 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks for Face Images Against Fine-Tuned Latent Diffusion Models
Feb 17, 2025The rise of generative image models leads to privacy concerns when it comes to the huge datasets used to train such models. This paper investigates the possibility of inferring if a set of face images was used for fine-tuning a Latent Diffusion Model (LDM). A Membership Inference Attack (MIA) method is presented for this task. Using generated auxiliary data for the training of the attack model leads to significantly better performance, and so does the use of watermarks. The guidance scale used for inference was found to have a significant influence. If a LDM is fine-tuned for long enough, the text prompt used for inference has no significant influence. The proposed MIA is found to be viable in a realistic black-box setup against LDMs fine-tuned on face-images.
* In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages 439-446
MozzaVID: Mozzarella Volumetric Image Dataset
Dec 06, 2024Influenced by the complexity of volumetric imaging, there is a shortage of established datasets useful for benchmarking volumetric deep-learning models. As a consequence, new and existing models are not easily comparable, limiting the development of architectures optimized specifically for volumetric data. To counteract this trend, we introduce MozzaVID - a large, clean, and versatile volumetric classification dataset. Our dataset contains X-ray computed tomography (CT) images of mozzarella microstructure and enables the classification of 25 cheese types and 149 cheese samples. We provide data in three different resolutions, resulting in three dataset instances containing from 591 to 37,824 images. While being general-purpose, the dataset also facilitates investigating mozzarella structure properties. The structure of food directly affects its functional properties and thus its consumption experience. Understanding food structure helps tune the production and mimicking it enables sustainable alternatives to animal-derived food products. The complex and disordered nature of food structures brings a unique challenge, where a choice of appropriate imaging method, scale, and sample size is not trivial. With this dataset we aim to address these complexities, contributing to more robust structural analysis models. The dataset can be downloaded from: https://archive.compute.dtu.dk/files/public/projects/MozzaVID/.
StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models
Mar 08, 2024The demand for stereo images increases as manufacturers launch more XR devices. To meet this demand, we introduce StereoDiffusion, a method that, unlike traditional inpainting pipelines, is trainning free, remarkably straightforward to use, and it seamlessly integrates into the original Stable Diffusion model. Our method modifies the latent variable to provide an end-to-end, lightweight capability for fast generation of stereo image pairs, without the need for fine-tuning model weights or any post-processing of images. Using the original input to generate a left image and estimate a disparity map for it, we generate the latent vector for the right image through Stereo Pixel Shift operations, complemented by Symmetric Pixel Shift Masking Denoise and Self-Attention Layers Modification methods to align the right-side image with the left-side image. Moreover, our proposed method maintains a high standard of image quality throughout the stereo generation process, achieving state-of-the-art scores in various quantitative evaluations.
Detecting Memorization in ReLU Networks
Oct 08, 2018



We propose a new notion of `non-linearity' of a network layer with respect to an input batch that is based on its proximity to a linear system, which is reflected in the non-negative rank of the activation matrix. We measure this non-linearity by applying non-negative factorization to the activation matrix. Considering batches of similar samples, we find that high non-linearity in deep layers is indicative of memorization. Furthermore, by applying our approach layer-by-layer, we find that the mechanism for memorization consists of distinct phases. We perform experiments on fully-connected and convolutional neural networks trained on several image and audio datasets. Our results demonstrate that as an indicator for memorization, our technique can be used to perform early stopping.
FaceShop: Deep Sketch-based Face Image Editing
Jun 07, 2018
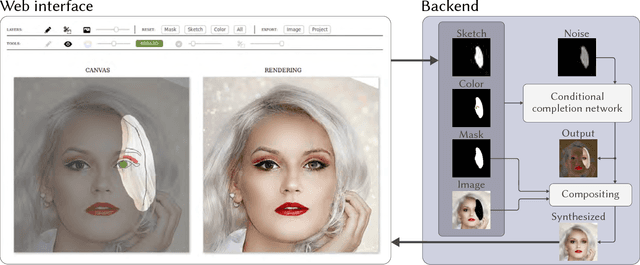
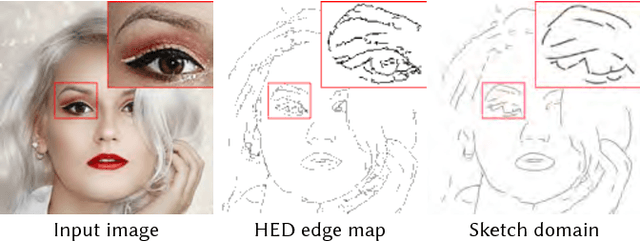

