 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Know What I Don't Know: Improving Model Cascades Through Confidence Tuning
Feb 26, 2025Large-scale machine learning models deliver strong performance across a wide range of tasks but come with significant computational and resource constraints. To mitigate these challenges, local smaller models are often deployed alongside larger models, relying on routing and deferral mechanisms to offload complex tasks. However, existing approaches inadequately balance the capabilities of these models, often resulting in unnecessary deferrals or sub-optimal resource usage. In this work we introduce a novel loss function called Gatekeeper for calibrating smaller models in cascade setups. Our approach fine-tunes the smaller model to confidently handle tasks it can perform correctly while deferring complex tasks to the larger model. Moreover, it incorporates a mechanism for managing the trade-off between model performance and deferral accuracy, and is broadly applicable across various tasks and domains without any architectural changes. We evaluate our method on encoder-only, decoder-only, and encoder-decoder architectures. Experiments across image classification, language modeling, and vision-language tasks show that our approach substantially improves deferral performance.
LLM Cascade with Multi-Objective Optimal Consideration
Oct 10, 2024

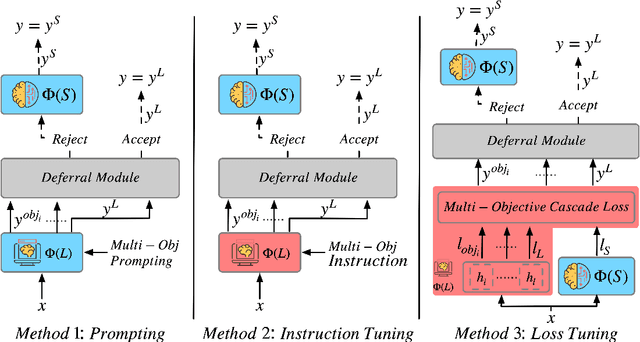
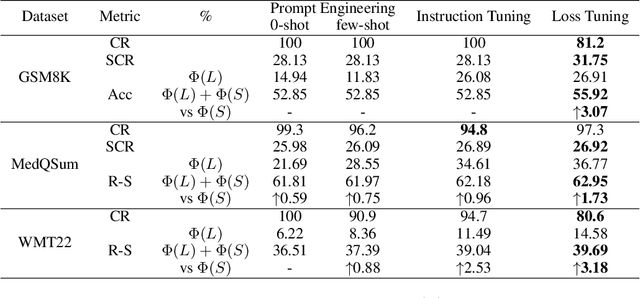
Large Language Models (LLMs) have demonstrated exceptional capabilities in understanding and generating natural language. However, their high deployment costs often pose a barrier to practical applications, especially. Cascading local and server models offers a promising solution to this challenge. While existing studies on LLM cascades have primarily focused on the performance-cost trade-off, real-world scenarios often involve more complex requirements. This paper introduces a novel LLM Cascade strategy with Multi-Objective Optimization, enabling LLM cascades to consider additional objectives (e.g., privacy) and better align with the specific demands of real-world applications while maintaining their original cascading abilities. Extensive experiments on three benchmarks validate the effectiveness and superiority of our approach.
Cascade-Aware Training of Language Models
May 29, 2024



Reducing serving cost and latency is a fundamental concern for the deployment of language models (LMs) in business applications. To address this, cascades of LMs offer an effective solution that conditionally employ smaller models for simpler queries. Cascaded systems are typically built with independently trained models, neglecting the advantages of considering inference-time interactions of the cascaded LMs during training. In this paper, we present cascade-aware training(CAT), an approach to optimizing the overall quality-cost performance tradeoff of a cascade of LMs. We achieve inference-time benefits by training the small LM with awareness of its place in a cascade and downstream capabilities. We demonstrate the value of the proposed method with over 60 LM tasks of the SuperGLUE, WMT22, and FLAN2021 datasets.
Efficient Global Multi-object Tracking Under Minimum-cost Circulation Framework
Nov 02, 2019
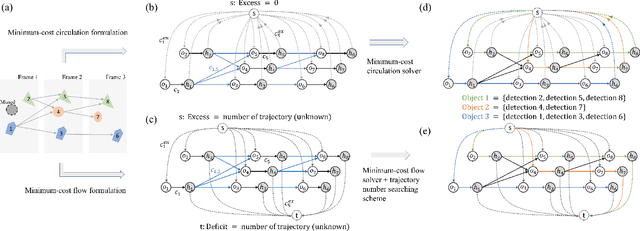

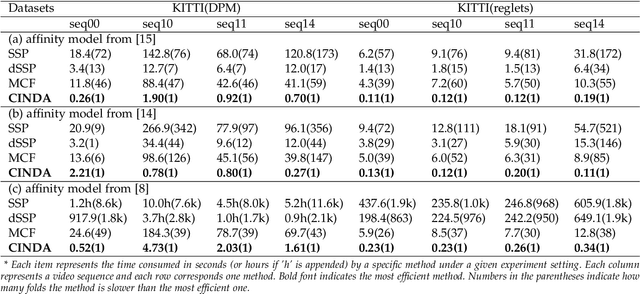
We developed a minimum-cost circulation framework for solving the global data association problem, which plays a key role in the tracking-by-detection paradigm of multi-object tracking. The global data association problem was extensively studied under the minimum-cost flow framework, which is theoretically attractive as being flexible and globally solvable. However, the high computational burden has been a long-standing obstacle to its wide adoption in practice. While enjoying the same theoretical advantages and maintaining the same optimal solution as the minimum-cost flow framework, our new framework has a better theoretical complexity bound and leads to orders of practical efficiency improvement. This new framework is motivated by the observation that minimum-cost flow only partially models the data association problem and must be accompanied by an additional and time-consuming searching scheme to determine the optimal object number. By employing a minimum-cost circulation framework, we eliminate the searching step and naturally integrate the number of objects into the optimization problem. By exploring the special property of the associated graph, that is, an overwhelming majority of the vertices are with unit capacity, we designed an implementation of the framework and proved it has the best theoretical complexity so far for the global data association problem. We evaluated our method with 40 experiments on five MOT benchmark datasets. Our method was always the most efficient and averagely 53 to 1,192 times faster than the three state-of-the-art methods. When our method served as a sub-module for global data association methods using higher-order constraints, similar efficiency improvement was attained. We further illustrated through several case studies how the improved computational efficiency enables more sophisticated tracking models and yields better tracking accuracy.