 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymPlex: A Structure-Aware Transformer for Symbolic PDE Solving
Feb 03, 2026We propose SymPlex, a reinforcement learning framework for discovering analytical symbolic solutions to partial differential equations (PDEs) without access to ground-truth expressions. SymPlex formulates symbolic PDE solving as tree-structured decision-making and optimizes candidate solutions using only the PDE and its boundary conditions. At its core is SymFormer, a structure-aware Transformer that models hierarchical symbolic dependencies via tree-relative self-attention and enforces syntactic validity through grammar-constrained autoregressive decoding, overcoming the limited expressivity of sequence-based generators. Unlike numerical and neural approaches that approximate solutions in discretized or implicit function spaces, SymPlex operates directly in symbolic expression space, enabling interpretable and human-readable solutions that naturally represent non-smooth behavior and explicit parametric dependence. Empirical results demonstrate exact recovery of non-smooth and parametric PDE solutions using deep learning-based symbolic methods.
Smart, Deep Copy-Paste
Mar 15, 2019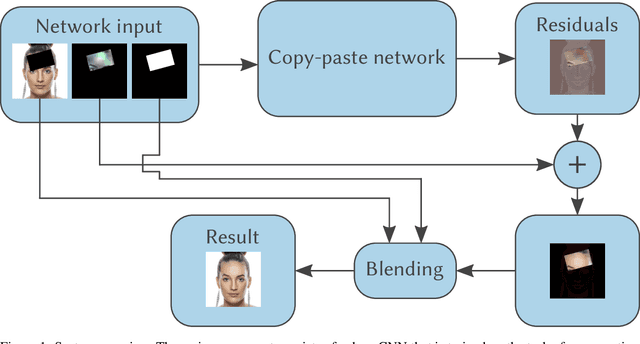



In this work, we propose a novel system for smart copy-paste, enabling the synthesis of high-quality results given a masked source image content and a target image context as input. Our system naturally resolves both shading and geometric inconsistencies between source and target image, resulting in a merged result image that features the content from the pasted source image, seamlessly pasted into the target context. Our framework is based on a novel training image transformation procedure that allows to train a deep convolutional neural network end-to-end to automatically learn a representation that is suitable for copy-pasting. Our training procedure works with any image dataset without additional information such as labels, and we demonstrate the effectiveness of our system on two popular datasets, high-resolution face images and the more complex Cityscapes dataset. Our technique outperforms the current state of the art on face images, and we show promising results on the Cityscapes dataset, demonstrating that our system generalizes to much higher resolution than the training data.
Video Synthesis from a Single Image and Motion Stroke
Dec 05, 2018
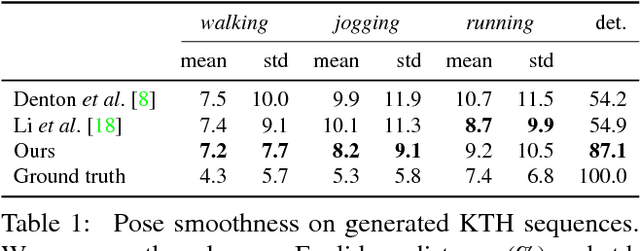
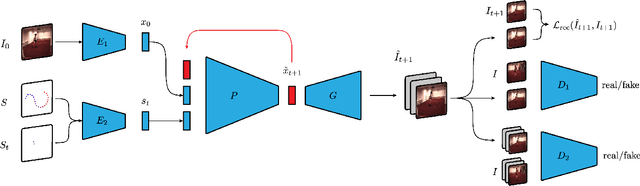

