 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Compact Graph Cuts for the Boykov-Kolmogorov Algorithm
May 13, 2026Computing a minimum $s$-$t$ cut in a graph is a solution to a wide range of computer vision problems, and is often done using the Boykov-Kolmogorov (BK) algorithm. In this paper, we revisit the BK algorithm from both a theoretical and practical point of view. We improve the analysis of the time complexity of the BK algorithm to $O(mn|C|)$ and propose a new algorithm, the fast and compact BK (fcBK) algorithm, with a time complexity of $O(m|C|)$, where $m$, $n$, and $|C|$ are the number of edges, number of vertices, and the capacity of the cut, respectively. We additionally propose a compact graph representation that allows our implementation to find a minimum $s$-$t$ cut in a graph with upwards of $10^9$ vertices and $10^{10}$ edges on a machine with 128 GB of memory. We find our implementation of the BK algorithm to be the fastest available implementation of the BK algorithm when evaluating on a comprehensive set of benchmark datasets, highlighting the importance of memory-efficient implementations. We make our implementations publicly available for further research and implementation development within minimum $s$-$t$ cut algorithms.
FaCT-GS: Fast and Scalable CT Reconstruction with Gaussian Splatting
Apr 02, 2026Gaussian Splatting (GS) has emerged as a dominating technique for image rendering and has quickly been adapted for the X-ray Computed Tomography (CT) reconstruction task. However, despite being on par or better than many of its predecessors, the benefits of GS are typically not substantial enough to motivate a transition from well-established reconstruction algorithms. This paper addresses the most significant remaining limitations of the GS-based approach by introducing FaCT-GS, a framework for fast and flexible CT reconstruction. Enabled by an in-depth optimization of the voxelization and rasterization pipelines, our new method is significantly faster than its predecessors and scales well with projection and output volume size. Furthermore, the improved voxelization enables rapid fitting of Gaussians to pre-existing volumes, which can serve as a prior for warm-starting the reconstruction, or simply as an alternative, compressed representation. FaCT-GS is over 4X faster than the State of the Art GS CT reconstruction on standard 512x512 projections, and over 13X faster on 2k projections. Implementation available at: https://github.com/PaPieta/fact-gs.
VoDaSuRe: A Large-Scale Dataset Revealing Domain Shift in Volumetric Super-Resolution
Mar 24, 2026Recent advances in volumetric super-resolution (SR) have demonstrated strong performance in medical and scientific imaging, with transformer- and CNN-based approaches achieving impressive results even at extreme scaling factors. In this work, we show that much of this performance stems from training on downsampled data rather than real low-resolution scans. This reliance on downsampling is partly driven by the scarcity of paired high- and low-resolution 3D datasets. To address this, we introduce VoDaSuRe, a large-scale volumetric dataset containing paired high- and low-resolution scans. When training models on VoDaSuRe, we reveal a significant discrepancy: SR models trained on downsampled data produce substantially sharper predictions than those trained on real low-resolution scans, which smooth fine structures. Conversely, applying models trained on downsampled data to real scans preserves more structure but is inaccurate. Our findings suggest that current SR methods are overstated - when applied to real data, they do not recover structures lost in low-resolution scans and instead predict a smoothed average. We argue that progress in deep learning-based volumetric SR requires datasets with paired real scans of high complexity, such as VoDaSuRe. Our dataset and code are publicly available through: https://augusthoeg.github.io/VoDaSuRe/
Rethinking Uncertainty Quantification and Entanglement in Image Segmentation
Mar 19, 2026Uncertainty quantification (UQ) is crucial in safety-critical applications such as medical image segmentation. Total uncertainty is typically decomposed into data-related aleatoric uncertainty (AU) and model-related epistemic uncertainty (EU). Many methods exist for modeling AU (such as Probabilistic UNet, Diffusion) and EU (such as ensembles, MC Dropout), but it is unclear how they interact when combined. Additionally, recent work has revealed substantial entanglement between AU and EU, undermining the interpretability and practical usefulness of the decomposition. We present a comprehensive empirical study covering a broad range of AU-EU model combinations, propose a metric to quantify uncertainty entanglement, and evaluate both across downstream UQ tasks. For out-of-distribution detection, ensembles exhibit consistently lower entanglement and superior performance. For ambiguity modeling and calibration the best models are dataset-dependent, with softmax/SSN-based methods performing well and Probabilistic UNets being less entangled. A softmax ensemble fares remarkably well on all tasks. Finally, we analyze potential sources of uncertainty entanglement and outline directions for mitigating this effect.
