 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTVNet: Mapping using Transformers for Volumes -- Network for Super-Resolution with Long-Range Interactions
Dec 09, 2024Until now, it has been difficult for volumetric super-resolution to utilize the recent advances in transformer-based models seen in 2D super-resolution. The memory required for self-attention in 3D volumes limits the receptive field. Therefore, long-range interactions are not used in 3D to the extent done in 2D and the strength of transformers is not realized. We propose a multi-scale transformer-based model based on hierarchical attention blocks combined with carrier tokens at multiple scales to overcome this. Here information from larger regions at coarse resolution is sequentially carried on to finer-resolution regions to predict the super-resolved image. Using transformer layers at each resolution, our coarse-to-fine modeling limits the number of tokens at each scale and enables attention over larger regions than what has previously been possible. We experimentally compare our method, MTVNet, against state-of-the-art volumetric super-resolution models on five 3D datasets demonstrating the advantage of an increased receptive field. This advantage is especially pronounced for images that are larger than what is seen in popularly used 3D datasets. Our code is available at https://github.com/AugustHoeg/MTVNet
Mapping using Transformers for Volumes -- Network for Super-Resolution with Long-Range Interactions
Dec 04, 2024Until now, it has been difficult for volumetric super-resolution to utilize the recent advances in transformer-based models seen in 2D super-resolution. The memory required for self-attention in 3D volumes limits the receptive field. Therefore, long-range interactions are not used in 3D to the extent done in 2D and the strength of transformers is not realized. We propose a multi-scale transformer-based model based on hierarchical attention blocks combined with carrier tokens at multiple scales to overcome this. Here information from larger regions at coarse resolution is sequentially carried on to finer-resolution regions to predict the super-resolved image. Using transformer layers at each resolution, our coarse-to-fine modeling limits the number of tokens at each scale and enables attention over larger regions than what has previously been possible. We experimentally compare our method, MTVNet, against state-of-the-art volumetric super-resolution models on five 3D datasets demonstrating the advantage of an increased receptive field. This advantage is especially pronounced for images that are larger than what is seen in popularly used 3D datasets. Our code is available at https://github.com/AugustHoeg/MTVNet
Axial and radial axonal diffusivities from single encoding strongly diffusion-weighted MRI
Jul 06, 2022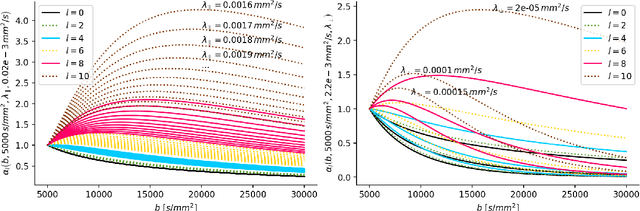
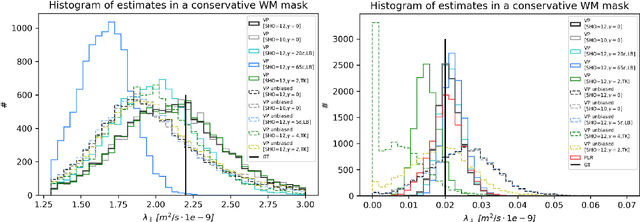
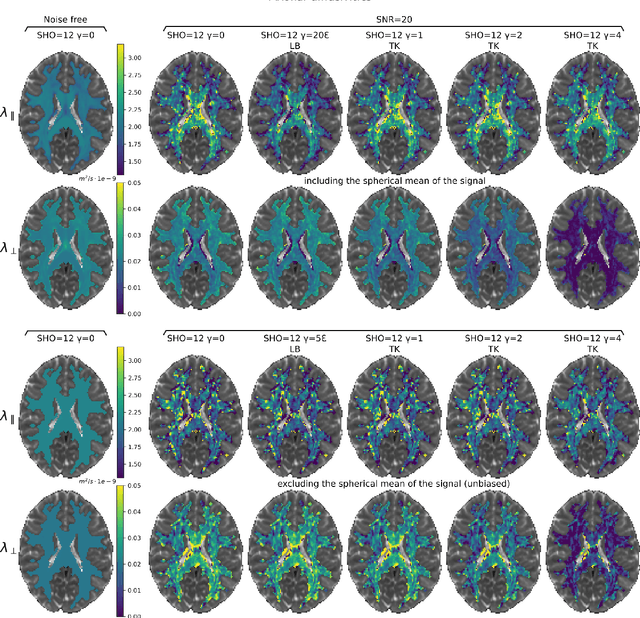
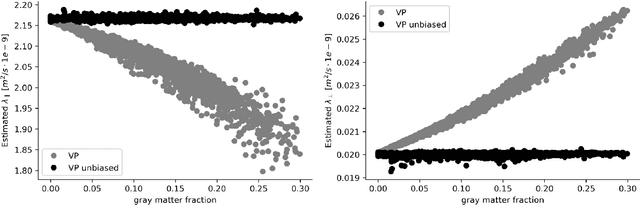
We enable the estimation of the per-axon axial diffusivity from single encoding, strongly diffusion-weighted, pulsed gradient spin echo data. Additionally, we improve the estimation of the per-axon radial diffusivity compared to estimates based on spherical averaging. The use of strong diffusion weightings in magnetic resonance imaging (MRI) allows to approximate the signal in white matter as the sum of the contributions from axons. At the same time, spherical averaging leads to a major simplification of the modeling by removing the need to explicitly account for the unknown orientation distribution of axons. However, the spherically averaged signal acquired at strong diffusion weightings is not sensitive to the axial diffusivity, which cannot therefore be estimated. After revising existing theory, we introduce a new general method for the estimation of both axonal diffusivities at strong diffusion weightings based on zonal harmonics modeling. We additionally show how this could lead to estimates that are free from partial volume bias with, for instance, gray matter. We test the method on publicly available data from the MGH Adult Diffusion Human Connectome project dataset. We report reference values of axonal diffusivities based on 34 subjects, and derive estimates of axonal radii. We address the estimation problem also from the angle of the required data preprocessing, the presence of biases related to modeling assumptions, current limitations, and future possibilities.