 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased and Biased Variance-Reduced Forward-Reflected-Backward Splitting Methods for Stochastic Composite Inclusions
Mar 16, 2026This paper develops new variance-reduction techniques for the forward-reflected-backward splitting (FRBS) method to solve a class of possibly nonmonotone stochastic composite inclusions. Unlike unbiased estimators such as mini-batching, developing stochastic biased variants faces a fundamental technical challenge and has not been utilized before for inclusions and fixed-point problems. We fill this gap by designing a new framework that can handle both unbiased and biased estimators. Our main idea is to construct stochastic variance-reduced estimators for the forward-reflected direction and use them to perform iterate updates. First, we propose a class of unbiased variance-reduced estimators and show that increasing mini-batch SGD, loopless-SVRG, and SAGA estimators fall within this class. For these unbiased estimators, we establish a $\mathcal{O}(1/k)$ best-iterate convergence rate for the expected squared residual norm, together with almost-sure convergence of the iterate sequence to a solution. Consequently, we prove that the best oracle complexities for the $n$-finite-sum and expectation settings are $\mathcal{O}(n^{2/3}ε^{-2})$ and $\mathcal{O}(ε^{-10/3})$, respectively, when employing loopless-SVRG or SAGA, where $ε$ is a desired accuracy. Second, we introduce a new class of biased variance-reduced estimators for the forward-reflected direction, which includes SARAH, Hybrid SGD, and Hybrid SVRG as special instances. While the convergence rates remain valid for these biased estimators, the resulting oracle complexities are $\mathcal{O}(n^{3/4}ε^{-2})$ and $\mathcal{O}(ε^{-5})$ for the $n$-finite-sum and expectation settings, respectively. Finally, we conduct two numerical experiments on AUC optimization for imbalanced classification and policy evaluation in reinforcement learning.
A Class of Accelerated Fixed-Point-Based Methods with Delayed Inexact Oracles and Its Applications
Dec 15, 2025



In this paper, we develop a novel accelerated fixed-point-based framework using delayed inexact oracles to approximate a fixed point of a nonexpansive operator (or equivalently, a root of a co-coercive operator), a central problem in scientific computing. Our approach leverages both Nesterov's acceleration technique and the Krasnosel'skii-Mann (KM) iteration, while accounting for delayed inexact oracles, a key mechanism in asynchronous algorithms. We also introduce a unified approximate error condition for delayed inexact oracles, which can cover various practical scenarios. Under mild conditions and appropriate parameter updates, we establish both $\mathcal{O}(1/k^2)$ non-asymptotic and $o(1/k^2)$ asymptotic convergence rates in expectation for the squared norm of residual. Our rate significantly improves the $\mathcal{O}(1/k)$ rates in classical KM-type methods, including their asynchronous variants. We also establish $o(1/k^2)$ almost sure convergence rates and the almost sure convergence of iterates to a solution of the problem. Within our framework, we instantiate three settings for the underlying operator: (i) a deterministic universal delayed oracle; (ii) a stochastic delayed oracle; and (iii) a finite-sum structure with asynchronous updates. For each case, we instantiate our framework to obtain a concrete algorithmic variant for which our convergence results still apply, and whose iteration complexity depends linearly on the maximum delay. Finally, we verify our algorithms and theoretical results through two numerical examples on both matrix game and shallow neural network training problems.
Variance-Reduced Fast Operator Splitting Methods for Stochastic Generalized Equations
Apr 17, 2025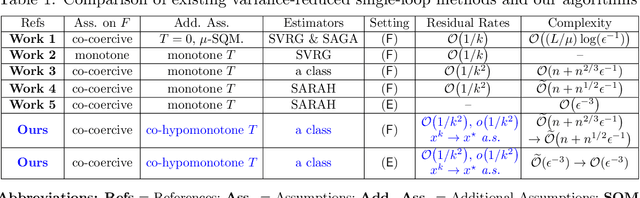



We develop two classes of variance-reduced fast operator splitting methods to approximate solutions of both finite-sum and stochastic generalized equations. Our approach integrates recent advances in accelerated fixed-point methods, co-hypomonotonicity, and variance reduction. First, we introduce a class of variance-reduced estimators and establish their variance-reduction bounds. This class covers both unbiased and biased instances and comprises common estimators as special cases, including SVRG, SAGA, SARAH, and Hybrid-SGD. Next, we design a novel accelerated variance-reduced forward-backward splitting (FBS) algorithm using these estimators to solve finite-sum and stochastic generalized equations. Our method achieves both $\mathcal{O}(1/k^2)$ and $o(1/k^2)$ convergence rates on the expected squared norm $\mathbb{E}[ \| G_{\lambda}x^k\|^2]$ of the FBS residual $G_{\lambda}$, where $k$ is the iteration counter. Additionally, we establish, for the first time, almost sure convergence rates and almost sure convergence of iterates to a solution in stochastic accelerated methods. Unlike existing stochastic fixed-point algorithms, our methods accommodate co-hypomonotone operators, which potentially include nonmonotone problems arising from recent applications. We further specify our method to derive an appropriate variant for each stochastic estimator -- SVRG, SAGA, SARAH, and Hybrid-SGD -- demonstrating that they achieve the best-known complexity for each without relying on enhancement techniques. Alternatively, we propose an accelerated variance-reduced backward-forward splitting (BFS) method, which attains similar convergence rates and oracle complexity as our FBS method. Finally, we validate our results through several numerical experiments and compare their performance.
Accelerated Extragradient-Type Methods -- Part 2: Generalization and Sublinear Convergence Rates under Co-Hypomonotonicity
Jan 08, 2025



