 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
May 28, 2026Large Vision-Language Models (LVLMs) map visual inputs into dense token sequences, imposing a quadratic computational bottleneck for inference. Elastic visual-token compression addresses this by training a single model that can run at multiple visual-token budgets. However, existing approaches struggle under aggressive compression. Spatial-only compression, as in nested pooling, behaves as an imperfect low-pass filter and induces spectral aliasing that obscures fine-grained detail. Query-only compression, as in nested query resampling, replaces explicit grid-aligned tokens with non-local summaries and substantially degrades spatial grounding. To resolve this representational conflict, we introduce PARCEL (Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding), a visual tokenization architecture that dynamically partitions the labor of feature extraction. PARCEL establishes spatial pool tokens as low-frequency layout anchors and conditions elastic query tokens on these anchors through Pool-Conditioned Query Resampling. This encourages query tokens to focus on complementary visual features rather than redundant spatial mapping. Extensive evaluations across 27 benchmarks show that PARCEL improves the performance-efficiency Pareto frontier, consistently outperforming existing matryoshka baselines across visual-token budgets while preserving the "train once, deploy anywhere" paradigm.
FullFlow: Upgrading Text-to-Image Flow Matching Models for Bidirectional Vision--Language Generation
May 19, 2026Modern text-to-image diffusion models encode rich visual priors, but expose them only through one-way text-conditioned generation. Existing unified vision--language models derived from them recover bidirectional capability through large-scale joint pretraining or substantial retraining of the text pathway, discarding the strong image prior the text-to-image backbone already encodes. We introduce \emph{FullFlow}, a parameter-efficient recipe that upgrades a pretrained rectified-flow text-to-image model into a bidirectional vision--language generator by training only LoRA adapters and lightweight text heads. FullFlow keeps images in their native continuous flow and adds a discrete insertion process for text. Separate image and text timesteps turn inference into trajectory selection in a two-dimensional generative space, enabling text$\rightarrow$image, image$\rightarrow$text, joint sampling, and partial-text prediction with a single backbone. On Stable Diffusion 3 (SD3) under an identical trainable-parameter count and matched LoRA rank, FullFlow improves text$\rightarrow$image FID from $62.7$ to $31.6$ and image$\rightarrow$text CIDEr from $2.0$ to $99.4$ over a LoRA equivalent following the previous SOTA formulation (Dual Diffusion) at matched wall-clock training time, while reducing peak VRAM from ${\sim}84$\,GB to ${\sim}38$\,GB and raising throughput by ${\sim}8\times$ on two RTX A5000 GPUs in under 24 hours, training only ${\sim}5\%$ of the backbone parameters. The same recipe transfers to FLUX.1-dev and supports downstream VQA through partial-text generation. These results show that strong bidirectional vision--language capability can be unlocked from pretrained text-to-image flow models without full multimodal pretraining.
SSL-R1: Self-Supervised Visual Reinforcement Post-Training for Multimodal Large Language Models
Apr 22, 2026Reinforcement learning (RL) with verifiable rewards (RLVR) has demonstrated the great potential of enhancing the reasoning abilities in multimodal large language models (MLLMs). However, the reliance on language-centric priors and expensive manual annotations prevents MLLMs' intrinsic visual understanding and scalable reward designs. In this work, we introduce SSL-R1, a generic self-supervised RL framework that derives verifiable rewards directly from images. To this end, we revisit self-supervised learning (SSL) in visual domains and reformulate widely-used SSL tasks into a set of verifiable visual puzzles for RL post-training, requiring neither human nor external model supervision. Training MLLMs on these tasks substantially improves their performance on multimodal understanding and reasoning benchmarks, highlighting the potential of leveraging vision-centric self-supervised tasks for MLLM post-training. We think this work will provide useful experience in devising effective self-supervised verifiable rewards to enable RL at scale. Project page: https://github.com/Jiahao000/SSL-R1.
R-CoV: Region-Aware Chain-of-Verification for Alleviating Object Hallucinations in LVLMs
Apr 22, 2026Large vision-language models (LVLMs) have demonstrated impressive performance in various multimodal understanding and reasoning tasks. However, they still struggle with object hallucinations, i.e., the claim of nonexistent objects in the visual input. To address this challenge, we propose Region-aware Chain-of-Verification (R-CoV), a visual chain-of-verification method to alleviate object hallucinations in LVLMs in a post-hoc manner. Motivated by how humans comprehend intricate visual information -- often focusing on specific image regions or details within a given sample -- we elicit such region-level processing from LVLMs themselves and use it as a chaining cue to detect and alleviate their own object hallucinations. Specifically, our R-CoV consists of six steps: initial response generation, entity extraction, coordinate generation, region description, verification execution, and final response generation. As a simple yet effective method, R-CoV can be seamlessly integrated into various LVLMs in a training-free manner and without relying on external detection models. Extensive experiments on several widely used hallucination benchmarks across multiple LVLMs demonstrate that R-CoV can significantly alleviate object hallucinations in LVLMs. Project page: https://github.com/Jiahao000/R-CoV.