In this paper, we propose a new method to automatically generate a video sequence from a single image and a user provided motion stroke. Generating a video sequence based on a single input image has many applications in visual content creation, but it is tedious and time-consuming to produce even for experienced artists. Automatic methods have been proposed to address this issue, but most existing video prediction approaches require multiple input frames. In addition, generated sequences have limited variety since the output is mostly determined by the input frames, without allowing the user to provide additional constraints on the result. In our technique, users can control the generated animation using a sketch stroke on a single input image. We train our system such that the trajectory of the animated object follows the stroke, which makes it both more flexible and more controllable. From a single image, users can generate a variety of video sequences corresponding to different sketch inputs. Our method is the first system that, given a single frame and a motion stroke, can generate animations by recurrently generating videos frame by frame. An important benefit of the recurrent nature of our architecture is that it facilitates the synthesis of an arbitrary number of generated frames. Our architecture uses an autoencoder and a generative adversarial network (GAN) to generate sharp texture images, and we use another GAN to guarantee that transitions between frames are realistic and smooth. We demonstrate the effectiveness of our approach on the MNIST, KTH, and Human 3.6M datasets.
FaceShop: Deep Sketch-based Face Image Editing
Jun 07, 2018
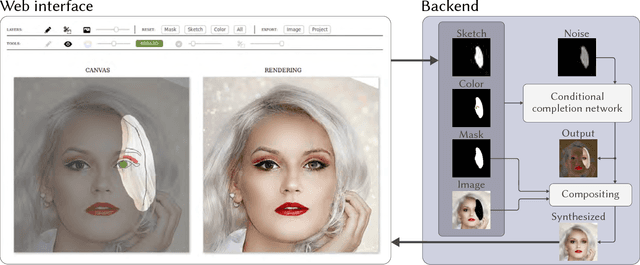
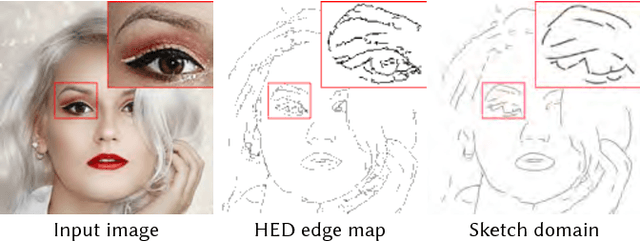

We present a novel system for sketch-based face image editing, enabling users to edit images intuitively by sketching a few strokes on a region of interest. Our interface features tools to express a desired image manipulation by providing both geometry and color constraints as user-drawn strokes. As an alternative to the direct user input, our proposed system naturally supports a copy-paste mode, which allows users to edit a given image region by using parts of another exemplar image without the need of hand-drawn sketching at all. The proposed interface runs in real-time and facilitates an interactive and iterative workflow to quickly express the intended edits. Our system is based on a novel sketch domain and a convolutional neural network trained end-to-end to automatically learn to render image regions corresponding to the input strokes. To achieve high quality and semantically consistent results we train our neural network on two simultaneous tasks, namely image completion and image translation. To the best of our knowledge, we are the first to combine these two tasks in a unified framework for interactive image editing. Our results show that the proposed sketch domain, network architecture, and training procedure generalize well to real user input and enable high quality synthesis results without additional post-processing.
Disentangling Factors of Variation by Mixing Them
Mar 28, 2018
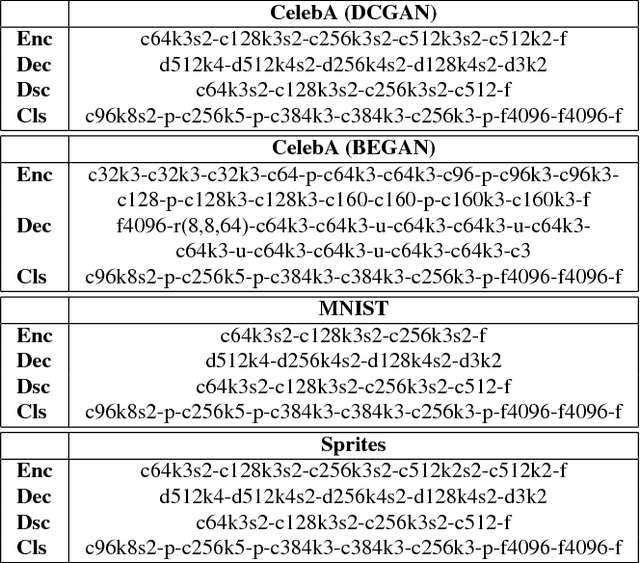


