 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGI: Structured 2D Gaussians for Efficient and Compact Large Image Representation
Mar 10, 20262D Gaussian Splatting has emerged as a novel image representation technique that can support efficient rendering on low-end devices. However, scaling to high-resolution images requires optimizing and storing millions of unstructured Gaussian primitives independently, leading to slow convergence and redundant parameters. To address this, we propose Structured Gaussian Image (SGI), a compact and efficient framework for representing high-resolution images. SGI decomposes a complex image into multi-scale local spaces defined by a set of seeds. Each seed corresponds to a spatially coherent region and, together with lightweight multi-layer perceptrons (MLPs), generates structured implicit 2D neural Gaussians. This seed-based formulation imposes structural regularity on otherwise unstructured Gaussian primitives, which facilitates entropy-based compression at the seed level to reduce the total storage. However, optimizing seed parameters directly on high-resolution images is a challenging and non-trivial task. Therefore, we designed a multi-scale fitting strategy that refines the seed representation in a coarse-to-fine manner, substantially accelerating convergence. Quantitative and qualitative evaluations demonstrate that SGI achieves up to 7.5x compression over prior non-quantized 2D Gaussian methods and 1.6x over quantized ones, while also delivering 1.6x and 6.5x faster optimization, respectively, without degrading, and often improving, image fidelity. Code is available at https://github.com/zx-pan/SGI.
When Small Variations Become Big Failures: Reliability Challenges in Compute-in-Memory Neural Accelerators
Mar 03, 2026Compute-in-memory (CiM) architectures promise significant improvements in energy efficiency and throughput for deep neural network acceleration by alleviating the von Neumann bottleneck. However, their reliance on emerging non-volatile memory devices introduces device-level non-idealities-such as write variability, conductance drift, and stochastic noise-that fundamentally challenge reliability, predictability, and safety, especially in safety-critical applications. This talk examines the reliability limits of CiM-based neural accelerators and presents a series of techniques that bridge device physics, architecture, and learning algorithms to address these challenges. We first demonstrate that even small device variations can lead to disproportionately large accuracy degradation and catastrophic failures in safety-critical inference workloads, revealing a critical gap between average-case evaluations and worst-case behavior. Building on this insight, we introduce SWIM, a selective write-verify mechanism that strategically applies verification only where it is most impactful, significantly improving reliability while maintaining CiM's efficiency advantages. Finally, we explore a learning-centric solution that improves realistic worst-case performance by training neural networks with right-censored Gaussian noise, aligning training assumptions with hardware-induced variability and enabling robust deployment without excessive hardware overhead. Together, these works highlight the necessity of cross-layer co-design for CiM accelerators and provide a principled path toward dependable, efficient neural inference on emerging memory technologies-paving the way for their adoption in safety- and reliability-critical systems.
A 10.60 $μ$W 150 GOPS Mixed-Bit-Width Sparse CNN Accelerator for Life-Threatening Ventricular Arrhythmia Detection
Oct 22, 2024



This paper proposes an ultra-low power, mixed-bit-width sparse convolutional neural network (CNN) accelerator to accelerate ventricular arrhythmia (VA) detection. The chip achieves 50% sparsity in a quantized 1D CNN using a sparse processing element (SPE) architecture. Measurement on the prototype chip TSMC 40nm CMOS low-power (LP) process for the VA classification task demonstrates that it consumes 10.60 $\mu$W of power while achieving a performance of 150 GOPS and a diagnostic accuracy of 99.95%. The computation power density is only 0.57 $\mu$W/mm$^2$, which is 14.23X smaller than state-of-the-art works, making it highly suitable for implantable and wearable medical devices.
RIS-based Over-the-air Diffractional Channel Coding
Aug 17, 2024



Reconfigurable Intelligent Surfaces (RIS) are programmable metasurfaces utilizing sub-wavelength meta-atoms and a controller for precise electromagnetic wave manipulation. This work introduces an innovative channel coding scheme, termed RIS-based diffractional channel coding (DCC), which capitalizes on diffraction between two RIS layers for signal-level encoding. Contrary to traditional methods, DCC expands signal dimensions through diffraction, presenting a novel countermeasure to channel effects. This paper focuses on the operational principles of DCC, including encoder and decoder designs, and explores its possibilities to construct block and trellis codes, demonstrating its potential as both an alternative and a supplementary conventional coding scheme. Key advantages of DCC include eliminating extra power requirements for encoding, achieving computation at the speed of light, and enabling adjustable code distance, making it a progressive solution for efficient wireless communication, particularly in systems with large-scale data or massive MIMO.
RIS-Based On-the-Air Semantic Communications -- a Diffractional Deep Neural Network Approach
Dec 01, 2023Semantic communication has gained significant attention recently due to its advantages in achieving higher transmission efficiency by focusing on semantic information instead of bit-level information. However, current AI-based semantic communication methods require digital hardware for implementation. With the rapid advancement on reconfigurable intelligence surfaces (RISs), a new approach called on-the-air diffractional deep neural networks (D$^2$NN) can be utilized to enable semantic communications on the wave domain. This paper proposes a new paradigm of RIS-based on-the-air semantic communications, where the computational process occurs inherently as wireless signals pass through RISs. We present the system model and discuss the data and control flows of this scheme, followed by a performance analysis using image transmission as an example. In comparison to traditional hardware-based approaches, RIS-based semantic communications offer appealing features, such as light-speed computation, low computational power requirements, and the ability to handle multiple tasks simultaneously.
