 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefuse: Harnessing Unrestricted Adversarial Examples for Debugging Models Beyond Test Accuracy
Paper and Code

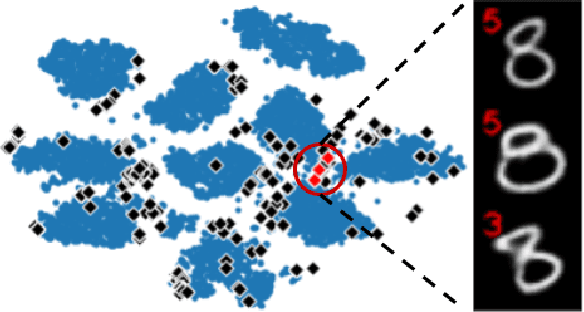

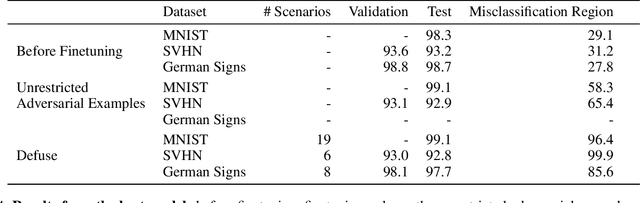
We typically compute aggregate statistics on held-out test data to assess the generalization of machine learning models. However, statistics on test data often overstate model generalization, and thus, the performance of deployed machine learning models can be variable and untrustworthy. Motivated by these concerns, we develop methods to automatically discover and correct model errors beyond those available in the data. We propose Defuse, a method that generates novel model misclassifications, categorizes these errors into high-level model bugs, and efficiently labels and fine-tunes on the errors to correct them. To generate misclassified data, we propose an algorithm inspired by adversarial machine learning techniques that uses a generative model to find naturally occurring instances misclassified by a model. Further, we observe that the generative models have regions in their latent space with higher concentrations of misclassifications. We call these regions misclassification regions and find they have several useful properties. Each region contains a specific type of model bug; for instance, a misclassification region for an MNIST classifier contains a style of skinny 6 that the model mistakes as a 1. We can also assign a single label to each region, facilitating low-cost labeling. We propose a method to learn the misclassification regions and use this insight to both categorize errors and correct them. In practice, Defuse finds and corrects novel errors in classifiers. For example, Defuse shows that a high-performance traffic sign classifier mistakes certain 50km/h signs as 80km/h. Defuse corrects the error after fine-tuning while maintaining generalization on the test set.