 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Transfer from Inverse Reinforcement Learning: A Coupled Minimax Approach
May 27, 2026We study the transfer of rewards learned using inverse reinforcement learning from expert demonstrations in one environment to reinforcement learning in a new, different environment. This arises naturally when demonstrations are collected in a controlled environment. We formulate the problem as a joint system of Bellman equations across the source and target environments and develop minimax estimators for the target soft-$q$-function. Whereas a sequential solution approach first estimates the source reward and then plugs it into the target control problem, a coupled approach solves the source and target system of equations jointly. We show that, in contrast to the sequential approach, the coupled approach removes the first-order influence of source Bellman residual error. We characterize the local behavior of each approach, develop finite-sample soft-$q$-function error bounds, and prove regret guarantees for the resulting soft-control policy. An empirical investigation using a sepsis simulator validates the theoretical comparison.
Permutation-Based Rank Test in the Presence of Discretization and Application in Causal Discovery with Mixed Data
Jan 31, 2025



Recent advances have shown that statistical tests for the rank of cross-covariance matrices play an important role in causal discovery. These rank tests include partial correlation tests as special cases and provide further graphical information about latent variables. Existing rank tests typically assume that all the continuous variables can be perfectly measured, and yet, in practice many variables can only be measured after discretization. For example, in psychometric studies, the continuous level of certain personality dimensions of a person can only be measured after being discretized into order-preserving options such as disagree, neutral, and agree. Motivated by this, we propose Mixed data Permutation-based Rank Test (MPRT), which properly controls the statistical errors even when some or all variables are discretized. Theoretically, we establish the exchangeability and estimate the asymptotic null distribution by permutations; as a consequence, MPRT can effectively control the Type I error in the presence of discretization while previous methods cannot. Empirically, our method is validated by extensive experiments on synthetic data and real-world data to demonstrate its effectiveness as well as applicability in causal discovery.
Composite Active Learning: Towards Multi-Domain Active Learning with Theoretical Guarantees
Feb 03, 2024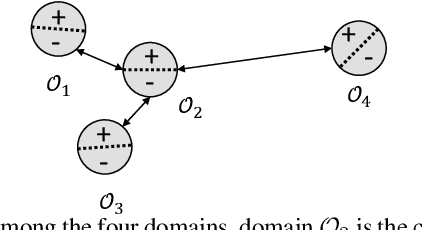

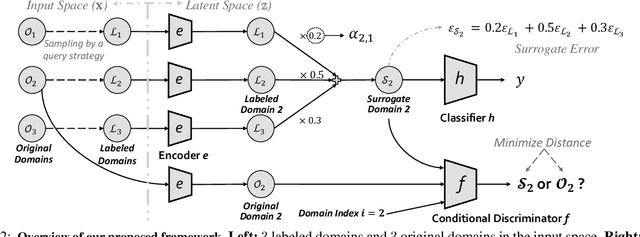

Active learning (AL) aims to improve model performance within a fixed labeling budget by choosing the most informative data points to label. Existing AL focuses on the single-domain setting, where all data come from the same domain (e.g., the same dataset). However, many real-world tasks often involve multiple domains. For example, in visual recognition, it is often desirable to train an image classifier that works across different environments (e.g., different backgrounds), where images from each environment constitute one domain. Such a multi-domain AL setting is challenging for prior methods because they (1) ignore the similarity among different domains when assigning labeling budget and (2) fail to handle distribution shift of data across different domains. In this paper, we propose the first general method, dubbed composite active learning (CAL), for multi-domain AL. Our approach explicitly considers the domain-level and instance-level information in the problem; CAL first assigns domain-level budgets according to domain-level importance, which is estimated by optimizing an upper error bound that we develop; with the domain-level budgets, CAL then leverages a certain instance-level query strategy to select samples to label from each domain. Our theoretical analysis shows that our method achieves a better error bound compared to current AL methods. Our empirical results demonstrate that our approach significantly outperforms the state-of-the-art AL methods on both synthetic and real-world multi-domain datasets. Code is available at https://github.com/Wang-ML-Lab/multi-domain-active-learning.
Natural Counterfactuals With Necessary Backtracking
Feb 02, 2024



Counterfactual reasoning is pivotal in human cognition and especially important for providing explanations and making decisions. While Judea Pearl's influential approach is theoretically elegant, its generation of a counterfactual scenario often requires interventions that are too detached from the real scenarios to be feasible. In response, we propose a framework of natural counterfactuals and a method for generating counterfactuals that are natural with respect to the actual world's data distribution. Our methodology refines counterfactual reasoning, allowing changes in causally preceding variables to minimize deviations from realistic scenarios. To generate natural counterfactuals, we introduce an innovative optimization framework that permits but controls the extent of backtracking with a naturalness criterion. Empirical experiments indicate the effectiveness of our method.
Taxonomy-Structured Domain Adaptation
Jul 01, 2023



