 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSL-R1: Self-Supervised Visual Reinforcement Post-Training for Multimodal Large Language Models
Apr 22, 2026Reinforcement learning (RL) with verifiable rewards (RLVR) has demonstrated the great potential of enhancing the reasoning abilities in multimodal large language models (MLLMs). However, the reliance on language-centric priors and expensive manual annotations prevents MLLMs' intrinsic visual understanding and scalable reward designs. In this work, we introduce SSL-R1, a generic self-supervised RL framework that derives verifiable rewards directly from images. To this end, we revisit self-supervised learning (SSL) in visual domains and reformulate widely-used SSL tasks into a set of verifiable visual puzzles for RL post-training, requiring neither human nor external model supervision. Training MLLMs on these tasks substantially improves their performance on multimodal understanding and reasoning benchmarks, highlighting the potential of leveraging vision-centric self-supervised tasks for MLLM post-training. We think this work will provide useful experience in devising effective self-supervised verifiable rewards to enable RL at scale. Project page: https://github.com/Jiahao000/SSL-R1.
R-CoV: Region-Aware Chain-of-Verification for Alleviating Object Hallucinations in LVLMs
Apr 22, 2026Large vision-language models (LVLMs) have demonstrated impressive performance in various multimodal understanding and reasoning tasks. However, they still struggle with object hallucinations, i.e., the claim of nonexistent objects in the visual input. To address this challenge, we propose Region-aware Chain-of-Verification (R-CoV), a visual chain-of-verification method to alleviate object hallucinations in LVLMs in a post-hoc manner. Motivated by how humans comprehend intricate visual information -- often focusing on specific image regions or details within a given sample -- we elicit such region-level processing from LVLMs themselves and use it as a chaining cue to detect and alleviate their own object hallucinations. Specifically, our R-CoV consists of six steps: initial response generation, entity extraction, coordinate generation, region description, verification execution, and final response generation. As a simple yet effective method, R-CoV can be seamlessly integrated into various LVLMs in a training-free manner and without relying on external detection models. Extensive experiments on several widely used hallucination benchmarks across multiple LVLMs demonstrate that R-CoV can significantly alleviate object hallucinations in LVLMs. Project page: https://github.com/Jiahao000/R-CoV.
Test-Time Visual In-Context Tuning
Mar 27, 2025



Visual in-context learning (VICL), as a new paradigm in computer vision, allows the model to rapidly adapt to various tasks with only a handful of prompts and examples. While effective, the existing VICL paradigm exhibits poor generalizability under distribution shifts. In this work, we propose test-time Visual In-Context Tuning (VICT), a method that can adapt VICL models on the fly with a single test sample. Specifically, we flip the role between the task prompts and the test sample and use a cycle consistency loss to reconstruct the original task prompt output. Our key insight is that a model should be aware of a new test distribution if it can successfully recover the original task prompts. Extensive experiments on six representative vision tasks ranging from high-level visual understanding to low-level image processing, with 15 common corruptions, demonstrate that our VICT can improve the generalizability of VICL to unseen new domains. In addition, we show the potential of applying VICT for unseen tasks at test time. Code: https://github.com/Jiahao000/VICT.
I Know What I Don't Know: Improving Model Cascades Through Confidence Tuning
Feb 26, 2025Large-scale machine learning models deliver strong performance across a wide range of tasks but come with significant computational and resource constraints. To mitigate these challenges, local smaller models are often deployed alongside larger models, relying on routing and deferral mechanisms to offload complex tasks. However, existing approaches inadequately balance the capabilities of these models, often resulting in unnecessary deferrals or sub-optimal resource usage. In this work we introduce a novel loss function called Gatekeeper for calibrating smaller models in cascade setups. Our approach fine-tunes the smaller model to confidently handle tasks it can perform correctly while deferring complex tasks to the larger model. Moreover, it incorporates a mechanism for managing the trade-off between model performance and deferral accuracy, and is broadly applicable across various tasks and domains without any architectural changes. We evaluate our method on encoder-only, decoder-only, and encoder-decoder architectures. Experiments across image classification, language modeling, and vision-language tasks show that our approach substantially improves deferral performance.
Model Swarms: Collaborative Search to Adapt LLM Experts via Swarm Intelligence
Oct 15, 2024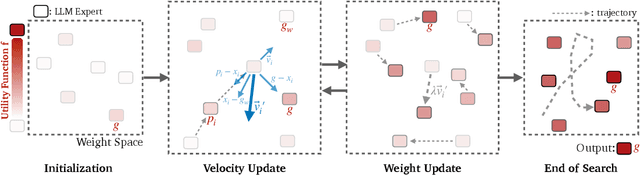
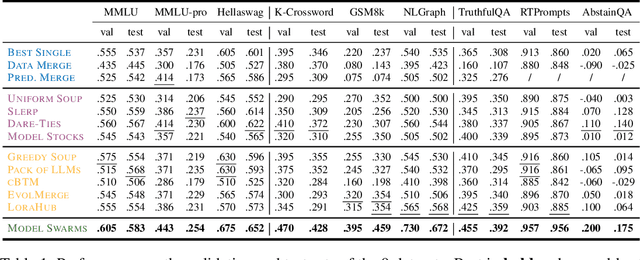
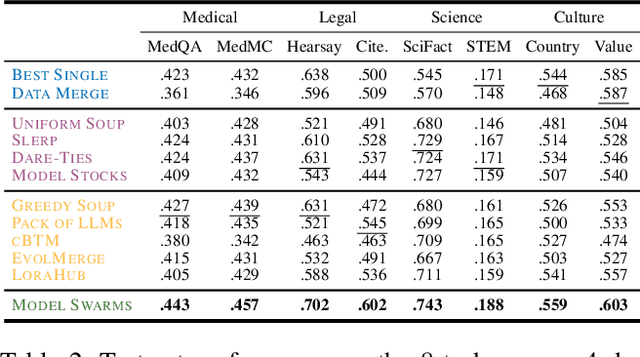
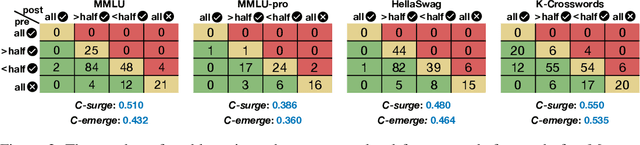
We propose Model Swarms, a collaborative search algorithm to adapt LLMs via swarm intelligence, the collective behavior guiding individual systems. Specifically, Model Swarms starts with a pool of LLM experts and a utility function. Guided by the best-found checkpoints across models, diverse LLM experts collaboratively move in the weight space and optimize a utility function representing model adaptation objectives. Compared to existing model composition approaches, Model Swarms offers tuning-free model adaptation, works in low-data regimes with as few as 200 examples, and does not require assumptions about specific experts in the swarm or how they should be composed. Extensive experiments demonstrate that Model Swarms could flexibly adapt LLM experts to a single task, multi-task domains, reward models, as well as diverse human interests, improving over 12 model composition baselines by up to 21.0% across tasks and contexts. Further analysis reveals that LLM experts discover previously unseen capabilities in initial checkpoints and that Model Swarms enable the weak-to-strong transition of experts through the collaborative search process.
Extracting Training Data from Document-Based VQA Models
Jul 11, 2024