We propose an approach to learn image representations that consist of disentangled factors of variation without exploiting any manual labeling or data domain knowledge. A factor of variation corresponds to an image attribute that can be discerned consistently across a set of images, such as the pose or color of objects. Our disentangled representation consists of a concatenation of feature chunks, each chunk representing a factor of variation. It supports applications such as transferring attributes from one image to another, by simply mixing and unmixing feature chunks, and classification or retrieval based on one or several attributes, by considering a user-specified subset of feature chunks. We learn our representation without any labeling or knowledge of the data domain, using an autoencoder architecture with two novel training objectives: first, we propose an invariance objective to encourage that encoding of each attribute, and decoding of each chunk, are invariant to changes in other attributes and chunks, respectively; second, we include a classification objective, which ensures that each chunk corresponds to a consistently discernible attribute in the represented image, hence avoiding degenerate feature mappings where some chunks are completely ignored. We demonstrate the effectiveness of our approach on the MNIST, Sprites, and CelebA datasets.
Challenges in Disentangling Independent Factors of Variation
Nov 07, 2017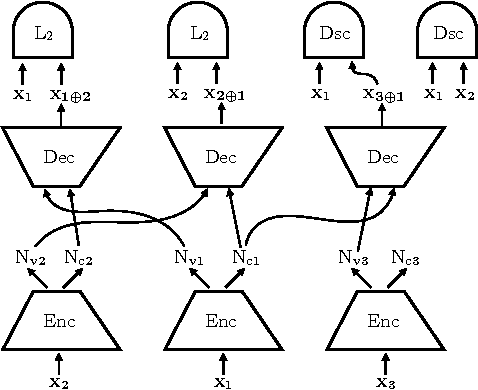

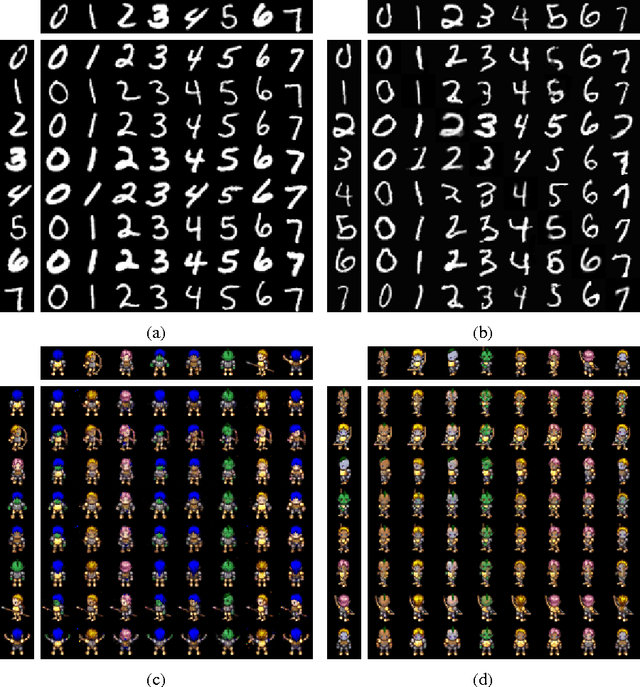

We study the problem of building models that disentangle independent factors of variation. Such models could be used to encode features that can efficiently be used for classification and to transfer attributes between different images in image synthesis. As data we use a weakly labeled training set. Our weak labels indicate what single factor has changed between two data samples, although the relative value of the change is unknown. This labeling is of particular interest as it may be readily available without annotation costs. To make use of weak labels we introduce an autoencoder model and train it through constraints on image pairs and triplets. We formally prove that without additional knowledge there is no guarantee that two images with the same factor of variation will be mapped to the same feature. We call this issue the reference ambiguity. Moreover, we show the role of the feature dimensionality and adversarial training. We demonstrate experimentally that the proposed model can successfully transfer attributes on several datasets, but show also cases when the reference ambiguity occurs.