 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetKet 3: Machine Learning Toolbox for Many-Body Quantum Systems
Dec 20, 2021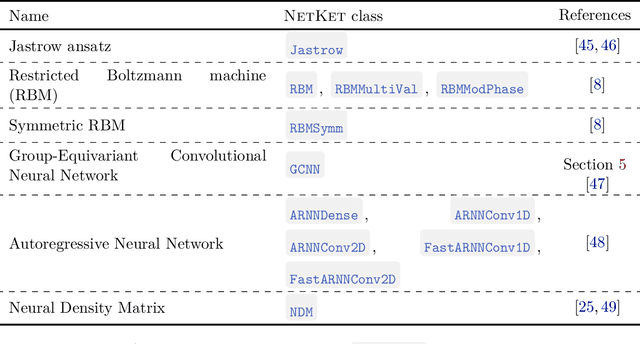
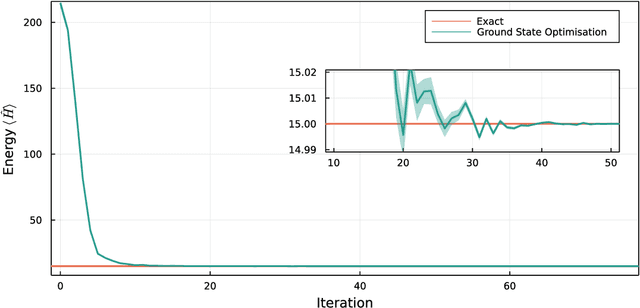
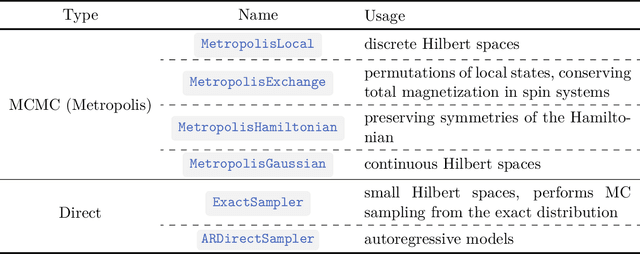
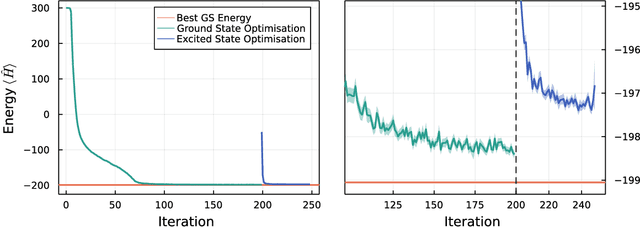
We introduce version 3 of NetKet, the machine learning toolbox for many-body quantum physics. NetKet is built around neural-network quantum states and provides efficient algorithms for their evaluation and optimization. This new version is built on top of JAX, a differentiable programming and accelerated linear algebra framework for the Python programming language. The most significant new feature is the possibility to define arbitrary neural network ans\"atze in pure Python code using the concise notation of machine-learning frameworks, which allows for just-in-time compilation as well as the implicit generation of gradients thanks to automatic differentiation. NetKet 3 also comes with support for GPU and TPU accelerators, advanced support for discrete symmetry groups, chunking to scale up to thousands of degrees of freedom, drivers for quantum dynamics applications, and improved modularity, allowing users to use only parts of the toolbox as a foundation for their own code.
Learning to Deblur and Rotate Motion-Blurred Faces
Dec 14, 2021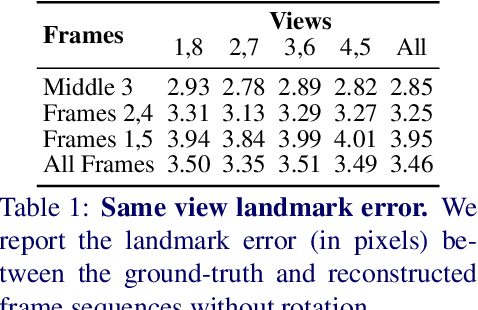
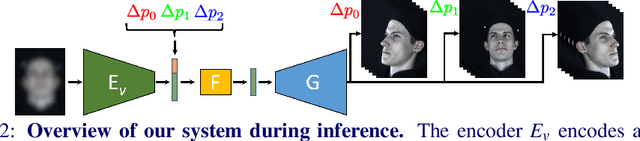
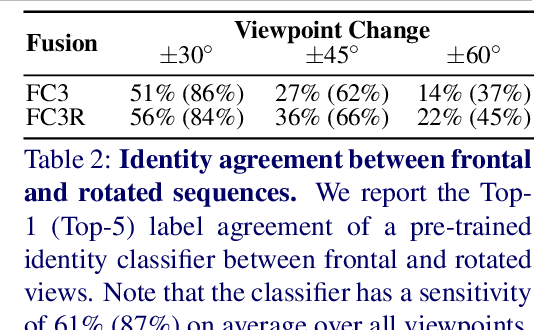
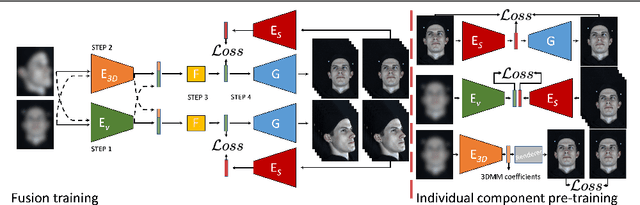
We propose a solution to the novel task of rendering sharp videos from new viewpoints from a single motion-blurred image of a face. Our method handles the complexity of face blur by implicitly learning the geometry and motion of faces through the joint training on three large datasets: FFHQ and 300VW, which are publicly available, and a new Bern Multi-View Face Dataset (BMFD) that we built. The first two datasets provide a large variety of faces and allow our model to generalize better. BMFD instead allows us to introduce multi-view constraints, which are crucial to synthesizing sharp videos from a new camera view. It consists of high frame rate synchronized videos from multiple views of several subjects displaying a wide range of facial expressions. We use the high frame rate videos to simulate realistic motion blur through averaging. Thanks to this dataset, we train a neural network to reconstruct a 3D video representation from a single image and the corresponding face gaze. We then provide a camera viewpoint relative to the estimated gaze and the blurry image as input to an encoder-decoder network to generate a video of sharp frames with a novel camera viewpoint. We demonstrate our approach on test subjects of our multi-view dataset and VIDTIMIT.
Neural network wave functions and the sign problem
Feb 21, 2020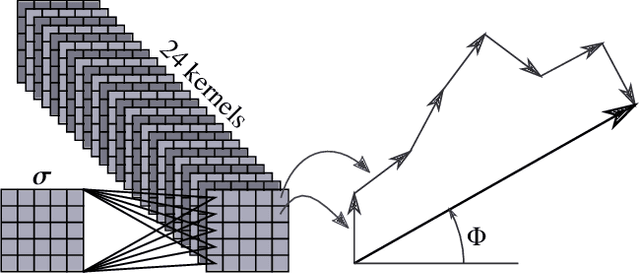