Towards Agnostic and Holistic Universal Image Segmentation with Bit Diffusion
Jan 06, 2026This paper introduces a diffusion-based framework for universal image segmentation, making agnostic segmentation possible without depending on mask-based frameworks and instead predicting the full segmentation in a holistic manner. We present several key adaptations to diffusion models, which are important in this discrete setting. Notably, we show that a location-aware palette with our 2D gray code ordering improves performance. Adding a final tanh activation function is crucial for discrete data. On optimizing diffusion parameters, the sigmoid loss weighting consistently outperforms alternatives, regardless of the prediction type used, and we settle on x-prediction. While our current model does not yet surpass leading mask-based architectures, it narrows the performance gap and introduces unique capabilities, such as principled ambiguity modeling, that these models lack. All models were trained from scratch, and we believe that combining our proposed improvements with large-scale pretraining or promptable conditioning could lead to competitive models.
Diffusion Based Ambiguous Image Segmentation
Apr 08, 2025Medical image segmentation often involves inherent uncertainty due to variations in expert annotations. Capturing this uncertainty is an important goal and previous works have used various generative image models for the purpose of representing the full distribution of plausible expert ground truths. In this work, we explore the design space of diffusion models for generative segmentation, investigating the impact of noise schedules, prediction types, and loss weightings. Notably, we find that making the noise schedule harder with input scaling significantly improves performance. We conclude that x- and v-prediction outperform epsilon-prediction, likely because the diffusion process is in the discrete segmentation domain. Many loss weightings achieve similar performance as long as they give enough weight to the end of the diffusion process. We base our experiments on the LIDC-IDRI lung lesion dataset and obtain state-of-the-art (SOTA) performance. Additionally, we introduce a randomly cropped variant of the LIDC-IDRI dataset that is better suited for uncertainty in image segmentation. Our model also achieves SOTA in this harder setting.
MTVNet: Mapping using Transformers for Volumes -- Network for Super-Resolution with Long-Range Interactions
Dec 09, 2024Until now, it has been difficult for volumetric super-resolution to utilize the recent advances in transformer-based models seen in 2D super-resolution. The memory required for self-attention in 3D volumes limits the receptive field. Therefore, long-range interactions are not used in 3D to the extent done in 2D and the strength of transformers is not realized. We propose a multi-scale transformer-based model based on hierarchical attention blocks combined with carrier tokens at multiple scales to overcome this. Here information from larger regions at coarse resolution is sequentially carried on to finer-resolution regions to predict the super-resolved image. Using transformer layers at each resolution, our coarse-to-fine modeling limits the number of tokens at each scale and enables attention over larger regions than what has previously been possible. We experimentally compare our method, MTVNet, against state-of-the-art volumetric super-resolution models on five 3D datasets demonstrating the advantage of an increased receptive field. This advantage is especially pronounced for images that are larger than what is seen in popularly used 3D datasets. Our code is available at https://github.com/AugustHoeg/MTVNet
Mapping using Transformers for Volumes -- Network for Super-Resolution with Long-Range Interactions
Dec 04, 2024Until now, it has been difficult for volumetric super-resolution to utilize the recent advances in transformer-based models seen in 2D super-resolution. The memory required for self-attention in 3D volumes limits the receptive field. Therefore, long-range interactions are not used in 3D to the extent done in 2D and the strength of transformers is not realized. We propose a multi-scale transformer-based model based on hierarchical attention blocks combined with carrier tokens at multiple scales to overcome this. Here information from larger regions at coarse resolution is sequentially carried on to finer-resolution regions to predict the super-resolved image. Using transformer layers at each resolution, our coarse-to-fine modeling limits the number of tokens at each scale and enables attention over larger regions than what has previously been possible. We experimentally compare our method, MTVNet, against state-of-the-art volumetric super-resolution models on five 3D datasets demonstrating the advantage of an increased receptive field. This advantage is especially pronounced for images that are larger than what is seen in popularly used 3D datasets. Our code is available at https://github.com/AugustHoeg/MTVNet
BugNIST -- A New Large Scale Volumetric 3D Image Dataset for Classification and Detection
Apr 04, 2023Progress in 3D volumetric image analysis research is limited by the lack of datasets and most advances in analysis methods for volumetric images are based on medical data. However, medical data do not necessarily resemble the characteristics of other volumetric images such as micro-CT. To promote research in 3D volumetric image analysis beyond medical data, we have created the BugNIST dataset and made it freely available. BugNIST is an extensive dataset of micro-CT scans of 12 types of bugs, such as insects and larvae. BugNIST contains 9437 volumes where 9087 are of individual bugs and 350 are mixtures of bugs and other material. The goal of BugNIST is to benchmark classification and detection methods, and we have designed the detection challenge such that detection models are trained on scans of individual bugs and tested on bug mixtures. Models capable of solving this task will be independent of the context, i.e., the surrounding material. This is a great advantage if the context is unknown or changing, as is often the case in micro-CT. Our initial baseline analysis shows that current state-of-the-art deep learning methods classify individual bugs very well, but has great difficulty with the detection challenge. Hereby, BugNIST enables research in image analysis areas that until now have missed relevant data - both classification, detection, and hopefully more.