Shifting the Breaking Point of Flow Matching for Multi-Instance Editing
Feb 09, 2026Flow matching models have recently emerged as an efficient alternative to diffusion, especially for text-guided image generation and editing, offering faster inference through continuous-time dynamics. However, existing flow-based editors predominantly support global or single-instruction edits and struggle with multi-instance scenarios, where multiple parts of a reference input must be edited independently without semantic interference. We identify this limitation as a consequence of globally conditioned velocity fields and joint attention mechanisms, which entangle concurrent edits. To address this issue, we introduce Instance-Disentangled Attention, a mechanism that partitions joint attention operations, enforcing binding between instance-specific textual instructions and spatial regions during velocity field estimation. We evaluate our approach on both natural image editing and a newly introduced benchmark of text-dense infographics with region-level editing instructions. Experimental results demonstrate that our approach promotes edit disentanglement and locality while preserving global output coherence, enabling single-pass, instance-level editing.
RefAM: Attention Magnets for Zero-Shot Referral Segmentation
Sep 26, 2025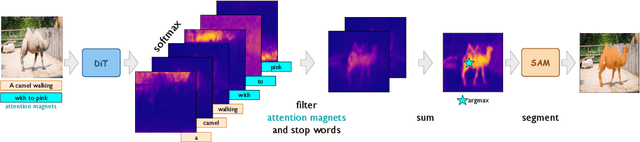
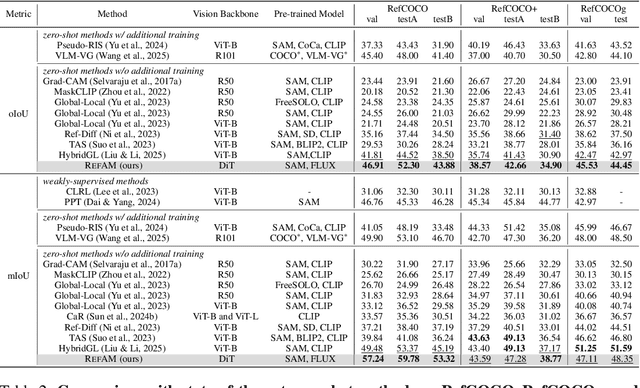

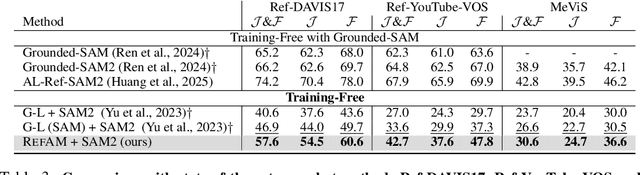
Most existing approaches to referring segmentation achieve strong performance only through fine-tuning or by composing multiple pre-trained models, often at the cost of additional training and architectural modifications. Meanwhile, large-scale generative diffusion models encode rich semantic information, making them attractive as general-purpose feature extractors. In this work, we introduce a new method that directly exploits features, attention scores, from diffusion transformers for downstream tasks, requiring neither architectural modifications nor additional training. To systematically evaluate these features, we extend benchmarks with vision-language grounding tasks spanning both images and videos. Our key insight is that stop words act as attention magnets: they accumulate surplus attention and can be filtered to reduce noise. Moreover, we identify global attention sinks (GAS) emerging in deeper layers and show that they can be safely suppressed or redirected onto auxiliary tokens, leading to sharper and more accurate grounding maps. We further propose an attention redistribution strategy, where appended stop words partition background activations into smaller clusters, yielding sharper and more localized heatmaps. Building on these findings, we develop RefAM, a simple training-free grounding framework that combines cross-attention maps, GAS handling, and redistribution. Across zero-shot referring image and video segmentation benchmarks, our approach consistently outperforms prior methods, establishing a new state of the art without fine-tuning or additional components.