Neural quantum states (NQS) are a promising approach to study many-body quantum physics. However, they face a major challenge when applied to lattice models: Convolutional networks struggle to converge to ground states with a nontrivial sign structure. We tackle this problem by proposing a neural network architecture with a simple, explicit, and interpretable phase ansatz, which can robustly represent such states and achieve state-of-the-art variational energies for both conventional and frustrated antiferromagnets. In the latter case, our approach uncovers low-energy states that exhibit the Marshall sign rule and are therefore inconsistent with the expected ground state. Such states are the likely cause of the obstruction for NQS-based variational Monte Carlo to access the true ground states of these systems. We discuss the implications of this observation and suggest potential strategies to overcome the problem.
Unsupervised Generative 3D Shape Learning from Natural Images
Oct 01, 2019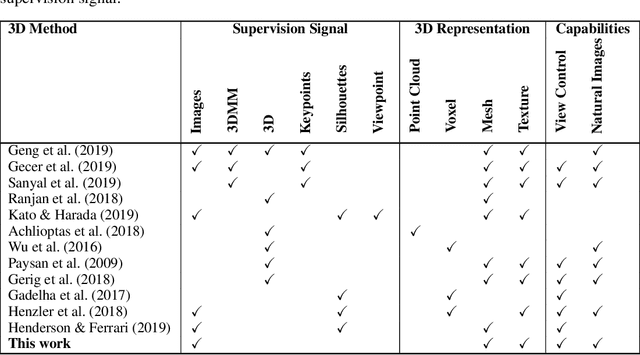