We present a novel system for sketch-based face image editing, enabling users to edit images intuitively by sketching a few strokes on a region of interest. Our interface features tools to express a desired image manipulation by providing both geometry and color constraints as user-drawn strokes. As an alternative to the direct user input, our proposed system naturally supports a copy-paste mode, which allows users to edit a given image region by using parts of another exemplar image without the need of hand-drawn sketching at all. The proposed interface runs in real-time and facilitates an interactive and iterative workflow to quickly express the intended edits. Our system is based on a novel sketch domain and a convolutional neural network trained end-to-end to automatically learn to render image regions corresponding to the input strokes. To achieve high quality and semantically consistent results we train our neural network on two simultaneous tasks, namely image completion and image translation. To the best of our knowledge, we are the first to combine these two tasks in a unified framework for interactive image editing. Our results show that the proposed sketch domain, network architecture, and training procedure generalize well to real user input and enable high quality synthesis results without additional post-processing.
Deep Mean-Shift Priors for Image Restoration
Oct 04, 2017

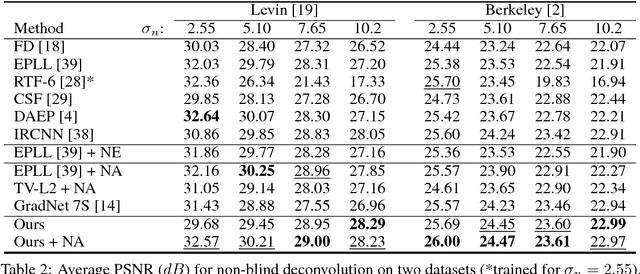

In this paper we introduce a natural image prior that directly represents a Gaussian-smoothed version of the natural image distribution. We include our prior in a formulation of image restoration as a Bayes estimator that also allows us to solve noise-blind image restoration problems. We show that the gradient of our prior corresponds to the mean-shift vector on the natural image distribution. In addition, we learn the mean-shift vector field using denoising autoencoders, and use it in a gradient descent approach to perform Bayes risk minimization. We demonstrate competitive results for noise-blind deblurring, super-resolution, and demosaicing.
Image Restoration using Autoencoding Priors
Mar 29, 2017
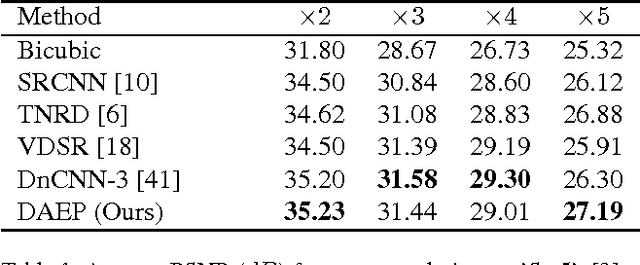

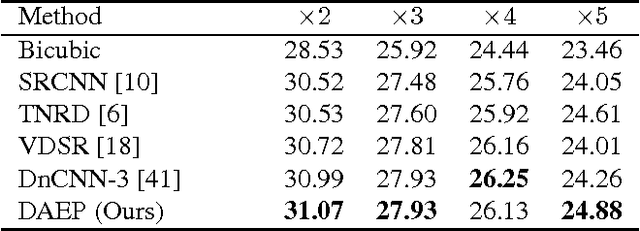
We propose to leverage denoising autoencoder networks as priors to address image restoration problems. We build on the key observation that the output of an optimal denoising autoencoder is a local mean of the true data density, and the autoencoder error (the difference between the output and input of the trained autoencoder) is a mean shift vector. We use the magnitude of this mean shift vector, that is, the distance to the local mean, as the negative log likelihood of our natural image prior. For image restoration, we maximize the likelihood using gradient descent by backpropagating the autoencoder error. A key advantage of our approach is that we do not need to train separate networks for different image restoration tasks, such as non-blind deconvolution with different kernels, or super-resolution at different magnification factors. We demonstrate state of the art results for non-blind deconvolution and super-resolution using the same autoencoding prior.