 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonomy-Structured Domain Adaptation
Jul 01, 2023



Domain adaptation aims to mitigate distribution shifts among different domains. However, traditional formulations are mostly limited to categorical domains, greatly simplifying nuanced domain relationships in the real world. In this work, we tackle a generalization with taxonomy-structured domains, which formalizes domains with nested, hierarchical similarity structures such as animal species and product catalogs. We build on the classic adversarial framework and introduce a novel taxonomist, which competes with the adversarial discriminator to preserve the taxonomy information. The equilibrium recovers the classic adversarial domain adaptation's solution if given a non-informative domain taxonomy (e.g., a flat taxonomy where all leaf nodes connect to the root node) while yielding non-trivial results with other taxonomies. Empirically, our method achieves state-of-the-art performance on both synthetic and real-world datasets with successful adaptation. Code is available at https://github.com/Wang-ML-Lab/TSDA.
Graph-Relational Domain Adaptation
Feb 08, 2022
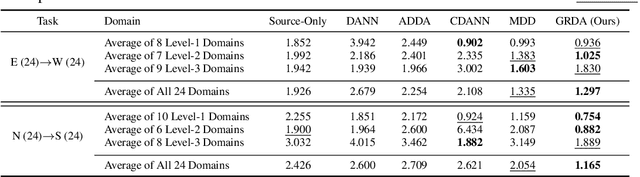
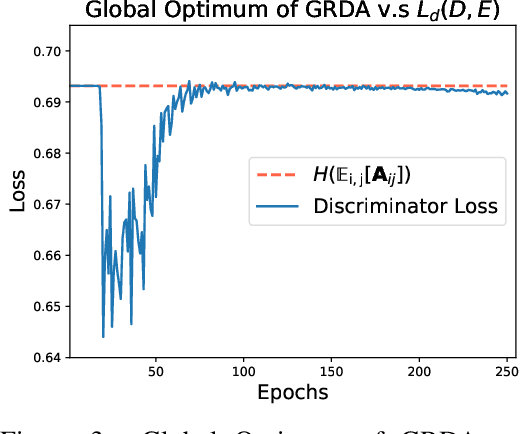
Existing domain adaptation methods tend to treat every domain equally and align them all perfectly. Such uniform alignment ignores topological structures among different domains; therefore it may be beneficial for nearby domains, but not necessarily for distant domains. In this work, we relax such uniform alignment by using a domain graph to encode domain adjacency, e.g., a graph of states in the US with each state as a domain and each edge indicating adjacency, thereby allowing domains to align flexibly based on the graph structure. We generalize the existing adversarial learning framework with a novel graph discriminator using encoding-conditioned graph embeddings. Theoretical analysis shows that at equilibrium, our method recovers classic domain adaptation when the graph is a clique, and achieves non-trivial alignment for other types of graphs. Empirical results show that our approach successfully generalizes uniform alignment, naturally incorporates domain information represented by graphs, and improves upon existing domain adaptation methods on both synthetic and real-world datasets. Code will soon be available at https://github.com/Wang-ML-Lab/GRDA.
Locally Constant Networks
Sep 30, 2019
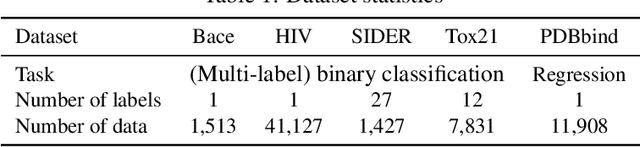
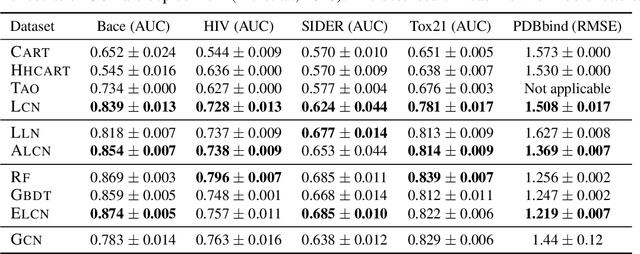