Domain adaptation aims to mitigate distribution shifts among different domains. However, traditional formulations are mostly limited to categorical domains, greatly simplifying nuanced domain relationships in the real world. In this work, we tackle a generalization with taxonomy-structured domains, which formalizes domains with nested, hierarchical similarity structures such as animal species and product catalogs. We build on the classic adversarial framework and introduce a novel taxonomist, which competes with the adversarial discriminator to preserve the taxonomy information. The equilibrium recovers the classic adversarial domain adaptation's solution if given a non-informative domain taxonomy (e.g., a flat taxonomy where all leaf nodes connect to the root node) while yielding non-trivial results with other taxonomies. Empirically, our method achieves state-of-the-art performance on both synthetic and real-world datasets with successful adaptation. Code is available at https://github.com/Wang-ML-Lab/TSDA.
Domain-Indexing Variational Bayes: Interpretable Domain Index for Domain Adaptation
Mar 02, 2023Previous studies have shown that leveraging domain index can significantly boost domain adaptation performance (arXiv:2007.01807, arXiv:2202.03628). However, such domain indices are not always available. To address this challenge, we first provide a formal definition of domain index from the probabilistic perspective, and then propose an adversarial variational Bayesian framework that infers domain indices from multi-domain data, thereby providing additional insight on domain relations and improving domain adaptation performance. Our theoretical analysis shows that our adversarial variational Bayesian framework finds the optimal domain index at equilibrium. Empirical results on both synthetic and real data verify that our model can produce interpretable domain indices which enable us to achieve superior performance compared to state-of-the-art domain adaptation methods. Code is available at https://github.com/Wang-ML-Lab/VDI.
DyLex: Incorporating Dynamic Lexicons into BERT for Sequence Labeling
Sep 22, 2021


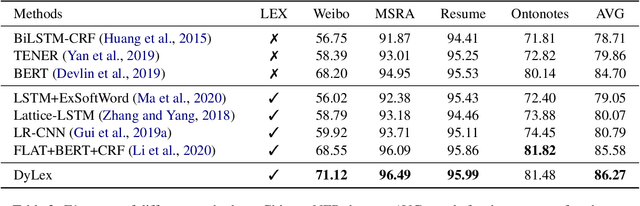
Incorporating lexical knowledge into deep learning models has been proved to be very effective for sequence labeling tasks. However, previous works commonly have difficulty dealing with large-scale dynamic lexicons which often cause excessive matching noise and problems of frequent updates. In this paper, we propose DyLex, a plug-in lexicon incorporation approach for BERT based sequence labeling tasks. Instead of leveraging embeddings of words in the lexicon as in conventional methods, we adopt word-agnostic tag embeddings to avoid re-training the representation while updating the lexicon. Moreover, we employ an effective supervised lexical knowledge denoising method to smooth out matching noise. Finally, we introduce a col-wise attention based knowledge fusion mechanism to guarantee the pluggability of the proposed framework. Experiments on ten datasets of three tasks show that the proposed framework achieves new SOTA, even with very large scale lexicons.
DSRGAN: Explicitly Learning Disentangled Representation of Underlying Structure and Rendering for Image Generation without Tuple Supervision
Sep 30, 2019
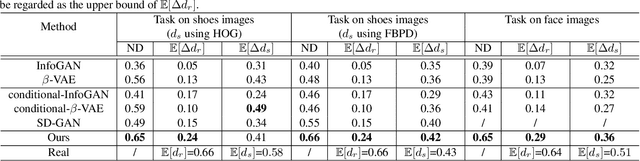
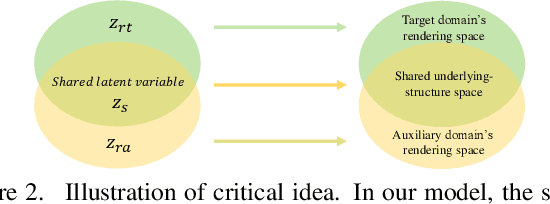
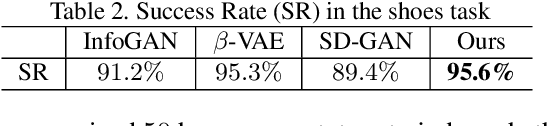
We focus on explicitly learning disentangled representation for natural image generation, where the underlying spatial structure and the rendering on the structure can be independently controlled respectively, yet using no tuple supervision. The setting is significant since tuple supervision is costly and sometimes even unavailable. However, the task is highly unconstrained and thus ill-posed. To address this problem, we propose to introduce an auxiliary domain which shares a common underlying-structure space with the target domain, and we make a partially shared latent space assumption. The key idea is to encourage the partially shared latent variable to represent the similar underlying spatial structures in both domains, while the two domain-specific latent variables will be unavoidably arranged to present renderings of two domains respectively. This is achieved by designing two parallel generative networks with a common Progressive Rendering Architecture (PRA), which constrains both generative networks' behaviors to model shared underlying structure and to model spatially dependent relation between rendering and underlying structure. Thus, we propose DSRGAN (GANs for Disentangling Underlying Structure and Rendering) to instantiate our method. We also propose a quantitative criterion (the Normalized Disentanglability) to quantify disentanglability. Comparison to the state-of-the-art methods shows that DSRGAN can significantly outperform them in disentanglability.
MIXGAN: Learning Concepts from Different Domains for Mixture Generation
Jul 04, 2018

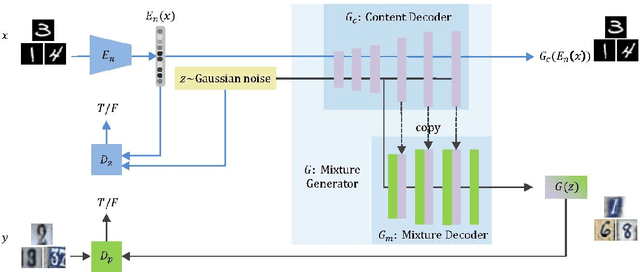

In this work, we present an interesting attempt on mixture generation: absorbing different image concepts (e.g., content and style) from different domains and thus generating a new domain with learned concepts. In particular, we propose a mixture generative adversarial network (MIXGAN). MIXGAN learns concepts of content and style from two domains respectively, and thus can join them for mixture generation in a new domain, i.e., generating images with content from one domain and style from another. MIXGAN overcomes the limitation of current GAN-based models which either generate new images in the same domain as they observed in training stage, or require off-the-shelf content templates for transferring or translation. Extensive experimental results demonstrate the effectiveness of MIXGAN as compared to related state-of-the-art GAN-based models.