 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Synthesis from a Single Image and Motion Stroke
Paper and Code

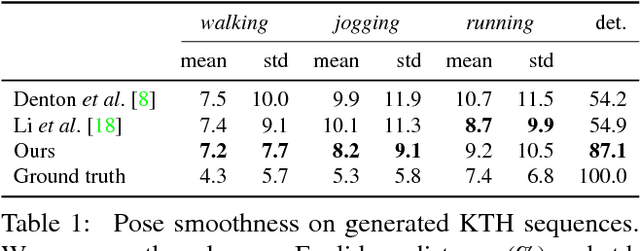
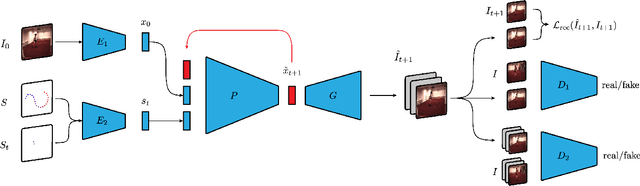

In this paper, we propose a new method to automatically generate a video sequence from a single image and a user provided motion stroke. Generating a video sequence based on a single input image has many applications in visual content creation, but it is tedious and time-consuming to produce even for experienced artists. Automatic methods have been proposed to address this issue, but most existing video prediction approaches require multiple input frames. In addition, generated sequences have limited variety since the output is mostly determined by the input frames, without allowing the user to provide additional constraints on the result. In our technique, users can control the generated animation using a sketch stroke on a single input image. We train our system such that the trajectory of the animated object follows the stroke, which makes it both more flexible and more controllable. From a single image, users can generate a variety of video sequences corresponding to different sketch inputs. Our method is the first system that, given a single frame and a motion stroke, can generate animations by recurrently generating videos frame by frame. An important benefit of the recurrent nature of our architecture is that it facilitates the synthesis of an arbitrary number of generated frames. Our architecture uses an autoencoder and a generative adversarial network (GAN) to generate sharp texture images, and we use another GAN to guarantee that transitions between frames are realistic and smooth. We demonstrate the effectiveness of our approach on the MNIST, KTH, and Human 3.6M datasets.