 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Equivalence in Linear Non-Gaussian Latent-Variable Cyclic Causal Models: Characterization and Learning
Mar 05, 2026Causal discovery with latent variables is a fundamental task. Yet most existing methods rely on strong structural assumptions, such as enforcing specific indicator patterns for latents or restricting how they can interact with others. We argue that a core obstacle to a general, structural-assumption-free approach is the lack of an equivalence characterization: without knowing what can be identified, one generally cannot design methods for how to identify it. In this work, we aim to close this gap for linear non-Gaussian models. We establish the graphical criterion for when two graphs with arbitrary latent structure and cycles are distributionally equivalent, that is, they induce the same observed distribution set. Key to our approach is a new tool, edge rank constraints, which fills a missing piece in the toolbox for latent-variable causal discovery in even broader settings. We further provide a procedure to traverse the whole equivalence class and develop an algorithm to recover models from data up to such equivalence. To our knowledge, this is the first equivalence characterization with latent variables in any parametric setting without structural assumptions, and hence the first structural-assumption-free discovery method. Code and an interactive demo are available at https://equiv.cc.
* Appears at ICLR 2026 (oral)
Latent Variable Causal Discovery under Selection Bias
Dec 12, 2025Addressing selection bias in latent variable causal discovery is important yet underexplored, largely due to a lack of suitable statistical tools: While various tools beyond basic conditional independencies have been developed to handle latent variables, none have been adapted for selection bias. We make an attempt by studying rank constraints, which, as a generalization to conditional independence constraints, exploits the ranks of covariance submatrices in linear Gaussian models. We show that although selection can significantly complicate the joint distribution, interestingly, the ranks in the biased covariance matrices still preserve meaningful information about both causal structures and selection mechanisms. We provide a graph-theoretic characterization of such rank constraints. Using this tool, we demonstrate that the one-factor model, a classical latent variable model, can be identified under selection bias. Simulations and real-world experiments confirm the effectiveness of using our rank constraints.
* Appears at ICML 2025
Identification of Causal Direction under an Arbitrary Number of Latent Confounders
Oct 26, 2025Recovering causal structure in the presence of latent variables is an important but challenging task. While many methods have been proposed to handle it, most of them require strict and/or untestable assumptions on the causal structure. In real-world scenarios, observed variables may be affected by multiple latent variables simultaneously, which, generally speaking, cannot be handled by these methods. In this paper, we consider the linear, non-Gaussian case, and make use of the joint higher-order cumulant matrix of the observed variables constructed in a specific way. We show that, surprisingly, causal asymmetry between two observed variables can be directly seen from the rank deficiency properties of such higher-order cumulant matrices, even in the presence of an arbitrary number of latent confounders. Identifiability results are established, and the corresponding identification methods do not even involve iterative procedures. Experimental results demonstrate the effectiveness and asymptotic correctness of our proposed method.
Score-based Greedy Search for Structure Identification of Partially Observed Linear Causal Models
Oct 05, 2025Identifying the structure of a partially observed causal system is essential to various scientific fields. Recent advances have focused on constraint-based causal discovery to solve this problem, and yet in practice these methods often face challenges related to multiple testing and error propagation. These issues could be mitigated by a score-based method and thus it has raised great attention whether there exists a score-based greedy search method that can handle the partially observed scenario. In this work, we propose the first score-based greedy search method for the identification of structure involving latent variables with identifiability guarantees. Specifically, we propose Generalized N Factor Model and establish the global consistency: the true structure including latent variables can be identified up to the Markov equivalence class by using score. We then design Latent variable Greedy Equivalence Search (LGES), a greedy search algorithm for this class of model with well-defined operators, which search very efficiently over the graph space to find the optimal structure. Our experiments on both synthetic and real-life data validate the effectiveness of our method (code will be publicly available).
Type Information-Assisted Self-Supervised Knowledge Graph Denoising
Mar 13, 2025Knowledge graphs serve as critical resources supporting intelligent systems, but they can be noisy due to imperfect automatic generation processes. Existing approaches to noise detection often rely on external facts, logical rule constraints, or structural embeddings. These methods are often challenged by imperfect entity alignment, flexible knowledge graph construction, and overfitting on structures. In this paper, we propose to exploit the consistency between entity and relation type information for noise detection, resulting a novel self-supervised knowledge graph denoising method that avoids those problems. We formalize type inconsistency noise as triples that deviate from the majority with respect to type-dependent reasoning along the topological structure. Specifically, we first extract a compact representation of a given knowledge graph via an encoder that models the type dependencies of triples. Then, the decoder reconstructs the original input knowledge graph based on the compact representation. It is worth noting that, our proposal has the potential to address the problems of knowledge graph compression and completion, although this is not our focus. For the specific task of noise detection, the discrepancy between the reconstruction results and the input knowledge graph provides an opportunity for denoising, which is facilitated by the type consistency embedded in our method. Experimental validation demonstrates the effectiveness of our approach in detecting potential noise in real-world data.