We show how neural models can be used to realize piece-wise constant functions such as decision trees. Our approach builds on ReLU networks that are piece-wise linear and hence their associated gradients with respect to the inputs are locally constant. We formally establish the equivalence between the classes of locally constant networks and decision trees. Moreover, we highlight several advantageous properties of locally constant networks, including how they realize decision trees with parameter sharing across branching / leaves. Indeed, only $M$ neurons suffice to implicitly model an oblique decision tree with $2^M$ leaf nodes. The neural representation also enables us to adopt many tools developed for deep networks (e.g., DropConnect (Wan et al. 2013)) while implicitly training decision trees. We demonstrate that our method outperforms alternative techniques for training oblique decision trees in the context of molecular property classification and regression tasks.
Towards Robust, Locally Linear Deep Networks
Jul 07, 2019

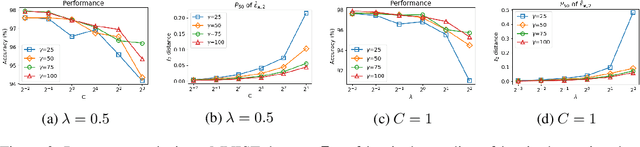

Deep networks realize complex mappings that are often understood by their locally linear behavior at or around points of interest. For example, we use the derivative of the mapping with respect to its inputs for sensitivity analysis, or to explain (obtain coordinate relevance for) a prediction. One key challenge is that such derivatives are themselves inherently unstable. In this paper, we propose a new learning problem to encourage deep networks to have stable derivatives over larger regions. While the problem is challenging in general, we focus on networks with piecewise linear activation functions. Our algorithm consists of an inference step that identifies a region around a point where linear approximation is provably stable, and an optimization step to expand such regions. We propose a novel relaxation to scale the algorithm to realistic models. We illustrate our method with residual and recurrent networks on image and sequence datasets.
A Stratified Approach to Robustness for Randomly Smoothed Classifiers
Jun 12, 2019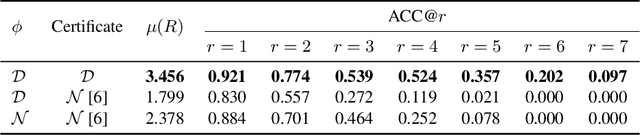
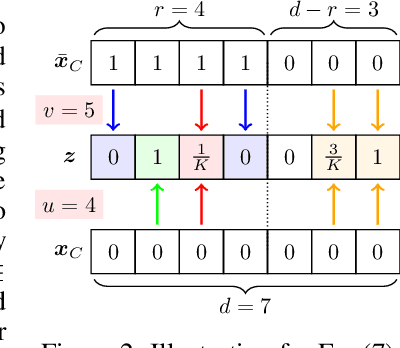

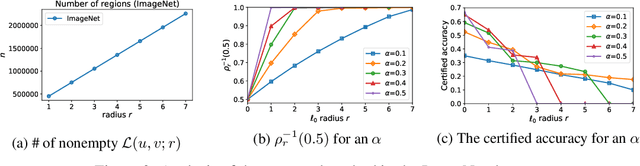
Strong theoretical guarantees of robustness can be given for ensembles of classifiers generated by input randomization. Specifically, an $\ell_2$ bounded adversary cannot alter the ensemble prediction generated by an isotropic Gaussian perturbation, where the radius for the adversary depends on both the variance of the perturbation as well as the ensemble margin at the point of interest. We build on and considerably expand this work across broad classes of perturbations. In particular, we offer guarantees and develop algorithms for the discrete case where the adversary is $\ell_0$ bounded. Moreover, we exemplify how the guarantees can be tightened with specific assumptions about the function class of the classifier such as a decision tree. We empirically illustrate these results with and without functional restrictions across image and molecule datasets.
Functional Transparency for Structured Data: a Game-Theoretic Approach
Feb 26, 2019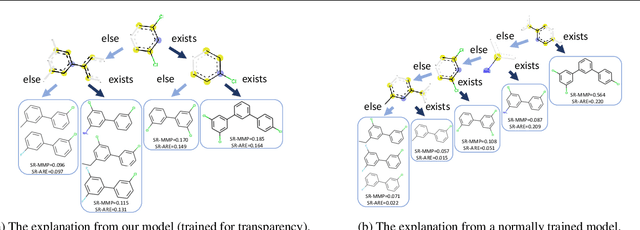
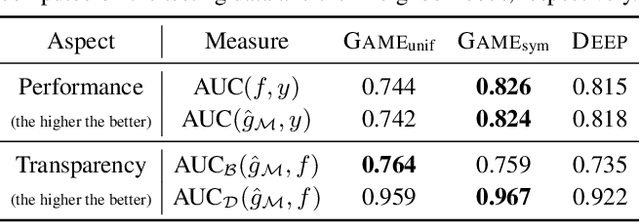
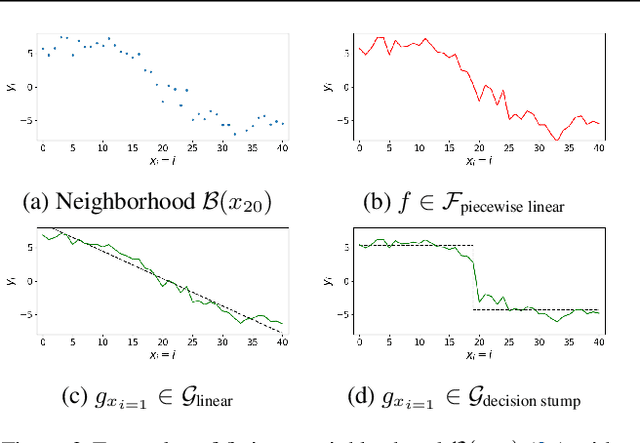

