 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirage2Matter: A Physically Grounded Gaussian World Model from Video
Jan 24, 2026The scalability of embodied intelligence is fundamentally constrained by the scarcity of real-world interaction data. While simulation platforms provide a promising alternative, existing approaches often suffer from a substantial visual and physical gap to real environments and rely on expensive sensors, precise robot calibration, or depth measurements, limiting their practicality at scale. We present Simulate Anything, a graphics-driven world modeling and simulation framework that enables efficient generation of high-fidelity embodied training data using only multi-view environment videos and off-the-shelf assets. Our approach reconstructs real-world environments into a photorealistic scene representation using 3D Gaussian Splatting (3DGS), seamlessly capturing fine-grained geometry and appearance from video. We then leverage generative models to recover a physically realistic representation and integrate it into a simulation environment via a precision calibration target, enabling accurate scale alignment between the reconstructed scene and the real world. Together, these components provide a unified, editable, and physically grounded world model. Vision Language Action (VLA) models trained on our simulated data achieve strong zero-shot performance on downstream tasks, matching or even surpassing results obtained with real-world data, highlighting the potential of reconstruction-driven world modeling for scalable and practical embodied intelligence training.
Adapting Vision-Language Models to Open Classes via Test-Time Prompt Tuning
Aug 29, 2024



Adapting pre-trained models to open classes is a challenging problem in machine learning. Vision-language models fully explore the knowledge of text modality, demonstrating strong zero-shot recognition performance, which is naturally suited for various open-set problems. More recently, some research focuses on fine-tuning such models to downstream tasks. Prompt tuning methods achieved huge improvements by learning context vectors on few-shot data. However, through the evaluation under open-set adaptation setting with the test data including new classes, we find that there exists a dilemma that learned prompts have worse generalization abilities than hand-crafted prompts. In this paper, we consider combining the advantages of both and come up with a test-time prompt tuning approach, which leverages the maximum concept matching (MCM) scores as dynamic weights to generate an input-conditioned prompt for each image during test. Through extensive experiments on 11 different datasets, we show that our proposed method outperforms all comparison methods on average considering both base and new classes. The code is available at https://github.com/gaozhengqing/TTPT
Unified Entropy Optimization for Open-Set Test-Time Adaptation
Apr 09, 2024Test-time adaptation (TTA) aims at adapting a model pre-trained on the labeled source domain to the unlabeled target domain. Existing methods usually focus on improving TTA performance under covariate shifts, while neglecting semantic shifts. In this paper, we delve into a realistic open-set TTA setting where the target domain may contain samples from unknown classes. Many state-of-the-art closed-set TTA methods perform poorly when applied to open-set scenarios, which can be attributed to the inaccurate estimation of data distribution and model confidence. To address these issues, we propose a simple but effective framework called unified entropy optimization (UniEnt), which is capable of simultaneously adapting to covariate-shifted in-distribution (csID) data and detecting covariate-shifted out-of-distribution (csOOD) data. Specifically, UniEnt first mines pseudo-csID and pseudo-csOOD samples from test data, followed by entropy minimization on the pseudo-csID data and entropy maximization on the pseudo-csOOD data. Furthermore, we introduce UniEnt+ to alleviate the noise caused by hard data partition leveraging sample-level confidence. Extensive experiments on CIFAR benchmarks and Tiny-ImageNet-C show the superiority of our framework. The code is available at https://github.com/gaozhengqing/UniEnt
Local Causal Discovery with Linear non-Gaussian Cyclic Models
Mar 21, 2024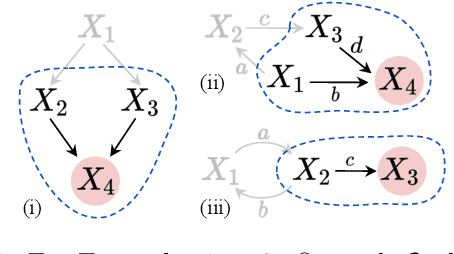
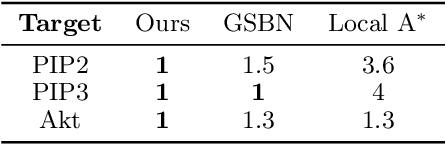

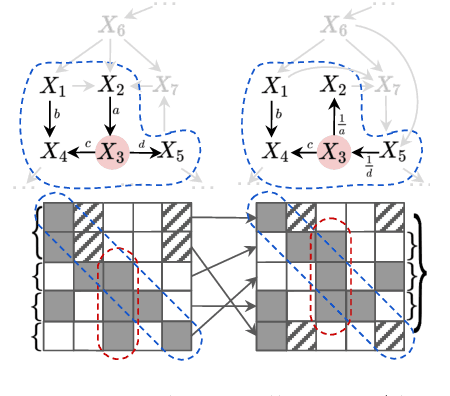
Local causal discovery is of great practical significance, as there are often situations where the discovery of the global causal structure is unnecessary, and the interest lies solely on a single target variable. Most existing local methods utilize conditional independence relations, providing only a partially directed graph, and assume acyclicity for the ground-truth structure, even though real-world scenarios often involve cycles like feedback mechanisms. In this work, we present a general, unified local causal discovery method with linear non-Gaussian models, whether they are cyclic or acyclic. We extend the application of independent component analysis from the global context to independent subspace analysis, enabling the exact identification of the equivalent local directed structures and causal strengths from the Markov blanket of the target variable. We also propose an alternative regression-based method in the particular acyclic scenarios. Our identifiability results are empirically validated using both synthetic and real-world datasets.