 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoDaSuRe: A Large-Scale Dataset Revealing Domain Shift in Volumetric Super-Resolution
Mar 24, 2026Recent advances in volumetric super-resolution (SR) have demonstrated strong performance in medical and scientific imaging, with transformer- and CNN-based approaches achieving impressive results even at extreme scaling factors. In this work, we show that much of this performance stems from training on downsampled data rather than real low-resolution scans. This reliance on downsampling is partly driven by the scarcity of paired high- and low-resolution 3D datasets. To address this, we introduce VoDaSuRe, a large-scale volumetric dataset containing paired high- and low-resolution scans. When training models on VoDaSuRe, we reveal a significant discrepancy: SR models trained on downsampled data produce substantially sharper predictions than those trained on real low-resolution scans, which smooth fine structures. Conversely, applying models trained on downsampled data to real scans preserves more structure but is inaccurate. Our findings suggest that current SR methods are overstated - when applied to real data, they do not recover structures lost in low-resolution scans and instead predict a smoothed average. We argue that progress in deep learning-based volumetric SR requires datasets with paired real scans of high complexity, such as VoDaSuRe. Our dataset and code are publicly available through: https://augusthoeg.github.io/VoDaSuRe/
Rethinking Uncertainty Quantification and Entanglement in Image Segmentation
Mar 19, 2026Uncertainty quantification (UQ) is crucial in safety-critical applications such as medical image segmentation. Total uncertainty is typically decomposed into data-related aleatoric uncertainty (AU) and model-related epistemic uncertainty (EU). Many methods exist for modeling AU (such as Probabilistic UNet, Diffusion) and EU (such as ensembles, MC Dropout), but it is unclear how they interact when combined. Additionally, recent work has revealed substantial entanglement between AU and EU, undermining the interpretability and practical usefulness of the decomposition. We present a comprehensive empirical study covering a broad range of AU-EU model combinations, propose a metric to quantify uncertainty entanglement, and evaluate both across downstream UQ tasks. For out-of-distribution detection, ensembles exhibit consistently lower entanglement and superior performance. For ambiguity modeling and calibration the best models are dataset-dependent, with softmax/SSN-based methods performing well and Probabilistic UNets being less entangled. A softmax ensemble fares remarkably well on all tasks. Finally, we analyze potential sources of uncertainty entanglement and outline directions for mitigating this effect.
Towards High-Quality Image Segmentation: Improving Topology Accuracy by Penalizing Neighbor Pixels
Mar 19, 2026Standard deep learning models for image segmentation cannot guarantee topology accuracy, failing to preserve the correct number of connected components or structures. This, in turn, affects the quality of the segmentations and compromises the reliability of the subsequent quantification analyses. Previous works have proposed to enhance topology accuracy with specialized frameworks, architectures, and loss functions. However, these methods are often cumbersome to integrate into existing training pipelines, they are computationally very expensive, or they are restricted to structures with tubular morphology. We present SCNP, an efficient method that improves topology accuracy by penalizing the logits with their poorest-classified neighbor, forcing the model to improve the prediction at the pixels' neighbors before allowing it to improve the pixels themselves. We show the effectiveness of SCNP across 13 datasets, covering different structure morphologies and image modalities, and integrate it into three frameworks for semantic and instance segmentation. Additionally, we show that SCNP can be integrated into several loss functions, making them improve topology accuracy. Our code can be found at https://jmlipman.github.io/SCNP-SameClassNeighborPenalization.
Towards Agnostic and Holistic Universal Image Segmentation with Bit Diffusion
Jan 06, 2026This paper introduces a diffusion-based framework for universal image segmentation, making agnostic segmentation possible without depending on mask-based frameworks and instead predicting the full segmentation in a holistic manner. We present several key adaptations to diffusion models, which are important in this discrete setting. Notably, we show that a location-aware palette with our 2D gray code ordering improves performance. Adding a final tanh activation function is crucial for discrete data. On optimizing diffusion parameters, the sigmoid loss weighting consistently outperforms alternatives, regardless of the prediction type used, and we settle on x-prediction. While our current model does not yet surpass leading mask-based architectures, it narrows the performance gap and introduces unique capabilities, such as principled ambiguity modeling, that these models lack. All models were trained from scratch, and we believe that combining our proposed improvements with large-scale pretraining or promptable conditioning could lead to competitive models.
