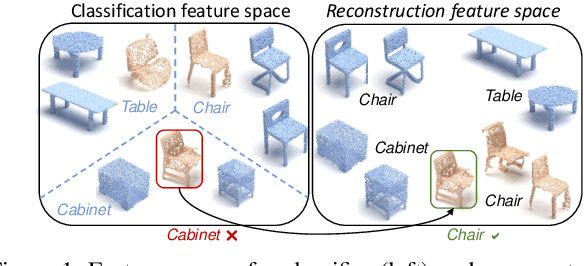



Unsupervised Domain Adaptation (UDA) for point cloud classification is an emerging research problem with relevant practical motivations. Reliance on multi-task learning to align features across domains has been the standard way to tackle it. In this paper, we take a different path and propose RefRec, the first approach to investigate pseudo-labels and self-training in UDA for point clouds. We present two main innovations to make self-training effective on 3D data: i) refinement of noisy pseudo-labels by matching shape descriptors that are learned by the unsupervised task of shape reconstruction on both domains; ii) a novel self-training protocol that learns domain-specific decision boundaries and reduces the negative impact of mislabelled target samples and in-domain intra-class variability. RefRec sets the new state of the art in both standard benchmarks used to test UDA for point cloud classification, showcasing the effectiveness of self-training for this important problem.
Plugging Self-Supervised Monocular Depth into Unsupervised Domain Adaptation for Semantic Segmentation
Oct 13, 2021



Although recent semantic segmentation methods have made remarkable progress, they still rely on large amounts of annotated training data, which are often infeasible to collect in the autonomous driving scenario. Previous works usually tackle this issue with Unsupervised Domain Adaptation (UDA), which entails training a network on synthetic images and applying the model to real ones while minimizing the discrepancy between the two domains. Yet, these techniques do not consider additional information that may be obtained from other tasks. Differently, we propose to exploit self-supervised monocular depth estimation to improve UDA for semantic segmentation. On one hand, we deploy depth to realize a plug-in component which can inject complementary geometric cues into any existing UDA method. We further rely on depth to generate a large and varied set of samples to Self-Train the final model. Our whole proposal allows for achieving state-of-the-art performance (58.8 mIoU) in the GTA5->CS benchmark benchmark. Code is available at https://github.com/CVLAB-Unibo/d4-dbst.