 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Jun 06, 2020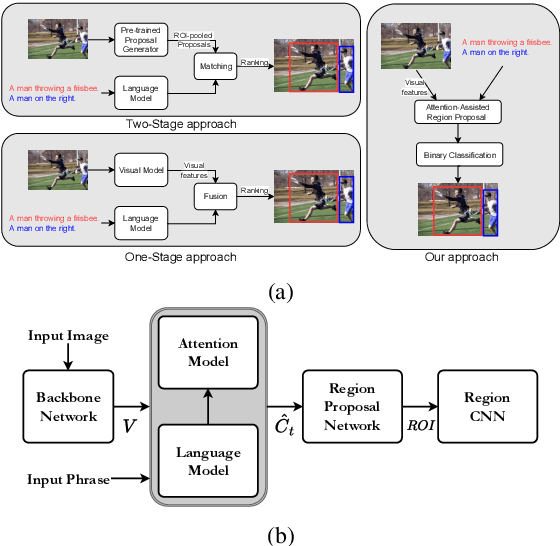
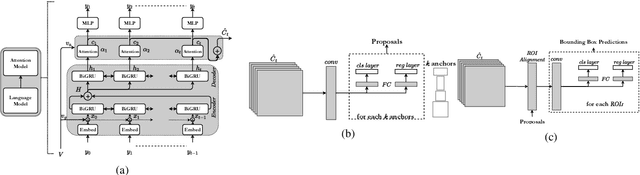


Grounding free-form textual queries necessitates an understanding of these textual phrases and its relation to the visual cues to reliably reason about the described locations. Spatial attention networks are known to learn this relationship and focus its gaze on salient objects in the image. Thus, we propose to utilize spatial attention networks for image-level visual-textual fusion preserving local (word) and global (phrase) information to refine region proposals with an in-network Region Proposal Network (RPN) and detect single or multiple regions for a phrase query. We focus only on the phrase query - ground truth pair (referring expression) for a model independent of the constraints of the datasets i.e. additional attributes, context etc. For such referring expression dataset ReferIt game, our Multi-region Attention-assisted Grounding network (MAGNet) achieves over 12\% improvement over the state-of-the-art. Without the context from image captions and attribute information in Flickr30k Entities, we still achieve competitive results compared to the state-of-the-art.
High-Level Plan for Behavioral Robot Navigation with Natural Language Directions and R-NET
Jan 08, 2020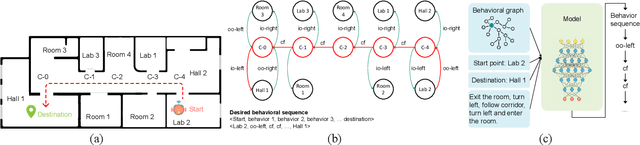

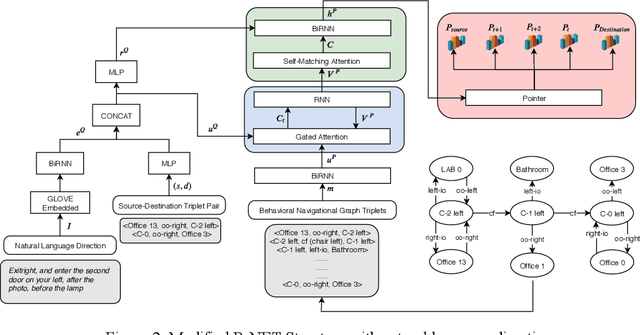
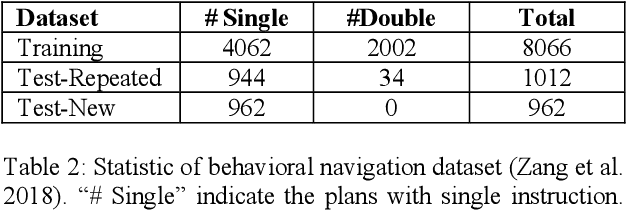
When the navigational environment is known, it can be represented as a graph where landmarks are nodes, the robot behaviors that move from node to node are edges, and the route is a set of behavioral instructions. The route path from source to destination can be viewed as a class of combinatorial optimization problems where the path is a sequential subset from a set of discrete items. The pointer network is an attention-based recurrent network that is suitable for such a task. In this paper, we utilize a modified R-NET with gated attention and self-matching attention translating natural language instructions to a high-level plan for behavioral robot navigation by developing an understanding of the behavioral navigational graph to enable the pointer network to produce a sequence of behaviors representing the path. Tests on the navigation graph dataset show that our model outperforms the state-of-the-art approach for both known and unknown environments.