Fast Sphericity and Roundness approximation in 2D and 3D using Local Thickness
Apr 08, 2025Sphericity and roundness are fundamental measures used for assessing object uniformity in 2D and 3D images. However, using their strict definition makes computation costly. As both 2D and 3D microscopy imaging datasets grow larger, there is an increased demand for efficient algorithms that can quantify multiple objects in large volumes. We propose a novel approach for extracting sphericity and roundness based on the output of a local thickness algorithm. For sphericity, we simplify the surface area computation by modeling objects as spheroids/ellipses of varying lengths and widths of mean local thickness. For roundness, we avoid a complex corner curvature determination process by approximating it with local thickness values on the contour/surface of the object. The resulting methods provide an accurate representation of the exact measures while being significantly faster than their existing implementations.
Diffusion Based Ambiguous Image Segmentation
Apr 08, 2025Medical image segmentation often involves inherent uncertainty due to variations in expert annotations. Capturing this uncertainty is an important goal and previous works have used various generative image models for the purpose of representing the full distribution of plausible expert ground truths. In this work, we explore the design space of diffusion models for generative segmentation, investigating the impact of noise schedules, prediction types, and loss weightings. Notably, we find that making the noise schedule harder with input scaling significantly improves performance. We conclude that x- and v-prediction outperform epsilon-prediction, likely because the diffusion process is in the discrete segmentation domain. Many loss weightings achieve similar performance as long as they give enough weight to the end of the diffusion process. We base our experiments on the LIDC-IDRI lung lesion dataset and obtain state-of-the-art (SOTA) performance. Additionally, we introduce a randomly cropped variant of the LIDC-IDRI dataset that is better suited for uncertainty in image segmentation. Our model also achieves SOTA in this harder setting.
Disconnect to Connect: A Data Augmentation Method for Improving Topology Accuracy in Image Segmentation
Mar 07, 2025



Accurate segmentation of thin, tubular structures (e.g., blood vessels) is challenging for deep neural networks. These networks classify individual pixels, and even minor misclassifications can break the thin connections within these structures. Existing methods for improving topology accuracy, such as topology loss functions, rely on very precise, topologically-accurate training labels, which are difficult to obtain. This is because annotating images, especially 3D images, is extremely laborious and time-consuming. Low image resolution and contrast further complicates the annotation by causing tubular structures to appear disconnected. We present CoLeTra, a data augmentation strategy that integrates to the models the prior knowledge that structures that appear broken are actually connected. This is achieved by creating images with the appearance of disconnected structures while maintaining the original labels. Our extensive experiments, involving different architectures, loss functions, and datasets, demonstrate that CoLeTra leads to segmentations topologically more accurate while often improving the Dice coefficient and Hausdorff distance. CoLeTra's hyper-parameters are intuitive to tune, and our sensitivity analysis shows that CoLeTra is robust to changes in these hyper-parameters. We also release a dataset specifically suited for image segmentation methods with a focus on topology accuracy. CoLetra's code can be found at https://github.com/jmlipman/CoLeTra.