We provide a new approach to training neural models to exhibit transparency in a well-defined, functional manner. Our approach naturally operates over structured data and tailors the predictor, functionally, towards a chosen family of (local) witnesses. The estimation problem is setup as a co-operative game between an unrestricted predictor such as a neural network, and a set of witnesses chosen from the desired transparent family. The goal of the witnesses is to highlight, locally, how well the predictor conforms to the chosen family of functions, while the predictor is trained to minimize the highlighted discrepancy. We emphasize that the predictor remains globally powerful as it is only encouraged to agree locally with locally adapted witnesses. We analyze the effect of the proposed approach, provide example formulations in the context of deep graph and sequence models, and empirically illustrate the idea in chemical property prediction, temporal modeling, and molecule representation learning.
Game-Theoretic Interpretability for Temporal Modeling
Jun 30, 2018
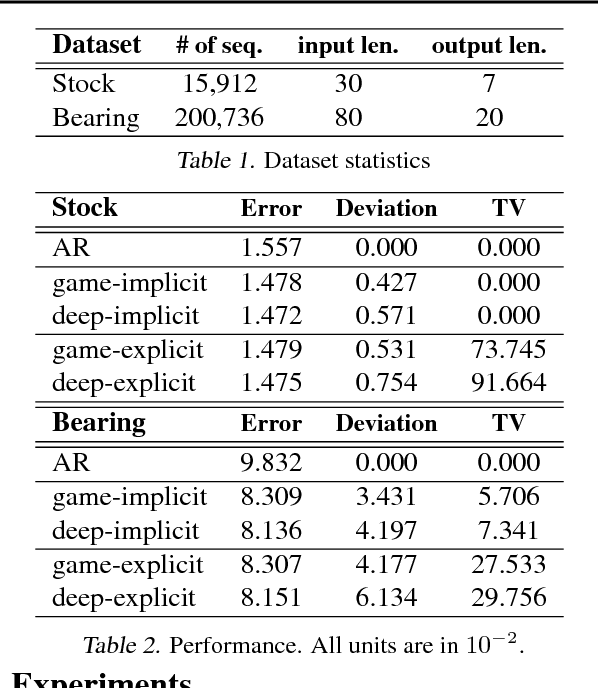
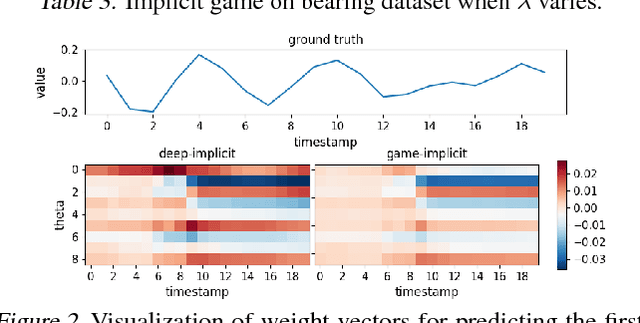
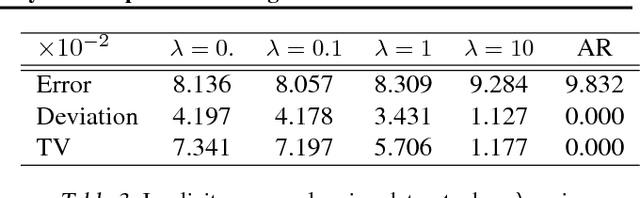
Interpretability has arisen as a key desideratum of machine learning models alongside performance. Approaches so far have been primarily concerned with fixed dimensional inputs emphasizing feature relevance or selection. In contrast, we focus on temporal modeling and the problem of tailoring the predictor, functionally, towards an interpretable family. To this end, we propose a co-operative game between the predictor and an explainer without any a priori restrictions on the functional class of the predictor. The goal of the explainer is to highlight, locally, how well the predictor conforms to the chosen interpretable family of temporal models. Our co-operative game is setup asymmetrically in terms of information sets for efficiency reasons. We develop and illustrate the framework in the context of temporal sequence models with examples.
Toward Implicit Sample Noise Modeling: Deviation-driven Matrix Factorization
Oct 28, 2016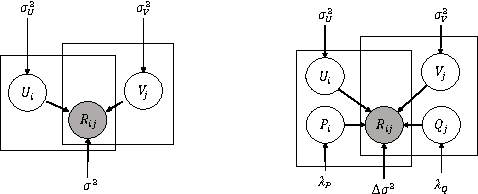
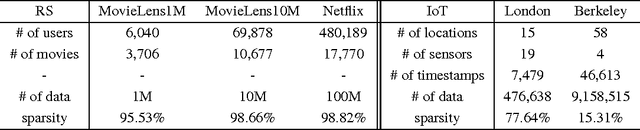

