 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECOMPL: Decompositional Learning with Attention Pooling for Group Activity Recognition from a Single Volleyball Image
Paper and Code
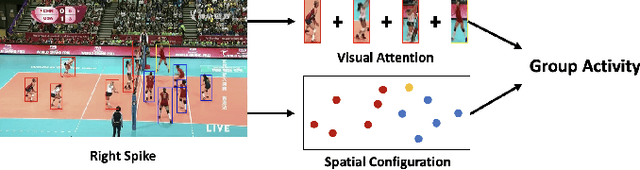
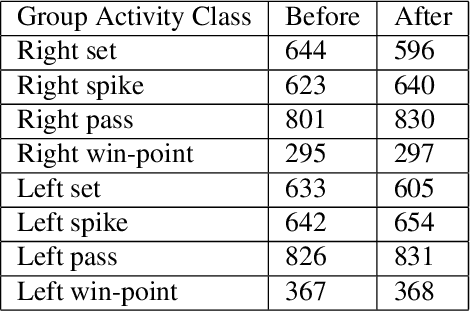
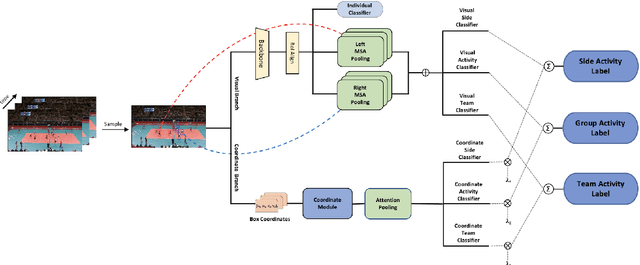
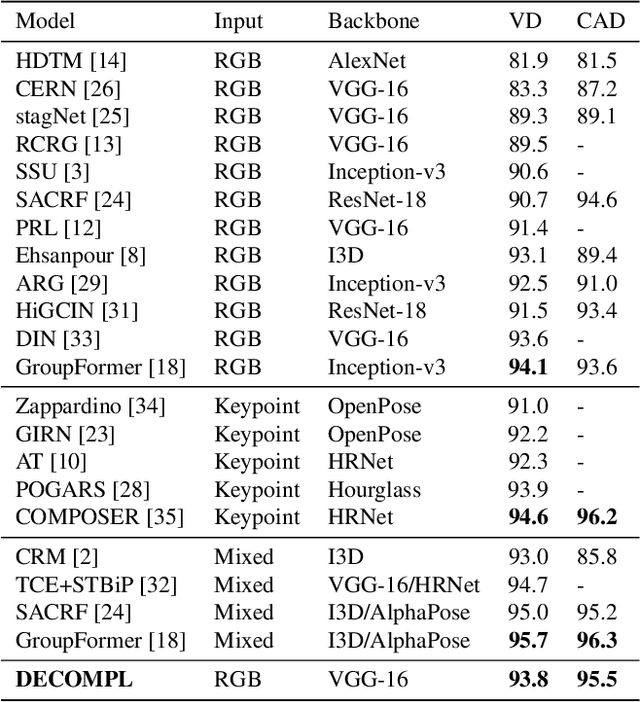
Group Activity Recognition (GAR) aims to detect the activity performed by multiple actors in a scene. Prior works model the spatio-temporal features based on the RGB, optical flow or keypoint data types. However, using both the temporality and these data types altogether increase the computational complexity significantly. Our hypothesis is that by only using the RGB data without temporality, the performance can be maintained with a negligible loss in accuracy. To that end, we propose a novel GAR technique for volleyball videos, DECOMPL, which consists of two complementary branches. In the visual branch, it extracts the features using attention pooling in a selective way. In the coordinate branch, it considers the current configuration of the actors and extracts the spatial information from the box coordinates. Moreover, we analyzed the Volleyball dataset that the recent literature is mostly based on, and realized that its labeling scheme degrades the group concept in the activities to the level of individual actors. We manually reannotated the dataset in a systematic manner for emphasizing the group concept. Experimental results on the Volleyball as well as Collective Activity (from another domain, i.e., not volleyball) datasets demonstrated the effectiveness of the proposed model DECOMPL, which delivered the best/second best GAR performance with the reannotations/original annotations among the comparable state-of-the-art techniques. Our code, results and new annotations will be made available through GitHub after the revision process.