 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBusting the Paper Ballot: Voting Meets Adversarial Machine Learning
Jun 17, 2025
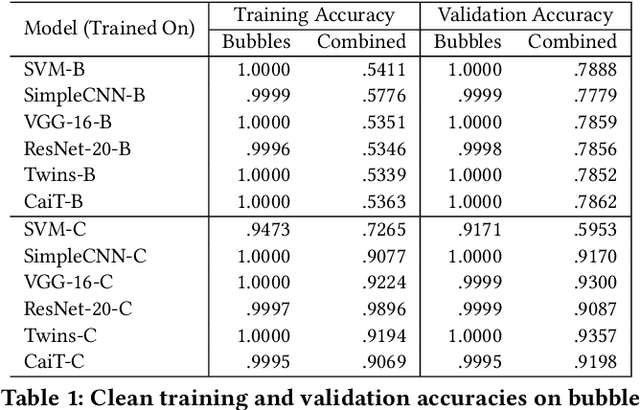

We show the security risk associated with using machine learning classifiers in United States election tabulators. The central classification task in election tabulation is deciding whether a mark does or does not appear on a bubble associated to an alternative in a contest on the ballot. Barretto et al. (E-Vote-ID 2021) reported that convolutional neural networks are a viable option in this field, as they outperform simple feature-based classifiers. Our contributions to election security can be divided into four parts. To demonstrate and analyze the hypothetical vulnerability of machine learning models on election tabulators, we first introduce four new ballot datasets. Second, we train and test a variety of different models on our new datasets. These models include support vector machines, convolutional neural networks (a basic CNN, VGG and ResNet), and vision transformers (Twins and CaiT). Third, using our new datasets and trained models, we demonstrate that traditional white box attacks are ineffective in the voting domain due to gradient masking. Our analyses further reveal that gradient masking is a product of numerical instability. We use a modified difference of logits ratio loss to overcome this issue (Croce and Hein, ICML 2020). Fourth, in the physical world, we conduct attacks with the adversarial examples generated using our new methods. In traditional adversarial machine learning, a high (50% or greater) attack success rate is ideal. However, for certain elections, even a 5% attack success rate can flip the outcome of a race. We show such an impact is possible in the physical domain. We thoroughly discuss attack realism, and the challenges and practicality associated with printing and scanning ballot adversarial examples.
Privacy Attacks Against Biometric Models with Fewer Samples: Incorporating the Output of Multiple Models
Sep 22, 2022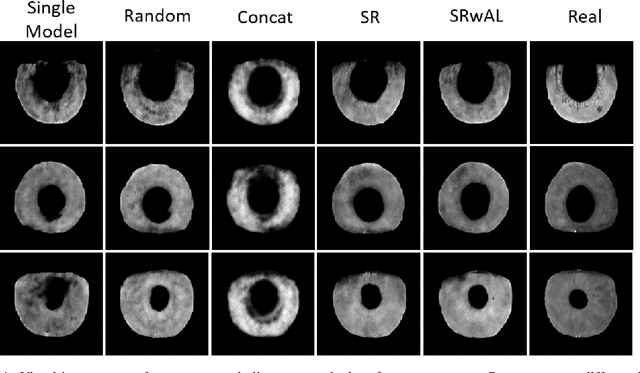
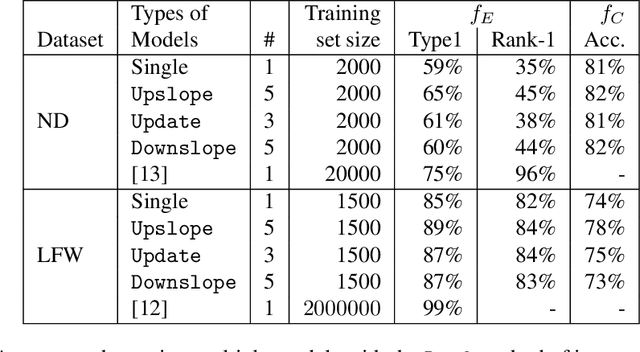
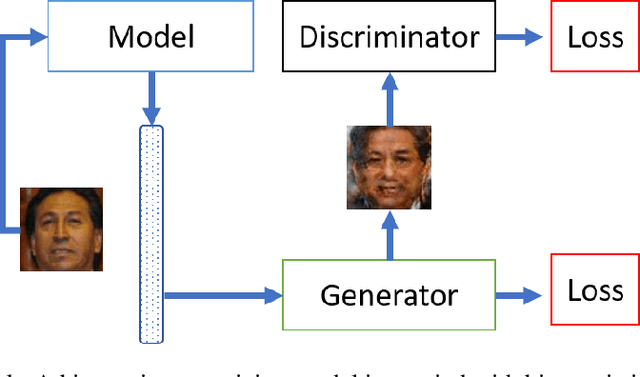