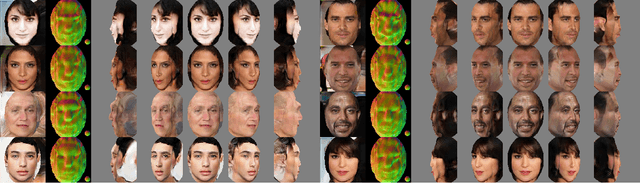
In this paper we present, to the best of our knowledge, the first method to learn a generative model of 3D shapes from natural images in a fully unsupervised way. For example, we do not use any ground truth 3D or 2D annotations, stereo video, and ego-motion during the training. Our approach follows the general strategy of Generative Adversarial Networks, where an image generator network learns to create image samples that are realistic enough to fool a discriminator network into believing that they are natural images. In contrast, in our approach the image generation is split into 2 stages. In the first stage a generator network outputs 3D objects. In the second, a differentiable renderer produces an image of the 3D objects from random viewpoints. The key observation is that a realistic 3D object should yield a realistic rendering from any plausible viewpoint. Thus, by randomizing the choice of the viewpoint our proposed training forces the generator network to learn an interpretable 3D representation disentangled from the viewpoint. In this work, a 3D representation consists of a triangle mesh and a texture map that is used to color the triangle surface by using the UV-mapping technique. We provide analysis of our learning approach, expose its ambiguities and show how to overcome them. Experimentally, we demonstrate that our method can learn realistic 3D shapes of faces by using only the natural images of the FFHQ dataset.
Unsupervised 3D Shape Learning from Image Collections in the Wild
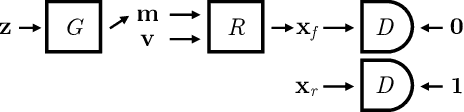
Nov 27, 2018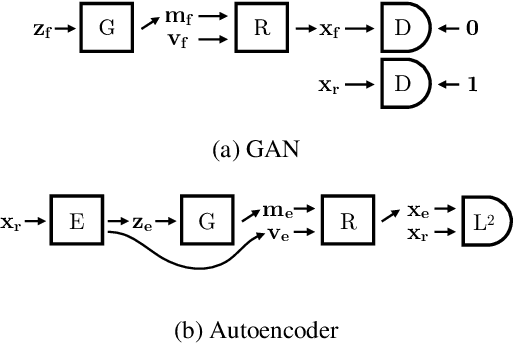
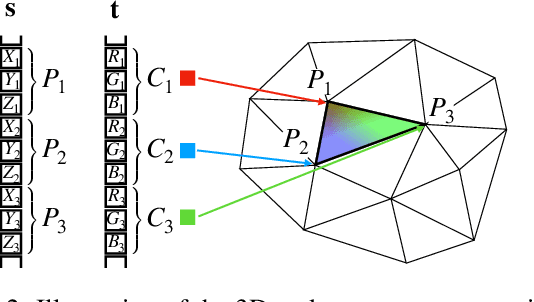

We present a method to learn the 3D surface of objects directly from a collection of images. Previous work achieved this capability by exploiting additional manual annotation, such as object pose, 3D surface templates, temporal continuity of videos, manually selected landmarks, and foreground/background masks. In contrast, our method does not make use of any such annotation. Rather, it builds a generative model, a convolutional neural network, which, given a noise vector sample, outputs the 3D surface and texture of an object and a background image. These 3 components combined with an additional random viewpoint vector are then fed to a differential renderer to produce a view of the sampled object and background. Our general principle is that if the output of the renderer, the generated image, is realistic, then its input, the generated 3D and texture, should also be realistic. To achieve realism, the generative model is trained adversarially against a discriminator that tries to distinguish between the output of the renderer and real images from the given data set. Moreover, our generative model can be paired with an encoder and trained as an autoencoder, to automatically extract the 3D shape, texture and pose of the object in an image. Our trained generative model and encoder show promising results both on real and synthetic data, which demonstrate for the first time that fully unsupervised 3D learning from image collections is possible.
FaceShop: Deep Sketch-based Face Image Editing
Jun 07, 2018
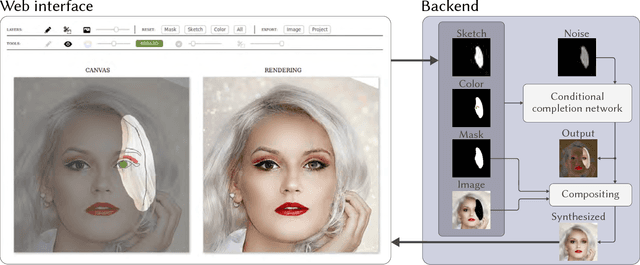
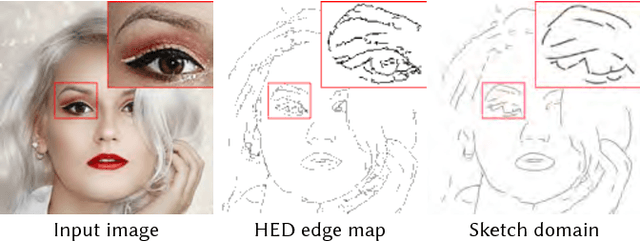

