 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterialist: Physically Based Editing Using Single-Image Inverse Rendering
Jan 07, 2025



To perform image editing based on single-view, inverse physically based rendering, we present a method combining a learning-based approach with progressive differentiable rendering. Given an image, our method leverages neural networks to predict initial material properties. Progressive differentiable rendering is then used to optimize the environment map and refine the material properties with the goal of closely matching the rendered result to the input image. We require only a single image while other inverse rendering methods based on the rendering equation require multiple views. In comparison to single-view methods that rely on neural renderers, our approach achieves more realistic light material interactions, accurate shadows, and global illumination. Furthermore, with optimized material properties and illumination, our method enables a variety of tasks, including physically based material editing, object insertion, and relighting. We also propose a method for material transparency editing that operates effectively without requiring full scene geometry. Compared with methods based on Stable Diffusion, our approach offers stronger interpretability and more realistic light refraction based on empirical results.
MozzaVID: Mozzarella Volumetric Image Dataset
Dec 06, 2024Influenced by the complexity of volumetric imaging, there is a shortage of established datasets useful for benchmarking volumetric deep-learning models. As a consequence, new and existing models are not easily comparable, limiting the development of architectures optimized specifically for volumetric data. To counteract this trend, we introduce MozzaVID - a large, clean, and versatile volumetric classification dataset. Our dataset contains X-ray computed tomography (CT) images of mozzarella microstructure and enables the classification of 25 cheese types and 149 cheese samples. We provide data in three different resolutions, resulting in three dataset instances containing from 591 to 37,824 images. While being general-purpose, the dataset also facilitates investigating mozzarella structure properties. The structure of food directly affects its functional properties and thus its consumption experience. Understanding food structure helps tune the production and mimicking it enables sustainable alternatives to animal-derived food products. The complex and disordered nature of food structures brings a unique challenge, where a choice of appropriate imaging method, scale, and sample size is not trivial. With this dataset we aim to address these complexities, contributing to more robust structural analysis models. The dataset can be downloaded from: https://archive.compute.dtu.dk/files/public/projects/MozzaVID/.
StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models
Mar 08, 2024The demand for stereo images increases as manufacturers launch more XR devices. To meet this demand, we introduce StereoDiffusion, a method that, unlike traditional inpainting pipelines, is trainning free, remarkably straightforward to use, and it seamlessly integrates into the original Stable Diffusion model. Our method modifies the latent variable to provide an end-to-end, lightweight capability for fast generation of stereo image pairs, without the need for fine-tuning model weights or any post-processing of images. Using the original input to generate a left image and estimate a disparity map for it, we generate the latent vector for the right image through Stereo Pixel Shift operations, complemented by Symmetric Pixel Shift Masking Denoise and Self-Attention Layers Modification methods to align the right-side image with the left-side image. Moreover, our proposed method maintains a high standard of image quality throughout the stereo generation process, achieving state-of-the-art scores in various quantitative evaluations.
Eikonal Fields for Refractive Novel-View Synthesis
Feb 11, 2022
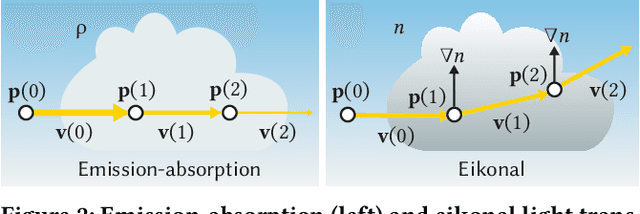

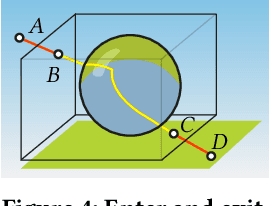
We tackle the problem of generating novel-view images from collections of 2D images showing refractive and reflective objects. Current solutions assume opaque or transparent light transport along straight paths following the emission-absorption model. Instead, we optimize for a field of 3D-varying Index of Refraction (IoR) and trace light through it that bends toward the spatial gradients of said IoR according to the laws of eikonal light transport.
Superaccurate Camera Calibration via Inverse Rendering
Mar 20, 2020The most prevalent routine for camera calibration is based on the detection of well-defined feature points on a purpose-made calibration artifact. These could be checkerboard saddle points, circles, rings or triangles, often printed on a planar structure. The feature points are first detected and then used in a nonlinear optimization to estimate the internal camera parameters.We propose a new method for camera calibration using the principle of inverse rendering. Instead of relying solely on detected feature points, we use an estimate of the internal parameters and the pose of the calibration object to implicitly render a non-photorealistic equivalent of the optical features. This enables us to compute pixel-wise differences in the image domain without interpolation artifacts. We can then improve our estimate of the internal parameters by minimizing pixel-wise least-squares differences. In this way, our model optimizes a meaningful metric in the image space assuming normally distributed noise characteristic for camera sensors.We demonstrate using synthetic and real camera images that our method improves the accuracy of estimated camera parameters as compared with current state-of-the-art calibration routines. Our method also estimates these parameters more robustly in the presence of noise and in situations where the number of calibration images is limited.