Authentication systems are vulnerable to model inversion attacks where an adversary is able to approximate the inverse of a target machine learning model. Biometric models are a prime candidate for this type of attack. This is because inverting a biometric model allows the attacker to produce a realistic biometric input to spoof biometric authentication systems. One of the main constraints in conducting a successful model inversion attack is the amount of training data required. In this work, we focus on iris and facial biometric systems and propose a new technique that drastically reduces the amount of training data necessary. By leveraging the output of multiple models, we are able to conduct model inversion attacks with 1/10th the training set size of Ahmad and Fuller (IJCB 2020) for iris data and 1/1000th the training set size of Mai et al. (Pattern Analysis and Machine Intelligence 2019) for facial data. We denote our new attack technique as structured random with alignment loss. Our attacks are black-box, requiring no knowledge of the weights of the target neural network, only the dimension, and values of the output vector. To show the versatility of the alignment loss, we apply our attack framework to the task of membership inference (Shokri et al., IEEE S&P 2017) on biometric data. For the iris, membership inference attack against classification networks improves from 52% to 62% accuracy.
Resist : Reconstruction of irises from templates
Jul 31, 2020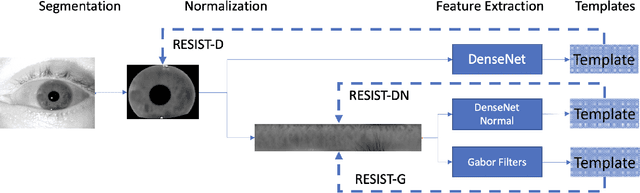

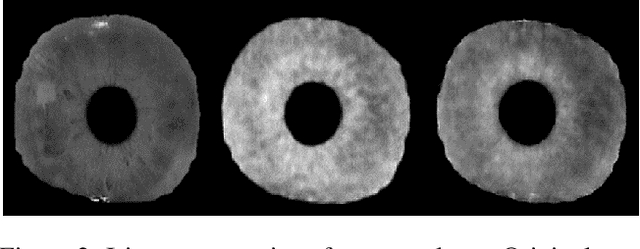
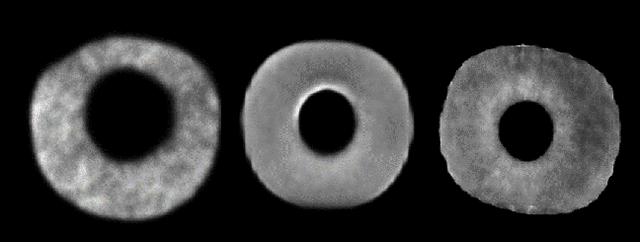
Iris recognition systems transform an iris image into a feature vector. The seminal pipeline segments an image into iris and non-iris pixels, normalizes this region into a fixed-dimension rectangle, and extracts features which are stored and called a template (Daugman, 2009). This template is stored on a system. A future reading of an iris can be transformed and compared against template vectors to determine or verify the identity of an individual. As templates are often stored together, they are a valuable target to an attacker. We show how to invert templates across a variety of iris recognition systems. Our inversion is based on a convolutional neural network architecture we call RESIST (REconStructing IriSes from Templates). We apply RESIST to a traditional Gabor filter pipeline, to a DenseNet (Huang et al., CVPR 2017) feature extractor, and to a DenseNet architecture that works without normalization. Both DenseNet feature extractors are based on the recent ThirdEye recognition system (Ahmad and Fuller, BTAS 2019). When training and testing using the ND-0405 dataset, reconstructed images demonstrate a rank-1 accuracy of 100%, 76%, and 96% respectively for the three pipelines. The core of our approach is similar to an autoencoder. To obtain high accuracy this core is integrated into an adversarial network (Goodfellow et al., NeurIPS, 2014)
ThirdEye: Triplet Based Iris Recognition without Normalization
Jul 13, 2019