Improving Realistic Worst-Case Performance of NVCiM DNN Accelerators through Training with Right-Censored Gaussian Noise
Jul 29, 2023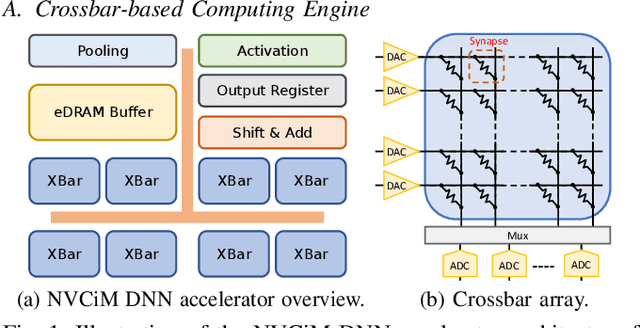
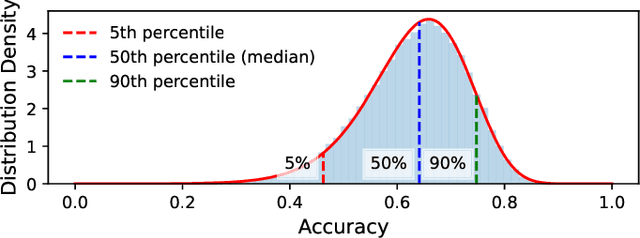
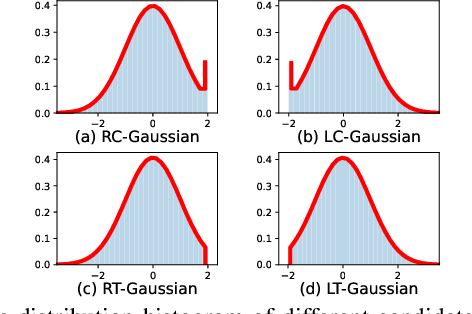
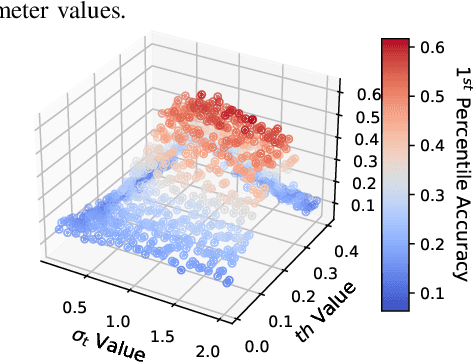
Compute-in-Memory (CiM), built upon non-volatile memory (NVM) devices, is promising for accelerating deep neural networks (DNNs) owing to its in-situ data processing capability and superior energy efficiency. Unfortunately, the well-trained model parameters, after being mapped to NVM devices, can often exhibit large deviations from their intended values due to device variations, resulting in notable performance degradation in these CiM-based DNN accelerators. There exists a long list of solutions to address this issue. However, they mainly focus on improving the mean performance of CiM DNN accelerators. How to guarantee the worst-case performance under the impact of device variations, which is crucial for many safety-critical applications such as self-driving cars, has been far less explored. In this work, we propose to use the k-th percentile performance (KPP) to capture the realistic worst-case performance of DNN models executing on CiM accelerators. Through a formal analysis of the properties of KPP and the noise injection-based DNN training, we demonstrate that injecting a novel right-censored Gaussian noise, as opposed to the conventional Gaussian noise, significantly improves the KPP of DNNs. We further propose an automated method to determine the optimal hyperparameters for injecting this right-censored Gaussian noise during the training process. Our method achieves up to a 26% improvement in KPP compared to the state-of-the-art methods employed to enhance DNN robustness under the impact of device variations.
On the Viability of using LLMs for SW/HW Co-Design: An Example in Designing CiM DNN Accelerators
Jun 12, 2023
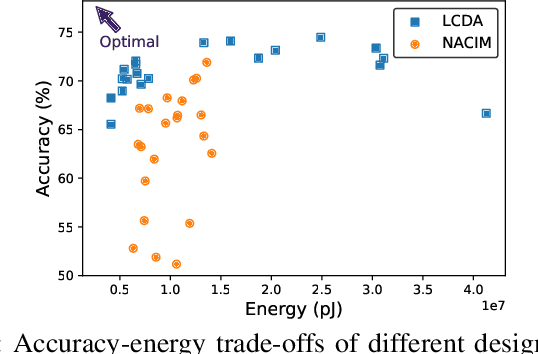


Deep Neural Networks (DNNs) have demonstrated impressive performance across a wide range of tasks. However, deploying DNNs on edge devices poses significant challenges due to stringent power and computational budgets. An effective solution to this issue is software-hardware (SW-HW) co-design, which allows for the tailored creation of DNN models and hardware architectures that optimally utilize available resources. However, SW-HW co-design traditionally suffers from slow optimization speeds because their optimizers do not make use of heuristic knowledge, also known as the ``cold start'' problem. In this study, we present a novel approach that leverages Large Language Models (LLMs) to address this issue. By utilizing the abundant knowledge of pre-trained LLMs in the co-design optimization process, we effectively bypass the cold start problem, substantially accelerating the design process. The proposed method achieves a significant speedup of 25x. This advancement paves the way for the rapid and efficient deployment of DNNs on edge devices.