When Selection Meets Intervention: Additional Complexities in Causal Discovery
Mar 10, 2025We address the common yet often-overlooked selection bias in interventional studies, where subjects are selectively enrolled into experiments. For instance, participants in a drug trial are usually patients of the relevant disease; A/B tests on mobile applications target existing users only, and gene perturbation studies typically focus on specific cell types, such as cancer cells. Ignoring this bias leads to incorrect causal discovery results. Even when recognized, the existing paradigm for interventional causal discovery still fails to address it. This is because subtle differences in when and where interventions happen can lead to significantly different statistical patterns. We capture this dynamic by introducing a graphical model that explicitly accounts for both the observed world (where interventions are applied) and the counterfactual world (where selection occurs while interventions have not been applied). We characterize the Markov property of the model, and propose a provably sound algorithm to identify causal relations as well as selection mechanisms up to the equivalence class, from data with soft interventions and unknown targets. Through synthetic and real-world experiments, we demonstrate that our algorithm effectively identifies true causal relations despite the presence of selection bias.
* Appears at ICLR 2025 (oral)
Permutation-Based Rank Test in the Presence of Discretization and Application in Causal Discovery with Mixed Data
Jan 31, 2025



Recent advances have shown that statistical tests for the rank of cross-covariance matrices play an important role in causal discovery. These rank tests include partial correlation tests as special cases and provide further graphical information about latent variables. Existing rank tests typically assume that all the continuous variables can be perfectly measured, and yet, in practice many variables can only be measured after discretization. For example, in psychometric studies, the continuous level of certain personality dimensions of a person can only be measured after being discretized into order-preserving options such as disagree, neutral, and agree. Motivated by this, we propose Mixed data Permutation-based Rank Test (MPRT), which properly controls the statistical errors even when some or all variables are discretized. Theoretically, we establish the exchangeability and estimate the asymptotic null distribution by permutations; as a consequence, MPRT can effectively control the Type I error in the presence of discretization while previous methods cannot. Empirically, our method is validated by extensive experiments on synthetic data and real-world data to demonstrate its effectiveness as well as applicability in causal discovery.
Gene Regulatory Network Inference in the Presence of Dropouts: a Causal View
Mar 21, 2024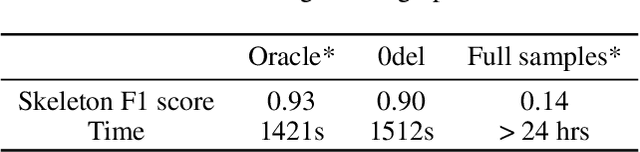
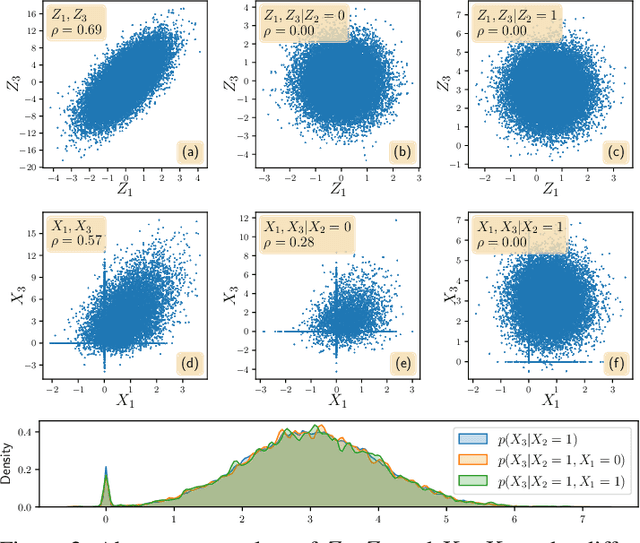
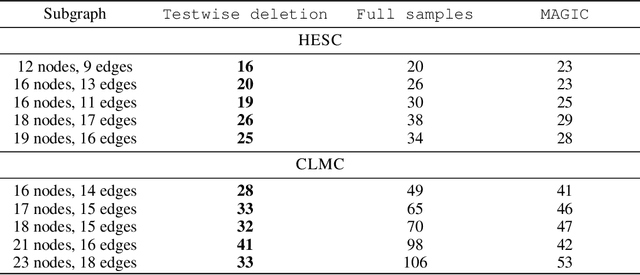
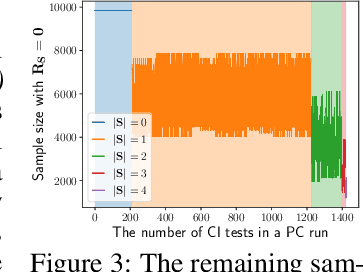