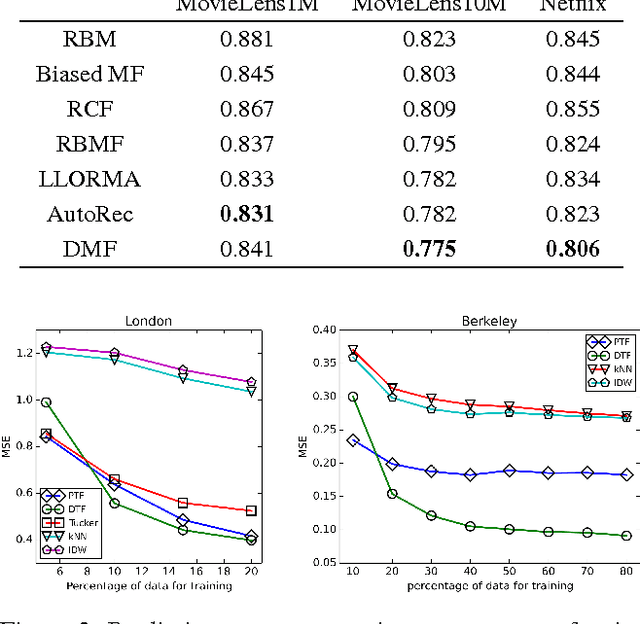
The objective function of a matrix factorization model usually aims to minimize the average of a regression error contributed by each element. However, given the existence of stochastic noises, the implicit deviations of sample data from their true values are almost surely diverse, which makes each data point not equally suitable for fitting a model. In this case, simply averaging the cost among data in the objective function is not ideal. Intuitively we would like to emphasize more on the reliable instances (i.e., those contain smaller noise) while training a model. Motivated by such observation, we derive our formula from a theoretical framework for optimal weighting under heteroscedastic noise distribution. Specifically, by modeling and learning the deviation of data, we design a novel matrix factorization model. Our model has two advantages. First, it jointly learns the deviation and conducts dynamic reweighting of instances, allowing the model to converge to a better solution. Second, during learning the deviated instances are assigned lower weights, which leads to faster convergence since the model does not need to overfit the noise. The experiments are conducted in clean recommendation and noisy sensor datasets to test the effectiveness of the model in various scenarios. The results show that our model outperforms the state-of-the-art factorization and deep learning models in both accuracy and efficiency.