Learning Topics using Semantic Locality
Apr 11, 2018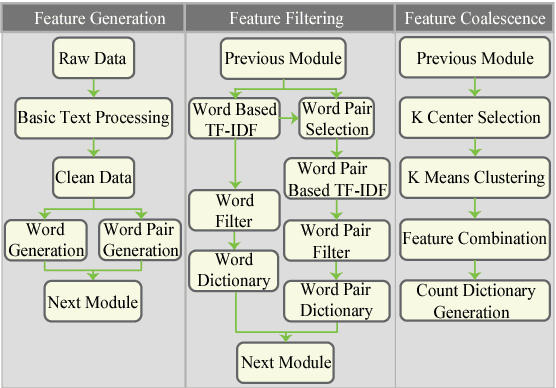
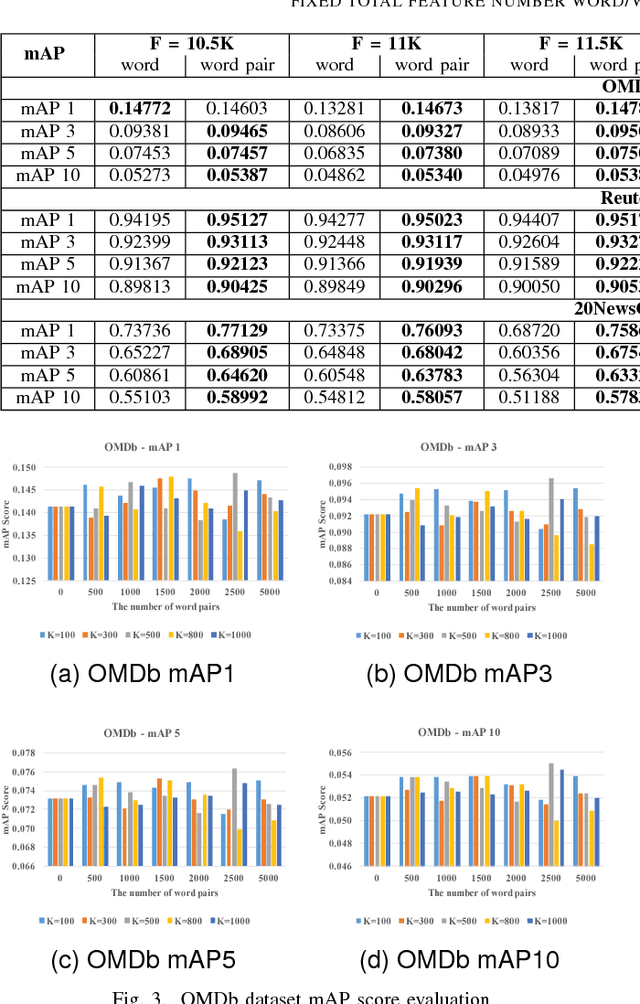
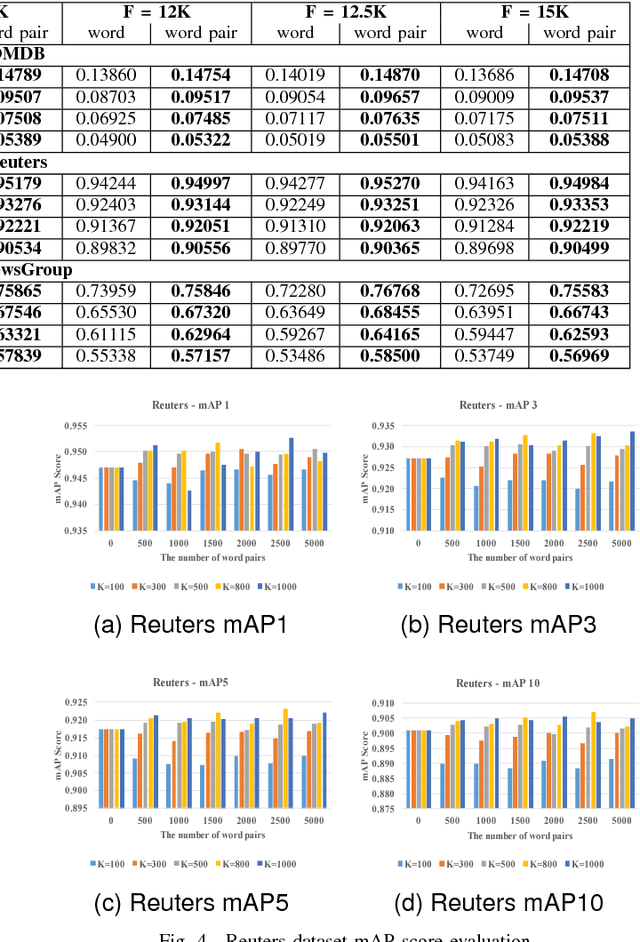
The topic modeling discovers the latent topic probability of the given text documents. To generate the more meaningful topic that better represents the given document, we proposed a new feature extraction technique which can be used in the data preprocessing stage. The method consists of three steps. First, it generates the word/word-pair from every single document. Second, it applies a two-way TF-IDF algorithm to word/word-pair for semantic filtering. Third, it uses the K-means algorithm to merge the word pairs that have the similar semantic meaning. Experiments are carried out on the Open Movie Database (OMDb), Reuters Dataset and 20NewsGroup Dataset. The mean Average Precision score is used as the evaluation metric. Comparing our results with other state-of-the-art topic models, such as Latent Dirichlet allocation and traditional Restricted Boltzmann Machines. Our proposed data preprocessing can improve the generated topic accuracy by up to 12.99\%.