We present a novel system for sketch-based face image editing, enabling users to edit images intuitively by sketching a few strokes on a region of interest. Our interface features tools to express a desired image manipulation by providing both geometry and color constraints as user-drawn strokes. As an alternative to the direct user input, our proposed system naturally supports a copy-paste mode, which allows users to edit a given image region by using parts of another exemplar image without the need of hand-drawn sketching at all. The proposed interface runs in real-time and facilitates an interactive and iterative workflow to quickly express the intended edits. Our system is based on a novel sketch domain and a convolutional neural network trained end-to-end to automatically learn to render image regions corresponding to the input strokes. To achieve high quality and semantically consistent results we train our neural network on two simultaneous tasks, namely image completion and image translation. To the best of our knowledge, we are the first to combine these two tasks in a unified framework for interactive image editing. Our results show that the proposed sketch domain, network architecture, and training procedure generalize well to real user input and enable high quality synthesis results without additional post-processing.
Disentangling Factors of Variation by Mixing Them
Mar 28, 2018


We propose an approach to learn image representations that consist of disentangled factors of variation without exploiting any manual labeling or data domain knowledge. A factor of variation corresponds to an image attribute that can be discerned consistently across a set of images, such as the pose or color of objects. Our disentangled representation consists of a concatenation of feature chunks, each chunk representing a factor of variation. It supports applications such as transferring attributes from one image to another, by simply mixing and unmixing feature chunks, and classification or retrieval based on one or several attributes, by considering a user-specified subset of feature chunks. We learn our representation without any labeling or knowledge of the data domain, using an autoencoder architecture with two novel training objectives: first, we propose an invariance objective to encourage that encoding of each attribute, and decoding of each chunk, are invariant to changes in other attributes and chunks, respectively; second, we include a classification objective, which ensures that each chunk corresponds to a consistently discernible attribute in the represented image, hence avoiding degenerate feature mappings where some chunks are completely ignored. We demonstrate the effectiveness of our approach on the MNIST, Sprites, and CelebA datasets.
Challenges in Disentangling Independent Factors of Variation
Nov 07, 2017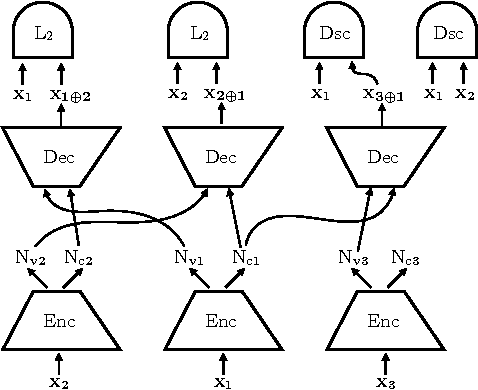

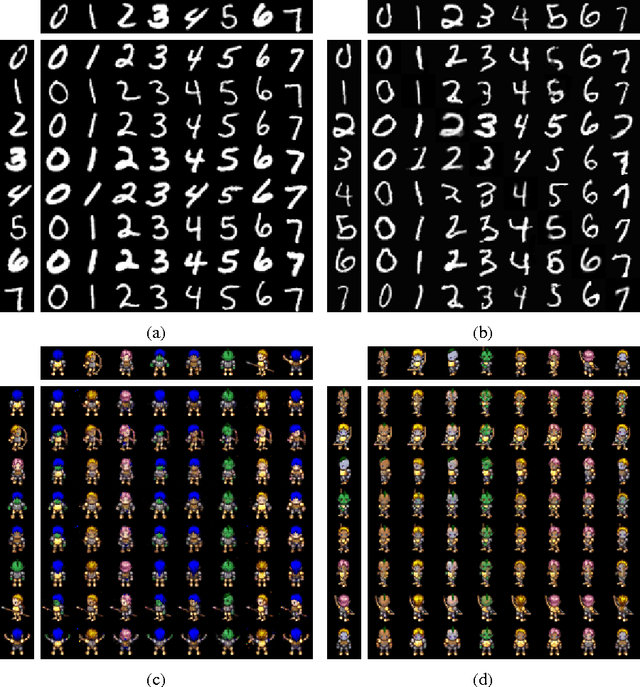

We study the problem of building models that disentangle independent factors of variation. Such models could be used to encode features that can efficiently be used for classification and to transfer attributes between different images in image synthesis. As data we use a weakly labeled training set. Our weak labels indicate what single factor has changed between two data samples, although the relative value of the change is unknown. This labeling is of particular interest as it may be readily available without annotation costs. To make use of weak labels we introduce an autoencoder model and train it through constraints on image pairs and triplets. We formally prove that without additional knowledge there is no guarantee that two images with the same factor of variation will be mapped to the same feature. We call this issue the reference ambiguity. Moreover, we show the role of the feature dimensionality and adversarial training. We demonstrate experimentally that the proposed model can successfully transfer attributes on several datasets, but show also cases when the reference ambiguity occurs.