Content-based Propagation of User Markings for Interactive Segmentation of Patterned Images
Sep 06, 2018

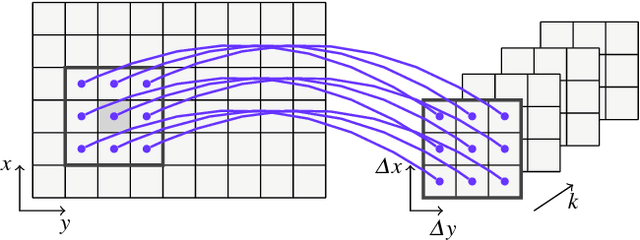
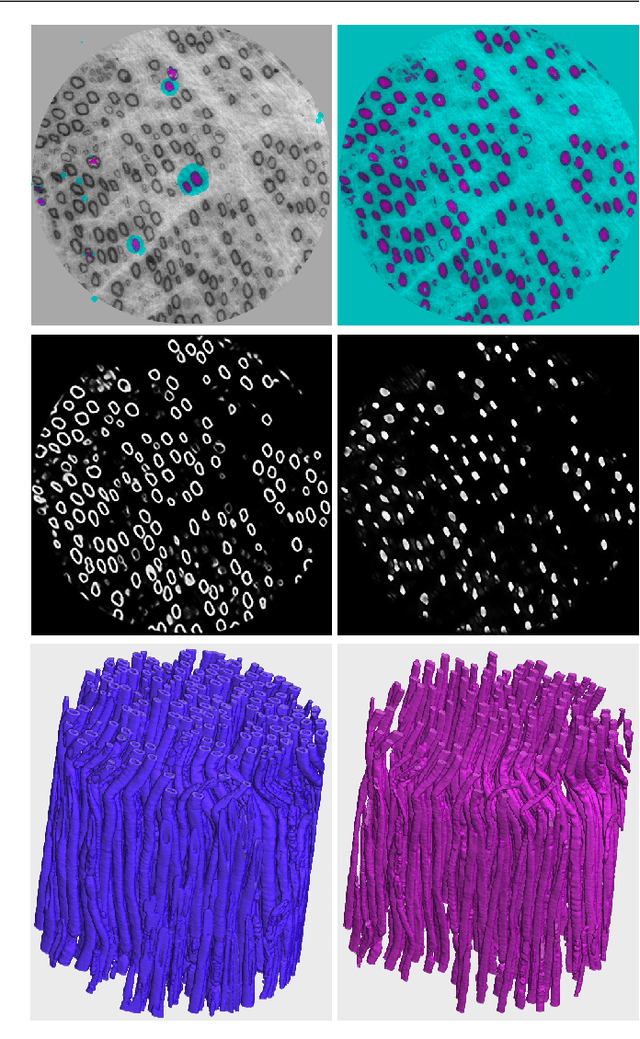
Efficient and easy segmentation of images and volumes is of great practical importance. Segmentation problems which motivate our approach originate from imaging commonly used in materials science and medicine. We formulate image segmentation as a probabilistic pixel classification problem, and we apply segmentation as a step towards characterising image content. Our method allows the user to define structures of interest by interactively marking a subset of pixels. Thanks to the real-time feedback, the user can place new markings strategically, depending on the current outcome. The final pixel classification may be obtained from a very modest user input. An important ingredient of our method is a graph that encodes image content. This graph is built in an unsupervised manner during initialisation, and is based on clustering of image features. Since we combine a limited amount of user-labelled data with the clustering information obtained from the unlabelled parts of the image, our method fits in the general framework of semi-supervised learning. We demonstrate how this can be a very efficient approach to segmentation through pixel classification.