Vision-Language Models (VLMs) have made remarkable progress in document-based Visual Question Answering (i.e., responding to queries about the contents of an input document provided as an image). In this work, we show these models can memorize responses for training samples and regurgitate them even when the relevant visual information has been removed. This includes Personal Identifiable Information (PII) repeated once in the training set, indicating these models could divulge memorised sensitive information and therefore pose a privacy risk. We quantitatively measure the extractability of information in controlled experiments and differentiate between cases where it arises from generalization capabilities or from memorization. We further investigate the factors that influence memorization across multiple state-of-the-art models and propose an effective heuristic countermeasure that empirically prevents the extractability of PII.
Defuse: Harnessing Unrestricted Adversarial Examples for Debugging Models Beyond Test Accuracy
Feb 11, 2021
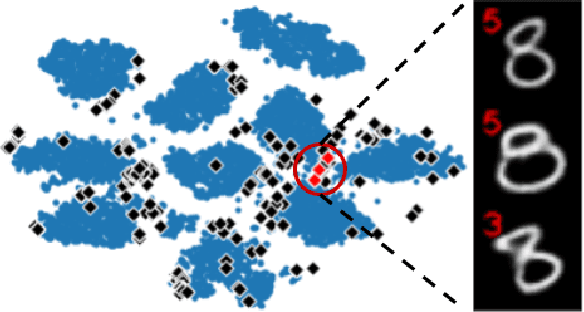

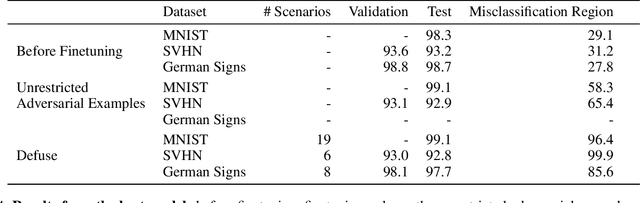
We typically compute aggregate statistics on held-out test data to assess the generalization of machine learning models. However, statistics on test data often overstate model generalization, and thus, the performance of deployed machine learning models can be variable and untrustworthy. Motivated by these concerns, we develop methods to automatically discover and correct model errors beyond those available in the data. We propose Defuse, a method that generates novel model misclassifications, categorizes these errors into high-level model bugs, and efficiently labels and fine-tunes on the errors to correct them. To generate misclassified data, we propose an algorithm inspired by adversarial machine learning techniques that uses a generative model to find naturally occurring instances misclassified by a model. Further, we observe that the generative models have regions in their latent space with higher concentrations of misclassifications. We call these regions misclassification regions and find they have several useful properties. Each region contains a specific type of model bug; for instance, a misclassification region for an MNIST classifier contains a style of skinny 6 that the model mistakes as a 1. We can also assign a single label to each region, facilitating low-cost labeling. We propose a method to learn the misclassification regions and use this insight to both categorize errors and correct them. In practice, Defuse finds and corrects novel errors in classifiers. For example, Defuse shows that a high-performance traffic sign classifier mistakes certain 50km/h signs as 80km/h. Defuse corrects the error after fine-tuning while maintaining generalization on the test set.