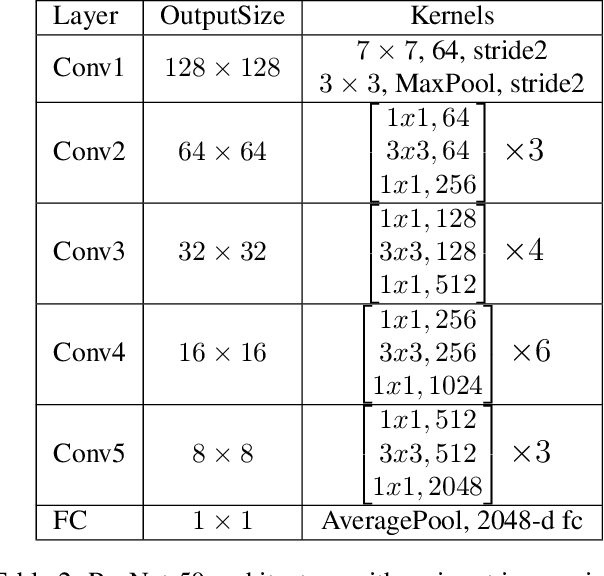
Most iris recognition pipelines involve three stages: segmenting into iris/non-iris pixels, normalization the iris region to a fixed area, and extracting relevant features for comparison. Given recent advances in deep learning it is prudent to ask which stages are required for accurate iris recognition. Lojez et al. (IWBF 2019) recently concluded that the segmentation stage is still crucial for good accuracy.We ask if normalization is beneficial? Towards answering this question, we develop a new iris recognition system called ThirdEye based on triplet convolutional neural networks (Schroff et al., ICCV 2015). ThirdEye directly uses segmented images without normalization. We observe equal error rates of 1.32%, 9.20%, and 0.59% on the ND-0405, UbirisV2, and IITD datasets respectively. For IITD, the most constrained dataset, this improves on the best prior work. However, for ND-0405 and UbirisV2,our equal error rate is slightly worse than prior systems. Our concluding hypothesis is that normalization is more important for less constrained environments.
Unconstrained Iris Segmentation using Convolutional Neural Networks
Dec 19, 2018
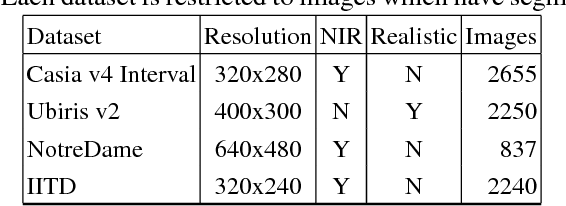


The extraction of consistent and identifiable features from an image of the human iris is known as iris recognition. Identifying which pixels belong to the iris, known as segmentation, is the first stage of iris recognition. Errors in segmentation propagate to later stages. Current segmentation approaches are tuned to specific environments. We propose using a convolution neural network for iris segmentation. Our algorithm is accurate when trained in a single environment and tested in multiple environments. Our network builds on the Mask R-CNN framework (He et al., ICCV 2017). Our approach segments faster than previous approaches including the Mask R-CNN network. Our network is accurate when trained on a single environment and tested with a different sensors (either visible light or near-infrared). Its accuracy degrades when trained with a visible light sensor and tested with a near-infrared sensor (and vice versa). A small amount of retraining of the visible light model (using a few samples from a near-infrared dataset) yields a tuned network accurate in both settings. For training and testing, this work uses the Casia v4 Interval, Notre Dame 0405, Ubiris v2, and IITD datasets.