Gene regulatory network inference (GRNI) is a challenging problem, particularly owing to the presence of zeros in single-cell RNA sequencing data: some are biological zeros representing no gene expression, while some others are technical zeros arising from the sequencing procedure (aka dropouts), which may bias GRNI by distorting the joint distribution of the measured gene expressions. Existing approaches typically handle dropout error via imputation, which may introduce spurious relations as the true joint distribution is generally unidentifiable. To tackle this issue, we introduce a causal graphical model to characterize the dropout mechanism, namely, Causal Dropout Model. We provide a simple yet effective theoretical result: interestingly, the conditional independence (CI) relations in the data with dropouts, after deleting the samples with zero values (regardless if technical or not) for the conditioned variables, are asymptotically identical to the CI relations in the original data without dropouts. This particular test-wise deletion procedure, in which we perform CI tests on the samples without zeros for the conditioned variables, can be seamlessly integrated with existing structure learning approaches including constraint-based and greedy score-based methods, thus giving rise to a principled framework for GRNI in the presence of dropouts. We further show that the causal dropout model can be validated from data, and many existing statistical models to handle dropouts fit into our model as specific parametric instances. Empirical evaluation on synthetic, curated, and real-world experimental transcriptomic data comprehensively demonstrate the efficacy of our method.
Local Causal Discovery with Linear non-Gaussian Cyclic Models
Mar 21, 2024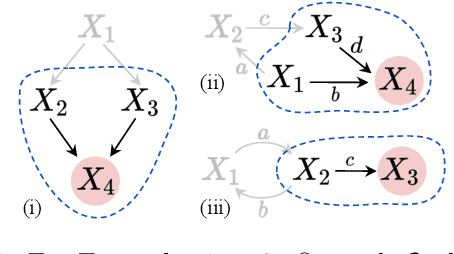
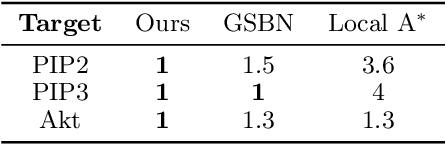

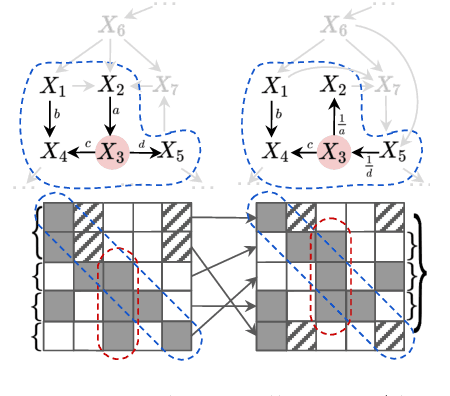
Local causal discovery is of great practical significance, as there are often situations where the discovery of the global causal structure is unnecessary, and the interest lies solely on a single target variable. Most existing local methods utilize conditional independence relations, providing only a partially directed graph, and assume acyclicity for the ground-truth structure, even though real-world scenarios often involve cycles like feedback mechanisms. In this work, we present a general, unified local causal discovery method with linear non-Gaussian models, whether they are cyclic or acyclic. We extend the application of independent component analysis from the global context to independent subspace analysis, enabling the exact identification of the equivalent local directed structures and causal strengths from the Markov blanket of the target variable. We also propose an alternative regression-based method in the particular acyclic scenarios. Our identifiability results are empirically validated using both synthetic and real-world datasets.
On the Three Demons in Causality in Finance: Time Resolution, Nonstationarity, and Latent Factors
Jan 12, 2024



Financial data is generally time series in essence and thus suffers from three fundamental issues: the mismatch in time resolution, the time-varying property of the distribution - nonstationarity, and causal factors that are important but unknown/unobserved. In this paper, we follow a causal perspective to systematically look into these three demons in finance. Specifically, we reexamine these issues in the context of causality, which gives rise to a novel and inspiring understanding of how the issues can be addressed. Following this perspective, we provide systematic solutions to these problems, which hopefully would serve as a foundation for future research in the area.