Negative Feedback Training: A Novel Concept to Improve Robustness of NVCiM DNN Accelerators
May 23, 2023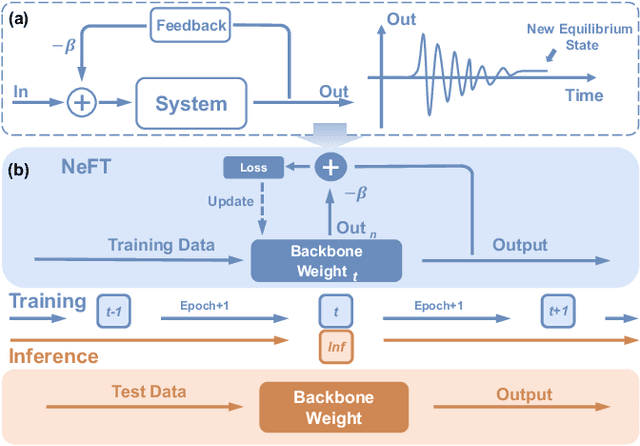

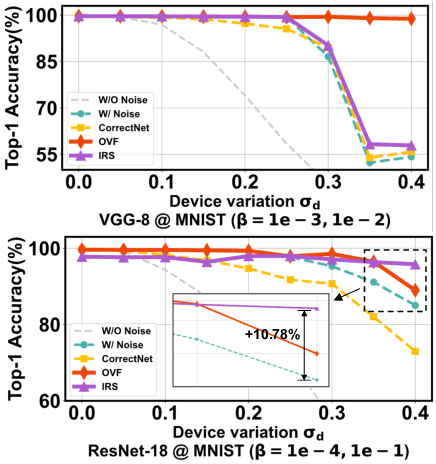
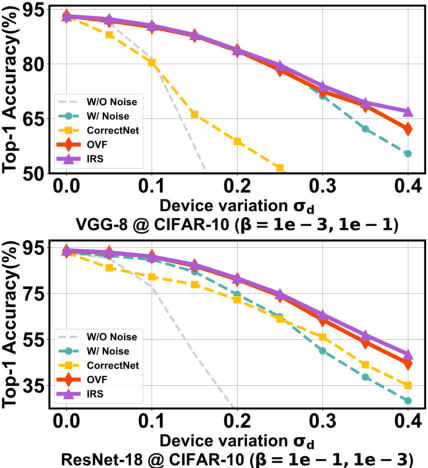
Compute-in-Memory (CiM) utilizing non-volatile memory (NVM) devices presents a highly promising and efficient approach for accelerating deep neural networks (DNNs). By concurrently storing network weights and performing matrix operations within the same crossbar structure, CiM accelerators offer DNN inference acceleration with minimal area requirements and exceptional energy efficiency. However, the stochasticity and intrinsic variations of NVM devices often lead to performance degradation, such as reduced classification accuracy, compared to expected outcomes. Although several methods have been proposed to mitigate device variation and enhance robustness, most of them rely on overall modulation and lack constraints on the training process. Drawing inspiration from the negative feedback mechanism, we introduce a novel training approach that uses a multi-exit mechanism as negative feedback to enhance the performance of DNN models in the presence of device variation. Our negative feedback training method surpasses state-of-the-art techniques by achieving an impressive improvement of up to 12.49% in addressing DNN robustness against device variation.
CryoFormer: Continuous Reconstruction of 3D Structures from Cryo-EM Data using Transformer-based Neural Representations
Mar 28, 2023High-resolution heterogeneous reconstruction of 3D structures of proteins and other biomolecules using cryo-electron microscopy (cryo-EM) is essential for understanding fundamental processes of life. However, it is still challenging to reconstruct the continuous motions of 3D structures from hundreds of thousands of noisy and randomly oriented 2D cryo-EM images. Existing methods based on coordinate-based neural networks show compelling results to model continuous conformations of 3D structures in the Fourier domain, but they suffer from a limited ability to model local flexible regions and lack interpretability. We propose a novel approach, cryoFormer, that utilizes a transformer-based network architecture for continuous heterogeneous cryo-EM reconstruction. We for the first time directly reconstruct continuous conformations of 3D structures using an implicit feature volume in the 3D spatial domain. A novel deformation transformer decoder further improves reconstruction quality and, more importantly, locates and robustly tackles flexible 3D regions caused by conformations. In experiments, our method outperforms current approaches on three public datasets (1 synthetic and 2 experimental) and a new synthetic dataset of PEDV spike protein. The code and new synthetic dataset will be released for better reproducibility of our results. Project page: https://cryoformer.github.io.