 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecuring the Spike: On the Transferabilty and Security of Spiking Neural Networks to Adversarial Examples
Paper and Code
Sep 07, 2022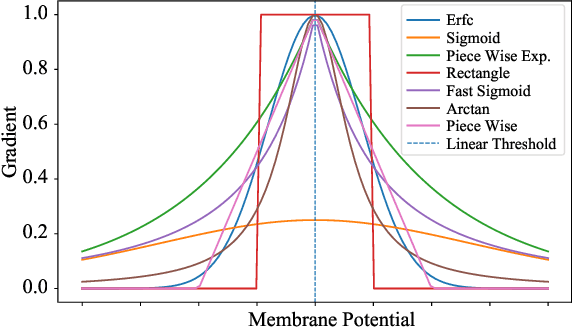
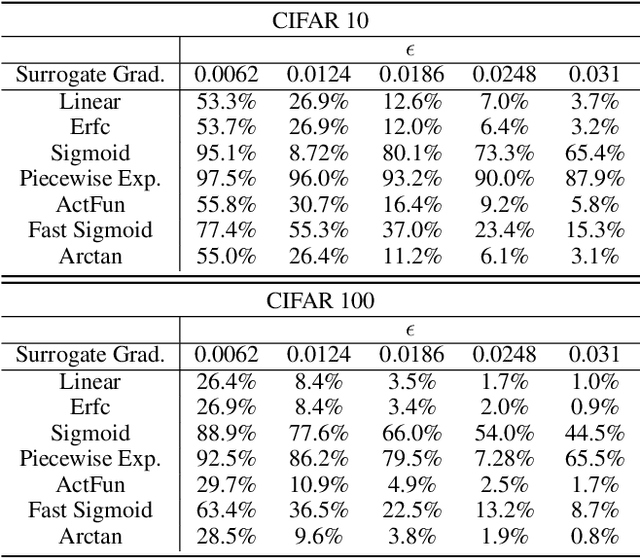
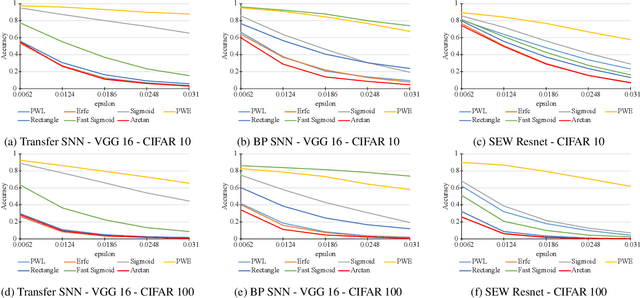
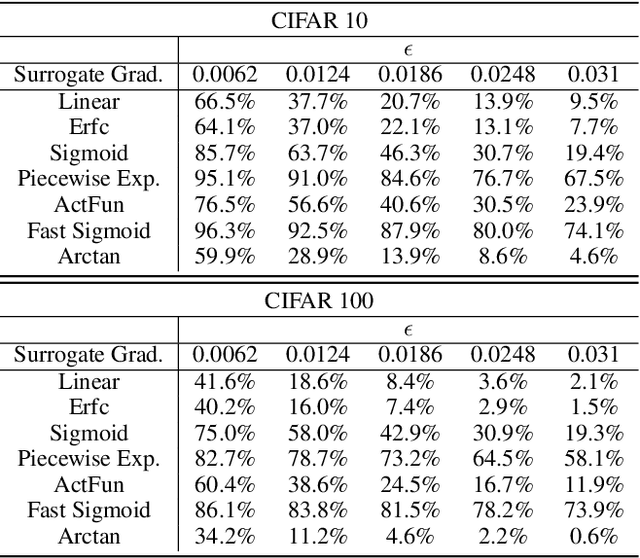
Spiking neural networks (SNNs) have attracted much attention for their high energy efficiency and for recent advances in their classification performance. However, unlike traditional deep learning approaches, the analysis and study of the robustness of SNNs to adversarial examples remains relatively underdeveloped. In this work we advance the field of adversarial machine learning through experimentation and analyses of three important SNN security attributes. First, we show that successful white-box adversarial attacks on SNNs are highly dependent on the underlying surrogate gradient technique. Second, we analyze the transferability of adversarial examples generated by SNNs and other state-of-the-art architectures like Vision Transformers and Big Transfer CNNs. We demonstrate that SNNs are not often deceived by adversarial examples generated by Vision Transformers and certain types of CNNs. Lastly, we develop a novel white-box attack that generates adversarial examples capable of fooling both SNN models and non-SNN models simultaneously. Our experiments and analyses are broad and rigorous covering two datasets (CIFAR-10 and CIFAR-100), five different white-box attacks and twelve different classifier models.