 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiVeGen -- Hierarchical LLM-based Verilog Generation for Scalable Chip Design
Dec 06, 2024



With Large Language Models (LLMs) recently demonstrating impressive proficiency in code generation, it is promising to extend their abilities to Hardware Description Language (HDL). However, LLMs tend to generate single HDL code blocks rather than hierarchical structures for hardware designs, leading to hallucinations, particularly in complex designs like Domain-Specific Accelerators (DSAs). To address this, we propose HiVeGen, a hierarchical LLM-based Verilog generation framework that decomposes generation tasks into LLM-manageable hierarchical submodules. HiVeGen further harnesses the advantages of such hierarchical structures by integrating automatic Design Space Exploration (DSE) into hierarchy-aware prompt generation, introducing weight-based retrieval to enhance code reuse, and enabling real-time human-computer interaction to lower error-correction cost, significantly improving the quality of generated designs.
Advanced Language Model-Driven Verilog Development: Enhancing Power, Performance, and Area Optimization in Code Synthesis
Dec 02, 2023The increasing use of Advanced Language Models (ALMs) in diverse sectors, particularly due to their impressive capability to generate top-tier content following linguistic instructions, forms the core of this investigation. This study probes into ALMs' deployment in electronic hardware design, with a specific emphasis on the synthesis and enhancement of Verilog programming. We introduce an innovative framework, crafted to assess and amplify ALMs' productivity in this niche. The methodology commences with the initial crafting of Verilog programming via ALMs, succeeded by a distinct dual-stage refinement protocol. The premier stage prioritizes augmenting the code's operational and linguistic precision, while the latter stage is dedicated to aligning the code with Power-Performance-Area (PPA) benchmarks, a pivotal component in proficient hardware design. This bifurcated strategy, merging error remediation with PPA enhancement, has yielded substantial upgrades in the caliber of ALM-created Verilog programming. Our framework achieves an 81.37% rate in linguistic accuracy and 62.0% in operational efficacy in programming synthesis, surpassing current leading-edge techniques, such as 73% in linguistic accuracy and 46% in operational efficacy. These findings illuminate ALMs' aptitude in tackling complex technical domains and signal a positive shift in the mechanization of hardware design operations.
LinGCN: Structural Linearized Graph Convolutional Network for Homomorphically Encrypted Inference
Sep 30, 2023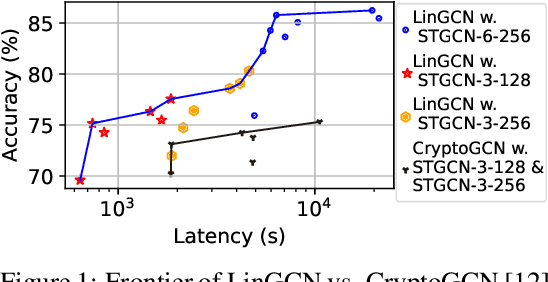

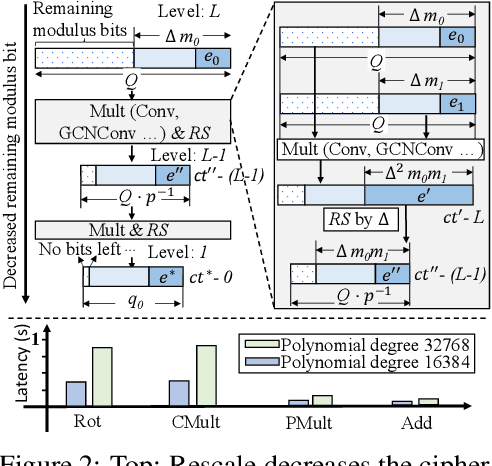
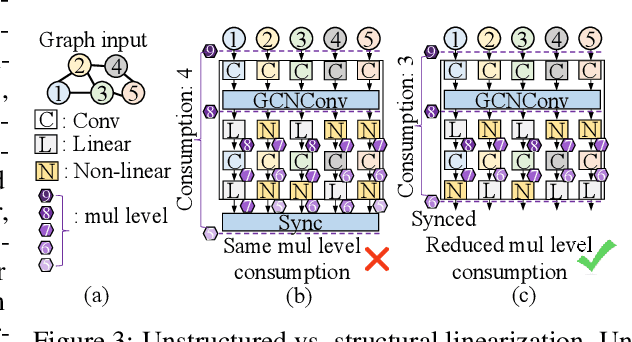
The growth of Graph Convolution Network (GCN) model sizes has revolutionized numerous applications, surpassing human performance in areas such as personal healthcare and financial systems. The deployment of GCNs in the cloud raises privacy concerns due to potential adversarial attacks on client data. To address security concerns, Privacy-Preserving Machine Learning (PPML) using Homomorphic Encryption (HE) secures sensitive client data. However, it introduces substantial computational overhead in practical applications. To tackle those challenges, we present LinGCN, a framework designed to reduce multiplication depth and optimize the performance of HE based GCN inference. LinGCN is structured around three key elements: (1) A differentiable structural linearization algorithm, complemented by a parameterized discrete indicator function, co-trained with model weights to meet the optimization goal. This strategy promotes fine-grained node-level non-linear location selection, resulting in a model with minimized multiplication depth. (2) A compact node-wise polynomial replacement policy with a second-order trainable activation function, steered towards superior convergence by a two-level distillation approach from an all-ReLU based teacher model. (3) an enhanced HE solution that enables finer-grained operator fusion for node-wise activation functions, further reducing multiplication level consumption in HE-based inference. Our experiments on the NTU-XVIEW skeleton joint dataset reveal that LinGCN excels in latency, accuracy, and scalability for homomorphically encrypted inference, outperforming solutions such as CryptoGCN. Remarkably, LinGCN achieves a 14.2x latency speedup relative to CryptoGCN, while preserving an inference accuracy of 75% and notably reducing multiplication depth.