TopoMortar: A dataset to evaluate image segmentation methods focused on topology accuracy
Mar 05, 2025
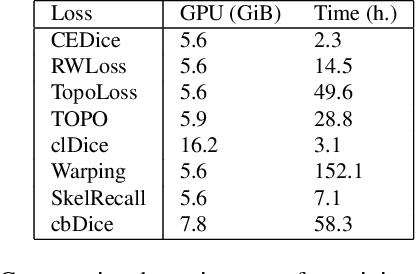
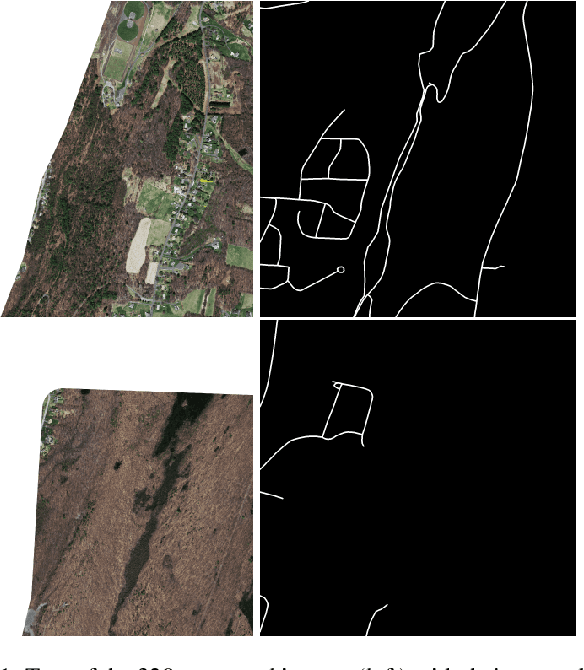
We present TopoMortar, a brick wall dataset that is the first dataset specifically designed to evaluate topology-focused image segmentation methods, such as topology loss functions. TopoMortar enables to investigate in two ways whether methods incorporate prior topological knowledge. First, by eliminating challenges seen in real-world data, such as small training set, noisy labels, and out-of-distribution test-set images, that, as we show, impact the effectiveness of topology losses. Second, by allowing to assess in the same dataset topology accuracy across dataset challenges, isolating dataset-related effects from the effect of incorporating prior topological knowledge. In these two experiments, it is deliberately difficult to improve topology accuracy without actually using topology information, thus, permitting to attribute an improvement in topology accuracy to the incorporation of prior topological knowledge. To this end, TopoMortar includes three types of labels (accurate, noisy, pseudo-labels), two fixed training sets (large and small), and in-distribution and out-of-distribution test-set images. We compared eight loss functions on TopoMortar, and we found that clDice achieved the most topologically accurate segmentations, Skeleton Recall loss performed best particularly with noisy labels, and the relative advantageousness of the other loss functions depended on the experimental setting. Additionally, we show that simple methods, such as data augmentation and self-distillation, can elevate Cross entropy Dice loss to surpass most topology loss functions, and that those simple methods can enhance topology loss functions as well. clDice and Skeleton Recall loss, both skeletonization-based loss functions, were also the fastest to train, making this type of loss function a promising research direction. TopoMortar and our code can be found at https://github.com/jmlipman/TopoMortar
A General Purpose Spectral Foundational Model for Both Proximal and Remote Sensing Spectral Imaging
Mar 03, 2025



Spectral imaging data acquired via multispectral and hyperspectral cameras can have hundreds of channels, where each channel records the reflectance at a specific wavelength and bandwidth. Time and resource constraints limit our ability to collect large spectral datasets, making it difficult to build and train predictive models from scratch. In the RGB domain, we can often alleviate some of the limitations of smaller datasets by using pretrained foundational models as a starting point. However, most existing foundation models are pretrained on large datasets of 3-channel RGB images, severely limiting their effectiveness when used with spectral imaging data. The few spectral foundation models that do exist usually have one of two limitations: (1) they are built and trained only on remote sensing data limiting their application in proximal spectral imaging, (2) they utilize the more widely available multispectral imaging datasets with less than 15 channels restricting their use with hundred-channel hyperspectral images. To alleviate these issues, we propose a large-scale foundational model and dataset built upon the masked autoencoder architecture that takes advantage of spectral channel encoding, spatial-spectral masking and ImageNet pretraining for an adaptable and robust model for downstream spectral imaging tasks.
MozzaVID: Mozzarella Volumetric Image Dataset
Dec 06, 2024Influenced by the complexity of volumetric imaging, there is a shortage of established datasets useful for benchmarking volumetric deep-learning models. As a consequence, new and existing models are not easily comparable, limiting the development of architectures optimized specifically for volumetric data. To counteract this trend, we introduce MozzaVID - a large, clean, and versatile volumetric classification dataset. Our dataset contains X-ray computed tomography (CT) images of mozzarella microstructure and enables the classification of 25 cheese types and 149 cheese samples. We provide data in three different resolutions, resulting in three dataset instances containing from 591 to 37,824 images. While being general-purpose, the dataset also facilitates investigating mozzarella structure properties. The structure of food directly affects its functional properties and thus its consumption experience. Understanding food structure helps tune the production and mimicking it enables sustainable alternatives to animal-derived food products. The complex and disordered nature of food structures brings a unique challenge, where a choice of appropriate imaging method, scale, and sample size is not trivial. With this dataset we aim to address these complexities, contributing to more robust structural analysis models. The dataset can be downloaded from: https://archive.compute.dtu.dk/files/public/projects/MozzaVID/.