 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInseRF: Text-Driven Generative Object Insertion in Neural 3D Scenes
Jan 10, 2024We introduce InseRF, a novel method for generative object insertion in the NeRF reconstructions of 3D scenes. Based on a user-provided textual description and a 2D bounding box in a reference viewpoint, InseRF generates new objects in 3D scenes. Recently, methods for 3D scene editing have been profoundly transformed, owing to the use of strong priors of text-to-image diffusion models in 3D generative modeling. Existing methods are mostly effective in editing 3D scenes via style and appearance changes or removing existing objects. Generating new objects, however, remains a challenge for such methods, which we address in this study. Specifically, we propose grounding the 3D object insertion to a 2D object insertion in a reference view of the scene. The 2D edit is then lifted to 3D using a single-view object reconstruction method. The reconstructed object is then inserted into the scene, guided by the priors of monocular depth estimation methods. We evaluate our method on various 3D scenes and provide an in-depth analysis of the proposed components. Our experiments with generative insertion of objects in several 3D scenes indicate the effectiveness of our method compared to the existing methods. InseRF is capable of controllable and 3D-consistent object insertion without requiring explicit 3D information as input. Please visit our project page at https://mohamad-shahbazi.github.io/inserf.
NeRF-GAN Distillation for Efficient 3D-Aware Generation with Convolutions
Mar 22, 2023Pose-conditioned convolutional generative models struggle with high-quality 3D-consistent image generation from single-view datasets, due to their lack of sufficient 3D priors. Recently, the integration of Neural Radiance Fields (NeRFs) and generative models, such as Generative Adversarial Networks (GANs), has transformed 3D-aware generation from single-view images. NeRF-GANs exploit the strong inductive bias of 3D neural representations and volumetric rendering at the cost of higher computational complexity. This study aims at revisiting pose-conditioned 2D GANs for efficient 3D-aware generation at inference time by distilling 3D knowledge from pretrained NeRF-GANS. We propose a simple and effective method, based on re-using the well-disentangled latent space of a pre-trained NeRF-GAN in a pose-conditioned convolutional network to directly generate 3D-consistent images corresponding to the underlying 3D representations. Experiments on several datasets demonstrate that the proposed method obtains results comparable with volumetric rendering in terms of quality and 3D consistency while benefiting from the superior computational advantage of convolutional networks. The code will be available at: https://github.com/mshahbazi72/NeRF-GAN-Distillation
Editing in Style: Uncovering the Local Semantics of GANs
May 21, 2020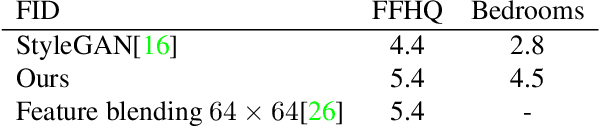



While the quality of GAN image synthesis has improved tremendously in recent years, our ability to control and condition the output is still limited. Focusing on StyleGAN, we introduce a simple and effective method for making local, semantically-aware edits to a target output image. This is accomplished by borrowing elements from a source image, also a GAN output, via a novel manipulation of style vectors. Our method requires neither supervision from an external model, nor involves complex spatial morphing operations. Instead, it relies on the emergent disentanglement of semantic objects that is learned by StyleGAN during its training. Semantic editing is demonstrated on GANs producing human faces, indoor scenes, cats, and cars. We measure the locality and photorealism of the edits produced by our method, and find that it accomplishes both.
Detecting Memorization in ReLU Networks
Oct 08, 2018



We propose a new notion of `non-linearity' of a network layer with respect to an input batch that is based on its proximity to a linear system, which is reflected in the non-negative rank of the activation matrix. We measure this non-linearity by applying non-negative factorization to the activation matrix. Considering batches of similar samples, we find that high non-linearity in deep layers is indicative of memorization. Furthermore, by applying our approach layer-by-layer, we find that the mechanism for memorization consists of distinct phases. We perform experiments on fully-connected and convolutional neural networks trained on several image and audio datasets. Our results demonstrate that as an indicator for memorization, our technique can be used to perform early stopping.
Deep Feature Factorization For Concept Discovery
Oct 08, 2018
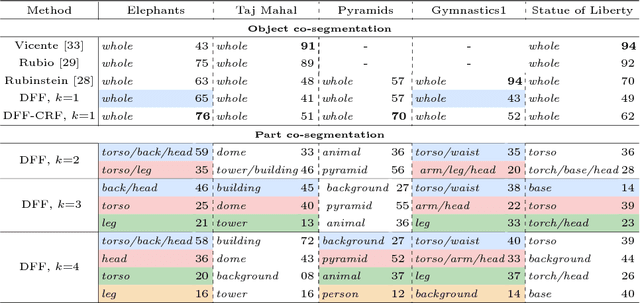
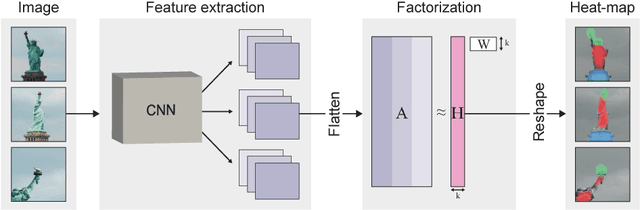
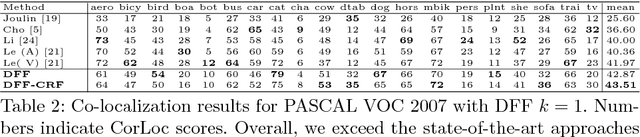
We propose Deep Feature Factorization (DFF), a method capable of localizing similar semantic concepts within an image or a set of images. We use DFF to gain insight into a deep convolutional neural network's learned features, where we detect hierarchical cluster structures in feature space. This is visualized as heat maps, which highlight semantically matching regions across a set of images, revealing what the network `perceives' as similar. DFF can also be used to perform co-segmentation and co-localization, and we report state-of-the-art results on these tasks.