 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Paper and Code
Jun 06, 2020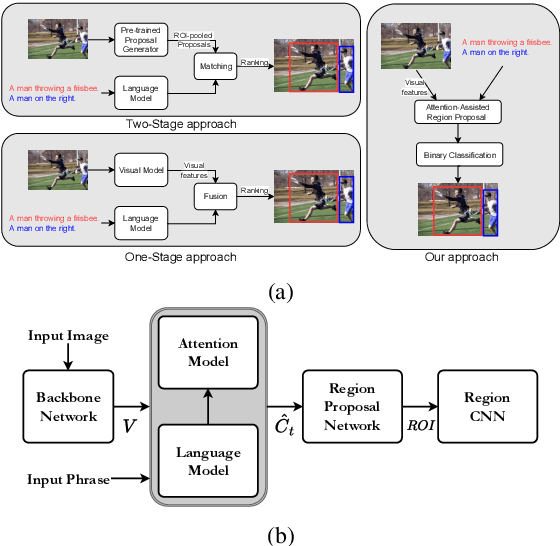
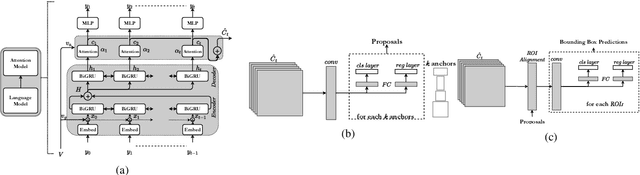


Grounding free-form textual queries necessitates an understanding of these textual phrases and its relation to the visual cues to reliably reason about the described locations. Spatial attention networks are known to learn this relationship and focus its gaze on salient objects in the image. Thus, we propose to utilize spatial attention networks for image-level visual-textual fusion preserving local (word) and global (phrase) information to refine region proposals with an in-network Region Proposal Network (RPN) and detect single or multiple regions for a phrase query. We focus only on the phrase query - ground truth pair (referring expression) for a model independent of the constraints of the datasets i.e. additional attributes, context etc. For such referring expression dataset ReferIt game, our Multi-region Attention-assisted Grounding network (MAGNet) achieves over 12\% improvement over the state-of-the-art. Without the context from image captions and attribute information in Flickr30k Entities, we still achieve competitive results compared to the state-of-the-art.