Following the first part of our project, this paper comprehensively studies two types of extragradient-based methods: anchored extragradient and Nesterov's accelerated extragradient for solving [non]linear inclusions (and, in particular, equations), primarily under the Lipschitz continuity and the co-hypomonotonicity assumptions. We unify and generalize a class of anchored extragradient methods for monotone inclusions to a wider range of schemes encompassing existing algorithms as special cases. We establish $\mathcal{O}(1/k)$ last-iterate convergence rates on the residual norm of the underlying mapping for this general framework and then specialize it to obtain convergence guarantees for specific instances, where $k$ denotes the iteration counter. We extend our approach to a class of anchored Tseng's forward-backward-forward splitting methods to obtain a broader class of algorithms for solving co-hypomonotone inclusions. Again, we analyze $\mathcal{O}(1/k)$ last-iterate convergence rates for this general scheme and specialize it to obtain convergence results for existing and new variants. We generalize and unify Nesterov's accelerated extra-gradient method to a new class of algorithms that covers existing schemes as special instances while generating new variants. For these schemes, we can prove $\mathcal{O}(1/k)$ last-iterate convergence rates for the residual norm under co-hypomonotonicity, covering a class of nonmonotone problems. We propose another novel class of Nesterov's accelerated extragradient methods to solve inclusions. Interestingly, these algorithms achieve both $\mathcal{O}(1/k)$ and $o(1/k)$ last-iterate convergence rates, and also the convergence of iterate sequences under co-hypomonotonicity and Lipschitz continuity. Finally, we provide a set of numerical experiments encompassing different scenarios to validate our algorithms and theoretical guarantees.
Shuffling Gradient-Based Methods for Nonconvex-Concave Minimax Optimization
Oct 29, 2024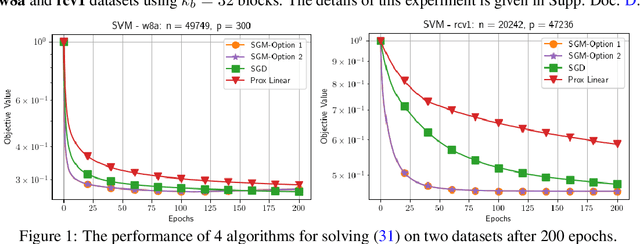



This paper aims at developing novel shuffling gradient-based methods for tackling two classes of minimax problems: nonconvex-linear and nonconvex-strongly concave settings. The first algorithm addresses the nonconvex-linear minimax model and achieves the state-of-the-art oracle complexity typically observed in nonconvex optimization. It also employs a new shuffling estimator for the "hyper-gradient", departing from standard shuffling techniques in optimization. The second method consists of two variants: semi-shuffling and full-shuffling schemes. These variants tackle the nonconvex-strongly concave minimax setting. We establish their oracle complexity bounds under standard assumptions, which, to our best knowledge, are the best-known for this specific setting. Numerical examples demonstrate the performance of our algorithms and compare them with two other methods. Our results show that the new methods achieve comparable performance with SGD, supporting the potential of incorporating shuffling strategies into minimax algorithms.
* 45 pages, 5 figures (38th Conference on Neural Information Processing Systems (NeurIPS 2024))
Revisiting Extragradient-Type Methods -- Part 1: Generalizations and Sublinear Convergence Rates
Sep 25, 2024



This paper presents a comprehensive analysis of the well-known extragradient (EG) method for solving both equations and inclusions. First, we unify and generalize EG for [non]linear equations to a wider class of algorithms, encompassing various existing schemes and potentially new variants. Next, we analyze both sublinear ``best-iterate'' and ``last-iterate'' convergence rates for the entire class of algorithms, and derive new convergence results for two well-known instances. Second, we extend our EG framework above to ``monotone'' inclusions, introducing a new class of algorithms and its corresponding convergence results. Third, we also unify and generalize Tseng's forward-backward-forward splitting (FBFS) method to a broader class of algorithms to solve [non]linear inclusions when a weak-Minty solution exists, and establish its ``best-iterate'' convergence rate. Fourth, to complete our picture, we also investigate sublinear rates of two other common variants of EG using our EG analysis framework developed here: the reflected forward-backward splitting and the golden ratio methods. Finally, we conduct an extensive numerical experiment to validate our theoretical findings. Our results demonstrate that several new variants of our proposed algorithms outperform existing schemes in the majority of examples.
Accelerated Variance-Reduced Forward-Reflected Methods for Root-Finding Problems
Jun 04, 2024