Test-Time Visual In-Context Tuning
Mar 27, 2025



Visual in-context learning (VICL), as a new paradigm in computer vision, allows the model to rapidly adapt to various tasks with only a handful of prompts and examples. While effective, the existing VICL paradigm exhibits poor generalizability under distribution shifts. In this work, we propose test-time Visual In-Context Tuning (VICT), a method that can adapt VICL models on the fly with a single test sample. Specifically, we flip the role between the task prompts and the test sample and use a cycle consistency loss to reconstruct the original task prompt output. Our key insight is that a model should be aware of a new test distribution if it can successfully recover the original task prompts. Extensive experiments on six representative vision tasks ranging from high-level visual understanding to low-level image processing, with 15 common corruptions, demonstrate that our VICT can improve the generalizability of VICL to unseen new domains. In addition, we show the potential of applying VICT for unseen tasks at test time. Code: https://github.com/Jiahao000/VICT.
Omnia de EgoTempo: Benchmarking Temporal Understanding of Multi-Modal LLMs in Egocentric Videos
Mar 17, 2025

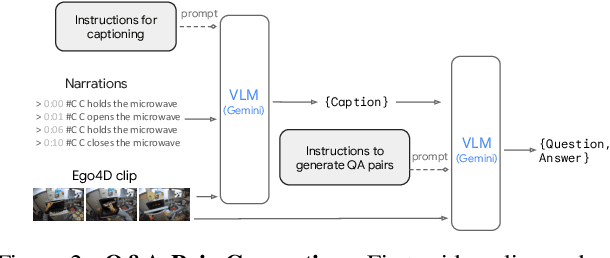
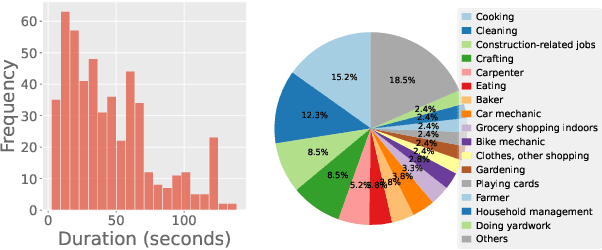
Understanding fine-grained temporal dynamics is crucial in egocentric videos, where continuous streams capture frequent, close-up interactions with objects. In this work, we bring to light that current egocentric video question-answering datasets often include questions that can be answered using only few frames or commonsense reasoning, without being necessarily grounded in the actual video. Our analysis shows that state-of-the-art Multi-Modal Large Language Models (MLLMs) on these benchmarks achieve remarkably high performance using just text or a single frame as input. To address these limitations, we introduce EgoTempo, a dataset specifically designed to evaluate temporal understanding in the egocentric domain. EgoTempo emphasizes tasks that require integrating information across the entire video, ensuring that models would need to rely on temporal patterns rather than static cues or pre-existing knowledge. Extensive experiments on EgoTempo show that current MLLMs still fall short in temporal reasoning on egocentric videos, and thus we hope EgoTempo will catalyze new research in the field and inspire models that better capture the complexity of temporal dynamics. Dataset and code are available at https://github.com/google-research-datasets/egotempo.git.
UIP2P: Unsupervised Instruction-based Image Editing via Cycle Edit Consistency
Dec 19, 2024



We propose an unsupervised model for instruction-based image editing that eliminates the need for ground-truth edited images during training. Existing supervised methods depend on datasets containing triplets of input image, edited image, and edit instruction. These are generated by either existing editing methods or human-annotations, which introduce biases and limit their generalization ability. Our method addresses these challenges by introducing a novel editing mechanism called Cycle Edit Consistency (CEC), which applies forward and backward edits in one training step and enforces consistency in image and attention spaces. This allows us to bypass the need for ground-truth edited images and unlock training for the first time on datasets comprising either real image-caption pairs or image-caption-edit triplets. We empirically show that our unsupervised technique performs better across a broader range of edits with high fidelity and precision. By eliminating the need for pre-existing datasets of triplets, reducing biases associated with supervised methods, and proposing CEC, our work represents a significant advancement in unblocking scaling of instruction-based image editing.
Active Data Curation Effectively Distills Large-Scale Multimodal Models
Nov 27, 2024Knowledge distillation (KD) is the de facto standard for compressing large-scale models into smaller ones. Prior works have explored ever more complex KD strategies involving different objective functions, teacher-ensembles, and weight inheritance. In this work we explore an alternative, yet simple approach -- active data curation as effective distillation for contrastive multimodal pretraining. Our simple online batch selection method, ACID, outperforms strong KD baselines across various model-, data- and compute-configurations. Further, we find such an active data curation strategy to in fact be complementary to standard KD, and can be effectively combined to train highly performant inference-efficient models. Our simple and scalable pretraining framework, ACED, achieves state-of-the-art results across 27 zero-shot classification and retrieval tasks with upto 11% less inference FLOPs. We further demonstrate that our ACED models yield strong vision-encoders for training generative multimodal models in the LiT-Decoder setting, outperforming larger vision encoders for image-captioning and visual question-answering tasks.