We propose a novel class of Nesterov's stochastic accelerated forward-reflected-based methods with variance reduction to solve root-finding problems under $\frac{1}{L}$-co-coerciveness. Our algorithm is single-loop and leverages a new family of unbiased variance-reduced estimators specifically designed for root-finding problems. It achieves both $\mathcal{O}(L^2/k^2)$ and $o(1/k^2)$-last-iterate convergence rates in terms of expected operator squared norm, where $k$ denotes the iteration counter. We instantiate our framework for two prominent estimators: SVRG and SAGA. By an appropriate choice of parameters, both variants attain an oracle complexity of $\mathcal{O}( n + Ln^{2/3}\epsilon^{-1})$ to reach an $\epsilon$-solution, where $n$ represents the number of summands in the finite-sum operator. Furthermore, under $\mu$-strong quasi-monotonicity, our method achieves a linear convergence rate and an oracle complexity of $\mathcal{O}(n+ \kappa n^{2/3}\log(\epsilon^{-1}))$, where $\kappa := \frac{L}{\mu}$. We extend our approach to solve a class of finite-sum monotone inclusions, demonstrating that our schemes retain the same theoretical guarantees as in the equation setting. Finally, numerical experiments validate our algorithms and demonstrate their promising performance compared to state-of-the-art methods.
Shuffling Momentum Gradient Algorithm for Convex Optimization
Mar 05, 2024The Stochastic Gradient Descent method (SGD) and its stochastic variants have become methods of choice for solving finite-sum optimization problems arising from machine learning and data science thanks to their ability to handle large-scale applications and big datasets. In the last decades, researchers have made substantial effort to study the theoretical performance of SGD and its shuffling variants. However, only limited work has investigated its shuffling momentum variants, including shuffling heavy-ball momentum schemes for non-convex problems and Nesterov's momentum for convex settings. In this work, we extend the analysis of the shuffling momentum gradient method developed in [Tran et al (2021)] to both finite-sum convex and strongly convex optimization problems. We provide the first analysis of shuffling momentum-based methods for the strongly convex setting, attaining a convergence rate of $O(1/nT^2)$, where $n$ is the number of samples and $T$ is the number of training epochs. Our analysis is a state-of-the-art, matching the best rates of existing shuffling stochastic gradient algorithms in the literature.
Sublinear Convergence Rates of Extragradient-Type Methods: A Survey on Classical and Recent Developments
Mar 30, 2023
The extragradient (EG), introduced by G. M. Korpelevich in 1976, is a well-known method to approximate solutions of saddle-point problems and their extensions such as variational inequalities and monotone inclusions. Over the years, numerous variants of EG have been proposed and studied in the literature. Recently, these methods have gained popularity due to new applications in machine learning and robust optimization. In this work, we survey the latest developments in the EG method and its variants for approximating solutions of nonlinear equations and inclusions, with a focus on the monotonicity and co-hypomonotonicity settings. We provide a unified convergence analysis for different classes of algorithms, with an emphasis on sublinear best-iterate and last-iterate convergence rates. We also discuss recent accelerated variants of EG based on both Halpern fixed-point iteration and Nesterov's accelerated techniques. Our approach uses simple arguments and basic mathematical tools to make the proofs as elementary as possible, while maintaining generality to cover a broad range of problems.
Extragradient-Type Methods with $\mathcal{O}(1/k)$ Convergence Rates for Co-Hypomonotone Inclusions
Feb 08, 2023In this paper, we develop two ``Nesterov's accelerated'' variants of the well-known extragradient method to approximate a solution of a co-hypomonotone inclusion constituted by the sum of two operators, where one is Lipschitz continuous and the other is possibly multivalued. The first scheme can be viewed as an accelerated variant of Tseng's forward-backward-forward splitting method, while the second one is a variant of the reflected forward-backward splitting method, which requires only one evaluation of the Lipschitz operator, and one resolvent of the multivalued operator. Under a proper choice of the algorithmic parameters and appropriate conditions on the co-hypomonotone parameter, we theoretically prove that both algorithms achieve $\mathcal{O}(1/k)$ convergence rates on the norm of the residual, where $k$ is the iteration counter. Our results can be viewed as alternatives of a recent class of Halpern-type schemes for root-finding problems.